UrbanGraphEmbeddings: Learning and Evaluating Spatially Grounded Multimodal Embeddings for Urban Science
作者: Jie Zhang, Xingtong Yu, Yuan Fang, Rudi Stouffs, Zdravko Trivic
分类: cs.CV, cs.AI
发布日期: 2026-02-09
💡 一句话要点
提出UGE,通过空间图嵌入提升城市环境多模态表征学习
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 城市理解 多模态嵌入 空间图 街景图像 对比学习 图神经网络 地理位置排序
📋 核心要点
- 现有城市理解方法缺乏街景图像与城市空间结构的显式对齐,限制了模型对空间关系的理解能力。
- UGE通过构建空间接地的UGData数据集,并采用两阶段训练策略,显式地对齐图像、文本和空间结构。
- 实验表明,UGE在图像检索和地理位置排序等任务上显著优于现有方法,尤其是在未见过的城市中表现更佳。
📝 摘要(中文)
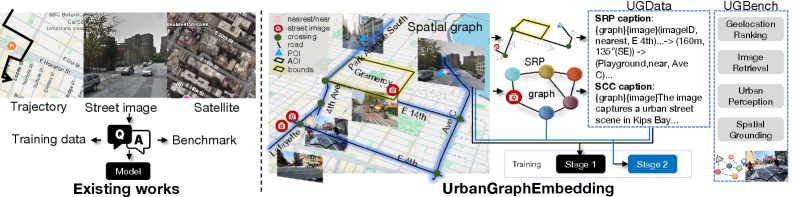
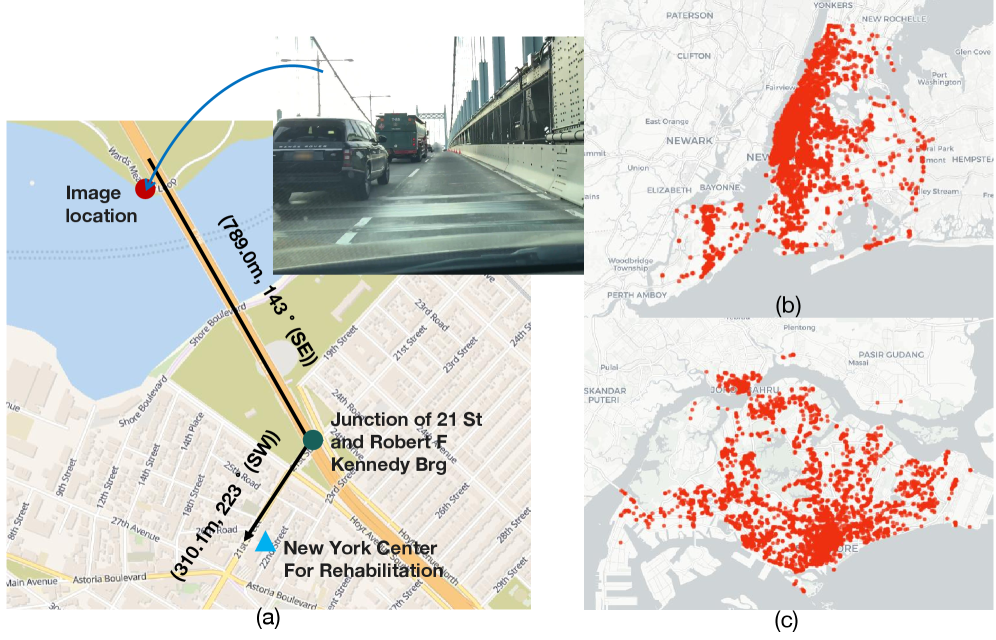
城市环境可迁移的多模态嵌入学习极具挑战,因为城市理解本质上是空间性的,但现有数据集和基准缺乏街景图像与城市结构之间的显式对齐。本文提出了UGData,一个空间接地的数据集,它将街景图像锚定到结构化的空间图,并通过空间推理路径和空间上下文描述提供图对齐的监督,从而揭示了图像内容之外的距离、方向性、连通性和邻域上下文。基于UGData,本文提出UGE,一种两阶段训练策略,通过结合指令引导的对比学习和基于图的空间编码,逐步且稳定地对齐图像、文本和空间结构。最后,本文引入UGBench,一个全面的基准,用于评估空间接地的嵌入如何支持各种城市理解任务,包括地理位置排序、图像检索、城市感知和空间接地。UGE在多个最先进的VLM骨干网络(包括Qwen2-VL、Qwen2.5-VL、Phi-3-Vision和LLaVA1.6-Mistral)上开发,并使用LoRA微调训练固定维度的空间嵌入。基于Qwen2.5-VL-7B骨干的UGE在训练城市中的图像检索方面实现了高达44%的改进,在地理位置排序方面实现了30%的改进,在保留城市中分别实现了超过30%和22%的收益,证明了显式空间接地对于空间密集型城市任务的有效性。
🔬 方法详解
问题定义:现有方法在城市理解任务中,难以有效利用街景图像与城市空间结构之间的关系。缺乏显式对齐导致模型无法充分理解城市环境的空间特性,例如距离、方向和连通性,从而影响了模型在地理定位、图像检索等任务中的性能。
核心思路:UGE的核心思路是通过构建空间接地的多模态嵌入,显式地将街景图像、文本描述和城市空间结构对齐。通过这种方式,模型可以学习到更丰富的空间上下文信息,从而提升对城市环境的理解能力。
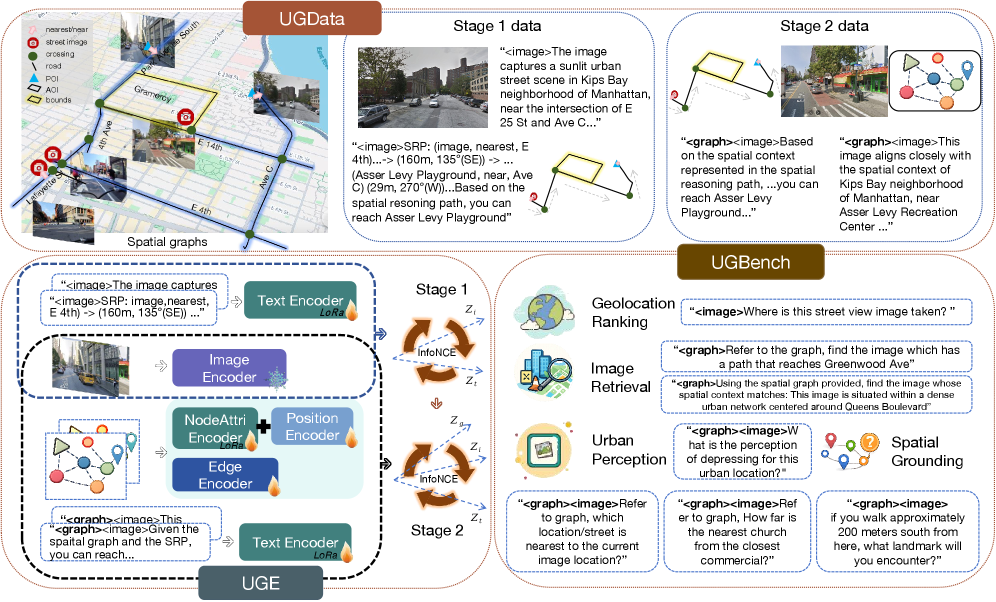
技术框架:UGE包含两个主要阶段:1) 数据构建阶段:构建UGData数据集,将街景图像锚定到空间图,并提供空间推理路径和空间上下文描述作为监督信号。2) 模型训练阶段:采用两阶段训练策略,首先使用指令引导的对比学习对齐图像和文本,然后使用基于图的空间编码对齐空间结构。
关键创新:UGE的关键创新在于显式地将空间信息融入到多模态嵌入学习中。通过构建空间图和利用空间推理路径,UGE能够让模型学习到图像内容之外的空间关系,从而提升模型对城市环境的理解能力。
关键设计:UGData数据集包含街景图像、空间图、空间推理路径和空间上下文描述。两阶段训练策略包括:1) 指令引导的对比学习,使用对比损失函数对齐图像和文本嵌入。2) 基于图的空间编码,使用图神经网络学习空间嵌入,并将其与图像和文本嵌入对齐。使用LoRA微调固定维度的空间嵌入。
🖼️ 关键图片
📊 实验亮点
