Tighnari v2: Mitigating Label Noise and Distribution Shift in Multimodal Plant Distribution Prediction via Mixture of Experts and Weakly Supervised Learning
作者: Haixu Liu, Yufei Wang, Tianxiang Xu, Chuancheng Shi, Hongsheng Xing
分类: cs.CV, cs.AI
发布日期: 2026-02-09
💡 一句话要点
Tighnari v2:通过混合专家模型和弱监督学习缓解多模态植物分布预测中的标签噪声和分布偏移
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 植物分布预测 多模态融合 标签噪声 分布偏移 混合专家模型 弱监督学习 遥感影像
📋 核心要点
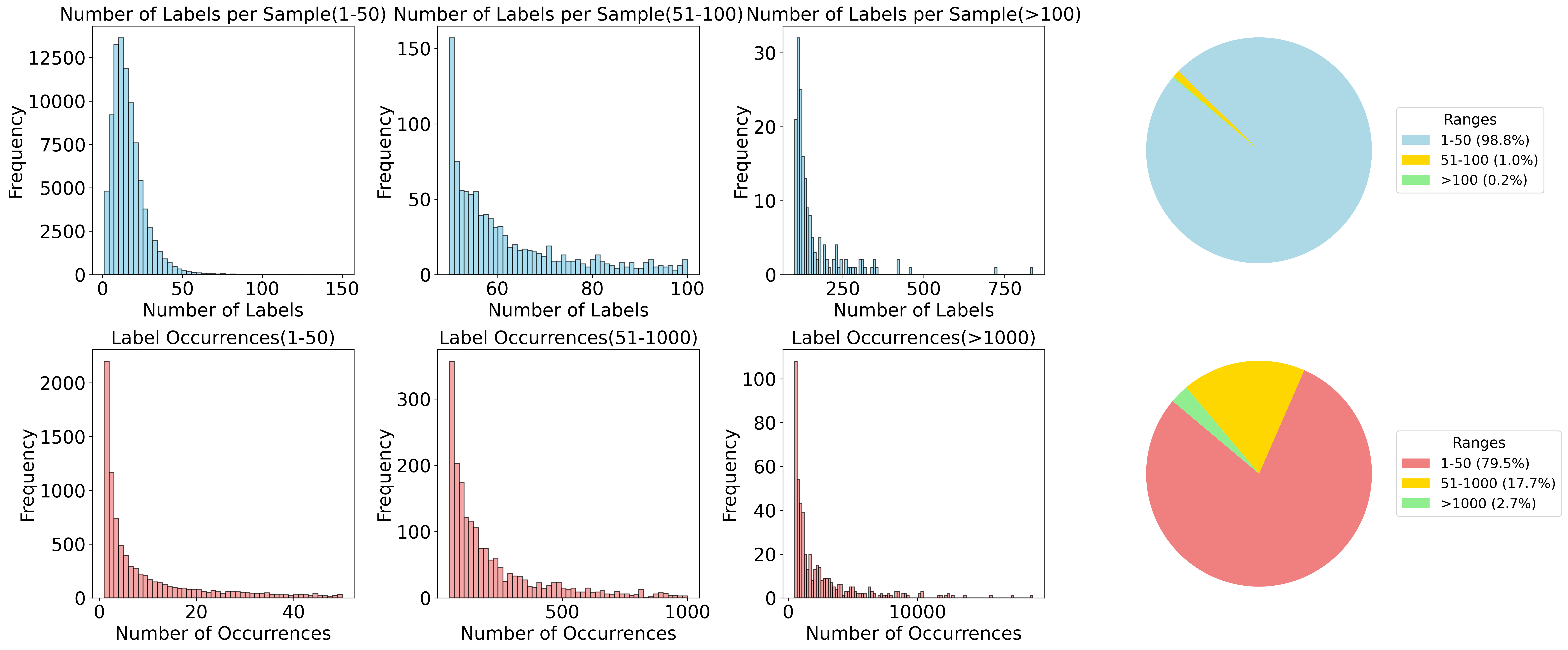
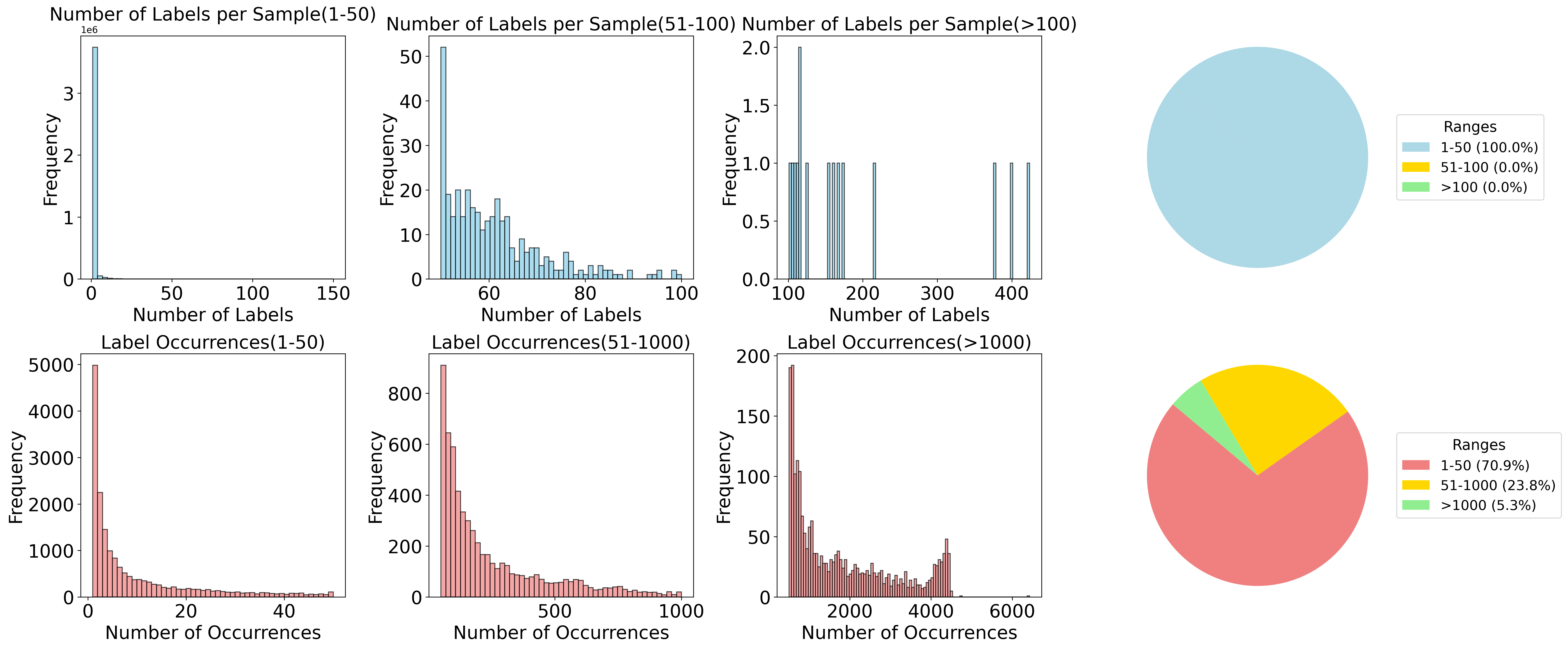
- 现有植物分布预测方法受限于观测数据的稀疏性和偏差,特别是存在-不存在(PA)数据量少且存在-仅存在(PO)数据噪声大。
- 提出一种多模态融合框架,利用伪标签聚合策略对齐PO数据,并采用混合专家模型处理PA数据和测试样本的分布偏移。
- 在GeoLifeCLEF 2025数据集上,该方法在PA覆盖有限和分布偏移显著的情况下,实现了优越的预测性能。
📝 摘要(中文)
大规模、跨物种的植物分布预测在生物多样性保护中起着关键作用,但该领域的研究工作仍然面临着观测数据的稀疏性和偏差等重大挑战。存在-不存在(PA)数据提供准确且无噪声的标签,但获取成本高昂且数量有限;相比之下,仅存在(PO)数据提供广泛的空间覆盖和丰富的时空分布,但负样本存在严重的标签噪声。为了解决这些现实约束,本文提出了一个多模态融合框架,充分利用PA和PO数据的优势。我们为PO数据引入了一种基于卫星图像地理覆盖范围的创新伪标签聚合策略,从而实现标签空间和遥感特征空间之间的地理对齐。在模型架构方面,我们采用Swin Transformer Base作为卫星图像的骨干网络,利用TabM网络进行表格特征提取,保留Temporal Swin Transformer进行时间序列建模,并采用可堆叠的串行三模态交叉注意力机制来优化异构模态的融合。此外,经验分析表明PA训练和测试样本之间存在显著的地理分布偏移,并且直接混合PO和PA数据训练的模型由于PO数据中的标签噪声而容易出现性能下降。为了解决这个问题,我们借鉴了混合专家模型的范例:测试样本根据其与PA样本的空间邻近性进行划分,并且在每个分区中使用在不同数据集上训练的不同模型进行推理和后处理。在GeoLifeCLEF 2025数据集上的实验表明,我们的方法在PA覆盖范围有限且分布偏移明显的场景中实现了卓越的预测性能。
🔬 方法详解
问题定义:植物分布预测任务面临PA数据稀缺和PO数据噪声大的问题。直接混合两种数据训练模型会导致性能下降,尤其是在训练集和测试集存在地理分布偏移时。现有方法难以有效利用两种数据源,并对分布偏移具有较强的鲁棒性。
