Language-Guided Transformer Tokenizer for Human Motion Generation
作者: Sheng Yan, Yong Wang, Xin Du, Junsong Yuan, Mengyuan Liu
分类: cs.CV
发布日期: 2026-02-09
💡 一句话要点
提出语言引导的Transformer Tokenizer用于高效的人体动作生成
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 人体动作生成 语言引导 Transformer Token化 动作表示
📋 核心要点
- 现有动作Token化方法在提高重建质量时,通常增加Token数量,导致生成模型学习难度增加。
- 论文提出语言引导的Token化方法(LG-Tok),利用语言信息在Token化阶段对齐动作,生成紧凑的语义表示。
- 实验结果表明,LG-Tok在HumanML3D和Motion-X数据集上优于现有方法,且使用更少的Token也能保持竞争力。
📝 摘要(中文)
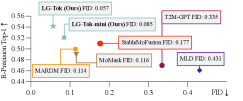
本文关注于动作离散Token化,该过程将原始动作转换为紧凑的离散Token,这对于高效的动作生成至关重要。增加Token数量是提高动作重建质量的常用方法,但更多的Token会增加生成模型的学习难度。为了在保持高重建质量的同时降低生成复杂度,我们提出利用语言来实现高效的动作Token化,称之为语言引导Token化(LG-Tok)。LG-Tok在Token化阶段将自然语言与动作对齐,产生紧凑、高层次的语义表示。这种方法不仅加强了Token化和反Token化,还简化了生成模型的学习。此外,现有的Tokenizer主要采用卷积架构,其局部感受野难以支持全局语言引导。为此,我们提出了一种基于Transformer的Tokenizer,它利用注意力机制来实现语言和动作之间的有效对齐。此外,我们设计了一种语言丢弃方案,在训练期间随机移除语言条件,使反Token化器能够在生成期间支持无语言引导。在HumanML3D和Motion-X生成基准测试中,LG-Tok分别实现了0.542和0.582的Top-1分数,优于最先进的方法(MARDM:0.500和0.528),FID分数分别为0.057和0.088,而MARDM分别为0.114和0.147。LG-Tok-mini仅使用一半的Token,同时保持了有竞争力的性能(Top-1:0.521/0.588,FID:0.085/0.071),验证了我们语义表示的效率。
🔬 方法详解
问题定义:现有动作生成方法依赖于将原始动作数据转换为离散的Token。为了提高动作重建质量,通常增加Token的数量,但这会显著增加生成模型的学习难度和计算复杂度。因此,如何在保证重建质量的同时,降低生成模型的学习难度是一个关键问题。
核心思路:论文的核心思路是利用自然语言的语义信息来引导动作Token化过程。通过将语言信息与动作数据对齐,可以生成更具语义信息的Token表示,从而减少Token的数量,降低生成模型的学习难度。这种方法旨在在Token化阶段就融入高层次的语义信息,从而简化后续的生成过程。
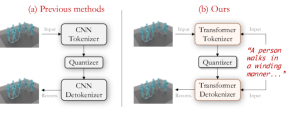
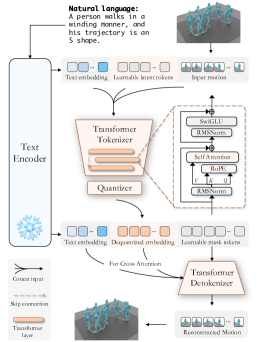
技术框架:整体框架包含三个主要部分:语言编码器、Transformer-based Tokenizer和Detokenizer。首先,语言编码器将输入的自然语言描述转换为语言嵌入。然后,Transformer-based Tokenizer接收原始动作数据和语言嵌入,利用注意力机制将两者对齐,生成离散的动作Token。最后,Detokenizer将动作Token转换回连续的动作序列。在训练过程中,还引入了语言丢弃方案,以提高Detokenizer的鲁棒性。
关键创新:论文的关键创新在于提出了语言引导的Transformer Tokenizer(LG-Tok)。与传统的基于卷积的Tokenizer相比,LG-Tok利用Transformer的全局注意力机制,能够更好地捕捉语言和动作之间的长程依赖关系,从而生成更具语义信息的Token表示。此外,语言丢弃方案也是一个创新点,它使得Detokenizer在没有语言引导的情况下也能生成合理的动作序列。
关键设计:Transformer-based Tokenizer使用多层Transformer编码器,其中每一层都包含自注意力机制和前馈神经网络。语言嵌入被注入到Transformer的每一层,以引导动作Token化过程。语言丢弃方案通过在训练期间随机将语言嵌入设置为零来实现。损失函数包括重建损失和Token化损失,用于优化Token化和Detokenization过程。
🖼️ 关键图片
📊 实验亮点
LG-Tok在HumanML3D和Motion-X数据集上取得了显著的性能提升。在HumanML3D上,LG-Tok的Top-1分数为0.542,FID分数为0.057,优于MARDM的0.500和0.114。在Motion-X上,LG-Tok的Top-1分数为0.582,FID分数为0.088,优于MARDM的0.528和0.147。更重要的是,LG-Tok-mini仅使用一半的Token,仍然保持了具有竞争力的性能,验证了该方法的效率。
🎯 应用场景
该研究成果可应用于虚拟现实、游戏开发、动画制作等领域,实现更自然、更智能的人机交互。例如,用户可以通过自然语言描述来生成特定的人物动作,从而简化动画制作流程,提高开发效率。此外,该技术还可以用于康复训练,根据患者的语言描述生成相应的康复动作指导。
📄 摘要(原文)
In this paper, we focus on motion discrete tokenization, which converts raw motion into compact discrete tokens--a process proven crucial for efficient motion generation. In this paradigm, increasing the number of tokens is a common approach to improving motion reconstruction quality, but more tokens make it more difficult for generative models to learn. To maintain high reconstruction quality while reducing generation complexity, we propose leveraging language to achieve efficient motion tokenization, which we term Language-Guided Tokenization (LG-Tok). LG-Tok aligns natural language with motion at the tokenization stage, yielding compact, high-level semantic representations. This approach not only strengthens both tokenization and detokenization but also simplifies the learning of generative models. Furthermore, existing tokenizers predominantly adopt convolutional architectures, whose local receptive fields struggle to support global language guidance. To this end, we propose a Transformer-based Tokenizer that leverages attention mechanisms to enable effective alignment between language and motion. Additionally, we design a language-drop scheme, in which language conditions are randomly removed during training, enabling the detokenizer to support language-free guidance during generation. On the HumanML3D and Motion-X generation benchmarks, LG-Tok achieves Top-1 scores of 0.542 and 0.582, outperforming state-of-the-art methods (MARDM: 0.500 and 0.528), and with FID scores of 0.057 and 0.088, respectively, versus 0.114 and 0.147. LG-Tok-mini uses only half the tokens while maintaining competitive performance (Top-1: 0.521/0.588, FID: 0.085/0.071), validating the efficiency of our semantic representations.