UGE在UGBench基准测试中表现出色。基于Qwen2.5-VL-7B骨干的UGE在训练城市中的图像检索方面实现了高达44%的改进,在地理位置排序方面实现了30%的改进。更重要的是,在未见过的城市中,UGE仍然实现了超过30%和22%的收益,表明其具有良好的泛化能力。
🎯 应用场景
该研究成果可应用于城市规划、智能交通、位置服务、增强现实等领域。例如,可以利用该模型进行更精确的地理位置预测、更智能的图像检索,以及更真实的城市环境模拟。未来,该技术有望为智慧城市建设提供更强大的技术支持。
📄 摘要(原文)
Learning transferable multimodal embeddings for urban environments is challenging because urban understanding is inherently spatial, yet existing datasets and benchmarks lack explicit alignment between street-view images and urban structure. We introduce UGData, a spatially grounded dataset that anchors street-view images to structured spatial graphs and provides graph-aligned supervision via spatial reasoning paths and spatial context captions, exposing distance, directionality, connectivity, and neighborhood context beyond image content. Building on UGData, we propose UGE, a two-stage training strategy that progressively and stably aligns images, text, and spatial structures by combining instruction-guided contrastive learning with graph-based spatial encoding. We finally introduce UGBench, a comprehensive benchmark to evaluate how spatially grounded embeddings support diverse urban understanding tasks -- including geolocation ranking, image retrieval, urban perception, and spatial grounding. We develop UGE on multiple state-of-the-art VLM backbones, including Qwen2-VL, Qwen2.5-VL, Phi-3-Vision, and LLaVA1.6-Mistral, and train fixed-dimensional spatial embeddings with LoRA tuning. UGE built upon Qwen2.5-VL-7B backbone achieves up to 44% improvement in image retrieval and 30% in geolocation ranking on training cities, and over 30% and 22% gains respectively on held-out cities, demonstrating the effectiveness of explicit spatial grounding for spatially intensive urban tasks.