A Unified Framework for Multimodal Image Reconstruction and Synthesis using Denoising Diffusion Models
作者: Weijie Gan, Xucheng Wang, Tongyao Wang, Wenshang Wang, Chunwei Ying, Yuyang Hu, Yasheng Chen, Hongyu An, Ulugbek S. Kamilov
分类: eess.IV, cs.CV
发布日期: 2026-02-09
💡 一句话要点
Any2all:基于去噪扩散模型的统一多模态图像重建与合成框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态图像重建 多模态图像合成 去噪扩散模型 图像修复 医学影像
📋 核心要点
- 现有多模态图像重建与合成方法依赖于特定任务的模型,训练和部署流程繁琐。
- Any2all将多模态重建与合成统一为图像修复问题,利用单一扩散模型处理多种任务。
- 实验表明,Any2all在PET/MR/CT脑部数据集上表现出色,感知质量优于专用方法。
📝 摘要(中文)
本文提出Any2all,一个统一的框架,旨在解决多模态成像数据不完整的问题。现有方法通常需要针对不同任务训练特定的模型,导致训练和部署流程复杂。Any2all将这些不同的任务统一建模为一个虚拟的图像修复问题。该方法在完整的多模态数据堆栈上训练一个单一的、无条件的扩散模型。在推理阶段,该模型能够根据任意组合的可用清晰图像或噪声测量结果“修复”所有目标模态。在PET/MR/CT脑部数据集上的验证结果表明,Any2all在多模态重建和合成任务上均能取得优异的性能,始终如一地产生具有竞争力的基于失真的性能和优于专用方法的感知质量的图像。
🔬 方法详解
问题定义:论文旨在解决多模态图像重建和合成问题,即如何利用不完整的多模态数据(例如,只有部分模态的图像可用,或者某些模态的图像存在噪声)来重建或合成完整的多模态图像。现有方法的痛点在于需要为每种模态组合或任务训练单独的模型,导致模型数量庞大,训练和部署成本高昂。
核心思路:Any2all的核心思路是将所有多模态重建和合成任务统一建模为一个虚拟的图像修复(inpainting)问题。具体来说,无论输入是哪些模态的图像,或者输入图像中存在多少噪声,都将其视为需要修复的图像区域。通过这种方式,可以使用一个统一的模型来处理各种不同的多模态重建和合成任务。
技术框架:Any2all的整体框架包括两个主要阶段:训练阶段和推理阶段。在训练阶段,使用完整的多模态数据训练一个无条件的去噪扩散模型(Denoising Diffusion Model)。该模型学习从噪声中生成高质量的多模态图像。在推理阶段,根据可用的输入模态和噪声水平,对扩散模型的采样过程进行调整,以实现多模态图像的重建和合成。具体来说,通过将已知的输入模态作为条件,引导扩散模型生成与输入一致的图像。
关键创新:Any2all最重要的技术创新点在于其统一的建模方式。与以往需要为每种模态组合或任务训练单独模型的方法不同,Any2all只需要训练一个单一的扩散模型,即可处理各种不同的多模态重建和合成任务。这种统一的建模方式大大简化了训练和部署流程,并提高了模型的泛化能力。
关键设计:Any2all的关键设计包括:1) 使用无条件的扩散模型作为基础模型,使其能够学习到多模态数据的整体分布;2) 在推理阶段,通过将已知的输入模态作为条件,引导扩散模型的采样过程,以实现多模态图像的重建和合成;3) 使用标准的扩散模型训练和采样技术,例如DDPM或DDIM,以保证模型的性能和效率。论文中没有明确提及具体的参数设置、损失函数和网络结构等细节,这些可能使用了标准的扩散模型配置。
🖼️ 关键图片

📊 实验亮点
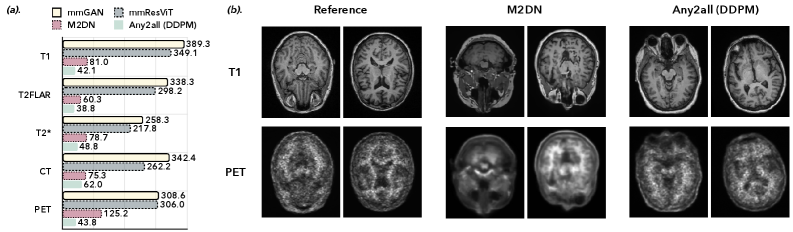
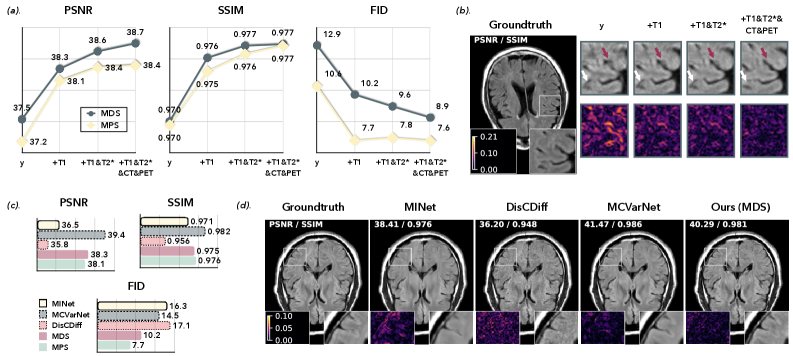
Any2all在PET/MR/CT脑部数据集上进行了验证,实验结果表明,该方法在多模态重建和合成任务上均能取得优异的性能,始终如一地产生具有竞争力的基于失真的性能,并且感知质量优于专用方法。这表明Any2all具有很强的实用价值。
🎯 应用场景
Any2all在医学影像领域具有广泛的应用前景,例如,可以用于PET/MR/CT等多种模态的图像重建和合成,帮助医生更全面地了解患者的病情。此外,该方法还可以应用于遥感图像处理、视频修复等领域,具有重要的实际价值和未来影响。
📄 摘要(原文)
Image reconstruction and image synthesis are important for handling incomplete multimodal imaging data, but existing methods require various task-specific models, complicating training and deployment workflows. We introduce Any2all, a unified framework that addresses this limitation by formulating these disparate tasks as a single virtual inpainting problem. We train a single, unconditional diffusion model on the complete multimodal data stack. This model is then adapted at inference time to ``inpaint'' all target modalities from any combination of inputs of available clean images or noisy measurements. We validated Any2all on a PET/MR/CT brain dataset. Our results show that Any2all can achieve excellent performance on both multimodal reconstruction and synthesis tasks, consistently yielding images with competitive distortion-based performance and superior perceptual quality over specialized methods.