When and How Much to Imagine: Adaptive Test-Time Scaling with World Models for Visual Spatial Reasoning
作者: Shoubin Yu, Yue Zhang, Zun Wang, Jaehong Yoon, Huaxiu Yao, Mingyu Ding, Mohit Bansal
分类: cs.CV, cs.AI, cs.CL
发布日期: 2026-02-09
备注: the first two authors are equally contributed. Project page: https://adaptive-visual-tts.github.io/
💡 一句话要点
AVIC:基于世界模型的自适应测试时缩放框架,提升视觉空间推理效率与可靠性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉空间推理 世界模型 自适应控制 多模态大语言模型 具身导航
📋 核心要点
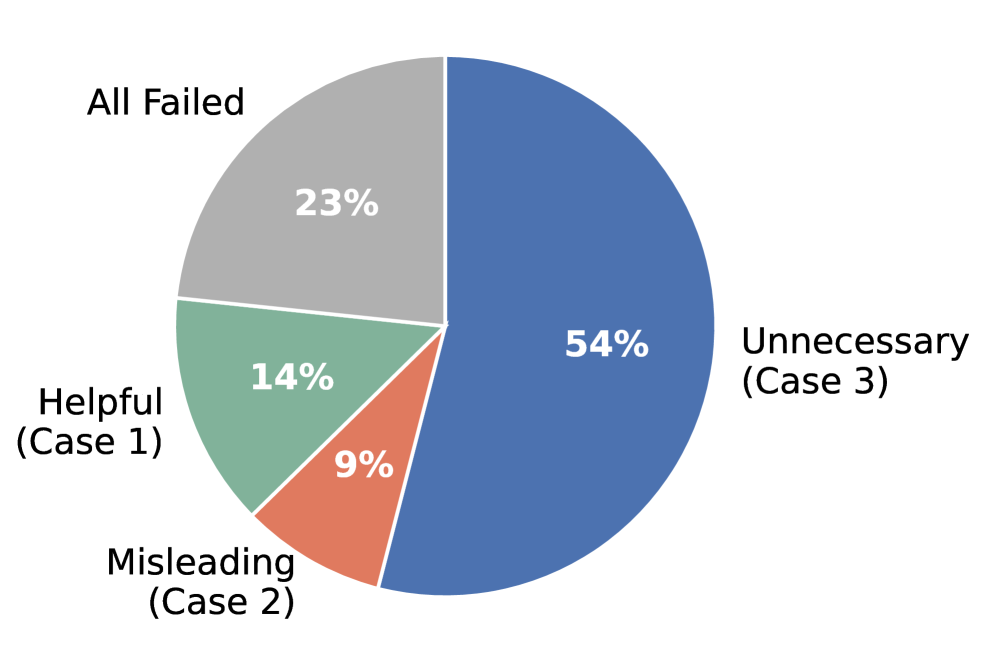
- 多模态大语言模型在视觉空间推理中,面对新视角场景时表现不佳,需要引入世界模型进行视觉想象。
- 论文提出AVIC框架,通过判断当前视觉证据的充分性,自适应地调用和缩放视觉想象,避免不必要的计算和误导。
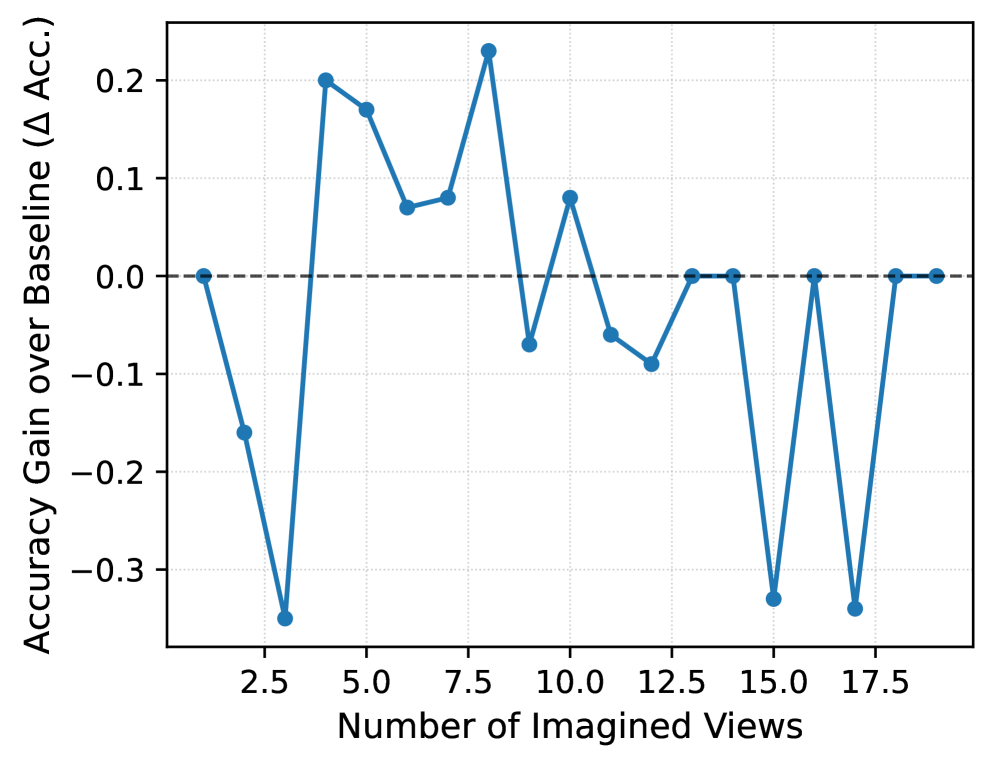
- 实验表明,AVIC在空间推理和具身导航任务中,能以更少的计算资源达到甚至超过固定想象策略的性能。
📝 摘要(中文)
尽管多模态大型语言模型(MLLM)取得了快速进展,但在正确答案取决于场景在未见或替代视角下的外观时,视觉空间推理仍然不可靠。最近的研究通过使用世界模型进行视觉想象来增强推理能力,但诸如何时想象是真正必要的,多少想象是有益的,以及何时它变得有害等问题仍然知之甚少。在实践中,不加区分的想象会增加计算量,甚至通过引入误导性证据来降低性能。本文深入分析了测试时视觉想象作为空间推理的可控资源。我们研究了何时静态视觉证据就足够了,何时想象可以改善推理,以及过度或不必要的想象如何影响准确性和效率。为了支持这项分析,我们提出了AVIC,一个具有世界模型的自适应测试时框架,它在选择性地调用和缩放视觉想象之前,显式地推理当前视觉证据的充分性。在空间推理基准(SAT, MMSI)和具身导航基准(R2R)上,我们的结果揭示了想象至关重要、边缘或有害的明确场景,并表明选择性控制可以匹配或超过固定想象策略,同时显著减少世界模型调用和语言token。总的来说,我们的发现强调了分析和控制测试时想象对于高效和可靠的空间推理的重要性。
🔬 方法详解
问题定义:现有的多模态大语言模型在视觉空间推理任务中,尤其是在需要从新的视角进行推理时,表现出明显的不足。简单地将世界模型引入进行视觉想象,虽然可以提升性能,但会带来额外的计算开销,并且在某些情况下,不必要的想象反而会引入噪声,降低推理的准确性。因此,如何有效地利用世界模型进行视觉想象,避免过度或不足的想象,是一个亟待解决的问题。
核心思路:论文的核心思路是根据当前视觉证据的充分性,自适应地控制视觉想象的程度。具体来说,AVIC框架会首先评估当前视觉信息是否足以支持推理,如果不足,则调用世界模型进行视觉想象,并根据需要调整想象的程度。通过这种方式,AVIC可以在保证推理准确性的同时,最大限度地减少计算开销。
技术框架:AVIC框架主要包含以下几个模块:1) 视觉证据评估模块:该模块负责评估当前视觉信息的充分性,判断是否需要进行视觉想象。评估方法可以是基于置信度、信息熵等指标。2) 世界模型调用模块:如果视觉证据不足,则调用世界模型生成新的视觉信息,模拟从不同视角观察到的场景。3) 视觉想象缩放模块:该模块根据视觉证据的不足程度,调整视觉想象的程度。例如,如果视觉证据非常不足,则进行更充分的想象;反之,则减少想象的程度。4) 推理模块:该模块利用原始视觉信息和生成的视觉信息进行推理,得到最终的答案。
关键创新:AVIC框架的关键创新在于其自适应的视觉想象控制机制。与以往固定程度的视觉想象方法不同,AVIC能够根据当前视觉证据的充分性,动态地调整视觉想象的程度,从而在保证推理准确性的同时,最大限度地减少计算开销。这种自适应控制机制使得AVIC能够更加高效和可靠地进行视觉空间推理。
关键设计:视觉证据评估模块可以使用多种方法,例如,可以训练一个分类器来判断当前视觉信息是否足以支持推理,也可以使用信息熵等指标来衡量视觉信息的不确定性。世界模型可以使用现有的图像生成模型,例如GAN或扩散模型。视觉想象缩放模块可以使用一个线性缩放函数,将视觉证据的不足程度映射到视觉想象的程度。推理模块可以使用现有的多模态大语言模型。