核心思路:利用PO数据进行弱监督学习,通过伪标签聚合策略减少标签噪声,并采用混合专家模型,根据测试样本与PA数据的空间关系,选择不同的模型进行预测,从而缓解分布偏移带来的影响。
技术框架:整体框架包含数据预处理、特征提取、多模态融合和混合专家模型四个主要阶段。数据预处理阶段对PA和PO数据进行清洗和格式化。特征提取阶段使用Swin Transformer Base提取卫星图像特征,TabM网络提取表格特征,Temporal Swin Transformer提取时间序列特征。多模态融合阶段采用串行三模态交叉注意力机制融合异构特征。混合专家模型阶段根据样本与PA数据的空间距离选择专家模型进行预测。
关键创新:主要创新点在于伪标签聚合策略和混合专家模型的使用。伪标签聚合策略通过地理覆盖范围对PO数据进行加权,减少了标签噪声。混合专家模型根据样本的空间位置选择合适的模型,有效缓解了分布偏移问题。
关键设计:伪标签聚合策略基于卫星图像的地理覆盖范围,为每个PO样本分配一个伪标签,该标签是周围PA样本的加权平均值。混合专家模型将测试样本划分为多个区域,每个区域对应一个专家模型,该模型在特定数据集上训练,并针对该区域进行优化。
🖼️ 关键图片
📊 实验亮点
该方法在GeoLifeCLEF 2025数据集上取得了显著的性能提升,尤其是在PA数据覆盖有限和存在显著分布偏移的情况下。实验结果表明,该方法能够有效缓解标签噪声和分布偏移带来的负面影响,提高了植物分布预测的准确性和鲁棒性。
🎯 应用场景
该研究成果可应用于生物多样性保护、生态环境监测、农业生产规划等领域。通过更准确地预测植物分布,可以更好地制定保护策略,评估环境变化的影响,并优化农业生产布局,具有重要的实际应用价值和潜在的社会经济效益。
📄 摘要(原文)
Large-scale, cross-species plant distribution prediction plays a crucial role in biodiversity conservation, yet modeling efforts in this area still face significant challenges due to the sparsity and bias of observational data. Presence-Absence (PA) data provide accurate and noise-free labels, but are costly to obtain and limited in quantity; Presence-Only (PO) data, by contrast, offer broad spatial coverage and rich spatiotemporal distribution, but suffer from severe label noise in negative samples. To address these real-world constraints, this paper proposes a multimodal fusion framework that fully leverages the strengths of both PA and PO data. We introduce an innovative pseudo-label aggregation strategy for PO data based on the geographic coverage of satellite imagery, enabling geographic alignment between the label space and remote sensing feature space. In terms of model architecture, we adopt Swin Transformer Base as the backbone for satellite imagery, utilize the TabM network for tabular feature extraction, retain the Temporal Swin Transformer for time-series modeling, and employ a stackable serial tri-modal cross-attention mechanism to optimize the fusion of heterogeneous modalities. Furthermore, empirical analysis reveals significant geographic distribution shifts between PA training and test samples, and models trained by directly mixing PO and PA data tend to experience performance degradation due to label noise in PO data. To address this, we draw on the mixture-of-experts paradigm: test samples are partitioned according to their spatial proximity to PA samples, and different models trained on distinct datasets are used for inference and post-processing within each partition. Experiments on the GeoLifeCLEF 2025 dataset demonstrate that our approach achieves superior predictive performance in scenarios with limited PA coverage and pronounced distribution shifts.