🖼️ 关键图片

📊 实验亮点
实验结果表明,AVIC框架在SAT、MMSI和R2R等空间推理和具身导航基准测试中,能够以更少的计算资源(世界模型调用次数和语言token数量)达到甚至超过固定想象策略的性能。具体来说,AVIC在保持甚至略微提升准确率的同时,显著减少了世界模型的调用次数,从而提高了推理效率。这表明AVIC的自适应视觉想象控制机制是有效的。
🎯 应用场景
该研究成果可广泛应用于机器人导航、自动驾驶、虚拟现实等领域。例如,在机器人导航中,机器人可以利用AVIC框架,根据当前视觉信息,自适应地进行视觉想象,从而更好地理解周围环境,规划最优路径。在自动驾驶中,AVIC可以帮助车辆更好地理解交通场景,预测其他车辆的行驶轨迹,从而提高驾驶安全性。在虚拟现实中,AVIC可以生成更加逼真的虚拟场景,增强用户的沉浸感。
📄 摘要(原文)
Despite rapid progress in Multimodal Large Language Models (MLLMs), visual spatial reasoning remains unreliable when correct answers depend on how a scene would appear under unseen or alternative viewpoints. Recent work addresses this by augmenting reasoning with world models for visual imagination, but questions such as when imagination is actually necessary, how much of it is beneficial, and when it becomes harmful, remain poorly understood. In practice, indiscriminate imagination can increase computation and even degrade performance by introducing misleading evidence. In this work, we present an in-depth analysis of test-time visual imagination as a controllable resource for spatial reasoning. We study when static visual evidence is sufficient, when imagination improves reasoning, and how excessive or unnecessary imagination affects accuracy and efficiency. To support this analysis, we introduce AVIC, an adaptive test-time framework with world models that explicitly reasons about the sufficiency of current visual evidence before selectively invoking and scaling visual imagination. Across spatial reasoning benchmarks (SAT, MMSI) and an embodied navigation benchmark (R2R), our results reveal clear scenarios where imagination is critical, marginal, or detrimental, and show that selective control can match or outperform fixed imagination strategies with substantially fewer world-model calls and language tokens. Overall, our findings highlight the importance of analyzing and controlling test-time imagination for efficient and reliable spatial reasoning.