Evaluating the Impact of Post-Training Quantization on Reliable VQA with Multimodal LLMs
作者: Paul Jonas Kurz, Tobias Jan Wieczorek, Mohamed A. Abdelsalam, Rahaf Aljundi, Marcus Rohrbach
分类: cs.CV, cs.AI
发布日期: 2026-02-08
备注: Accepted poster at the 1st Workshop on Epistemic Intelligence in Machine Learning (EIML) @ EURIPS 2025
💡 一句话要点
研究量化对多模态LLM在VQA任务中可靠性的影响,提出结合选择器置信度估计的优化方案。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉问答 后训练量化 模型压缩 可靠性评估
📋 核心要点
- 多模态大语言模型在实际应用中面临着模型过大和过度自信的问题,需要在效率和可靠性之间取得平衡。
- 论文研究了后训练量化对MLLM在VQA任务中准确性和可靠性的影响,并提出使用选择器置信度估计器来提升可靠性。
- 实验表明,数据感知量化方法能减轻量化带来的负面影响,结合选择器置信度估计器能在降低内存需求的同时保持性能。
📝 摘要(中文)
多模态大型语言模型(MLLM)越来越多地部署在可靠性和效率至关重要的领域。然而,目前的模型仍然过度自信,产生高度确定但不正确的答案。同时,它们的大尺寸限制了在边缘设备上的部署,因此需要压缩。本文研究了后训练量化(PTQ)压缩如何影响视觉问答(VQA)的准确性和可靠性。我们评估了两个MLLM,Qwen2-VL-7B和Idefics3-8B,使用无数据(HQQ)和数据感知(MBQ)方法在多个位宽上进行量化。为了抵消量化导致的可靠性降低,我们为量化的多模态设置调整了选择器置信度估计器,并测试了其在各种量化级别和分布外(OOD)场景中的鲁棒性。我们发现PTQ会降低准确性和可靠性。数据感知方法可以缓解这种影响。选择器可以显著减轻可靠性影响。int4 MBQ和选择器的组合实现了最佳的效率-可靠性权衡,在内存需求减少约75%的情况下,接近未压缩的性能。总的来说,我们提出了第一个系统性研究,将多模态设置中的量化和可靠性联系起来。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLM)在视觉问答(VQA)任务中,由于模型体积庞大难以部署,以及模型过度自信导致答案不可靠的问题。现有方法在压缩模型时,往往忽略了对模型可靠性的影响,导致量化后的模型在准确率下降的同时,可靠性也降低。
核心思路:论文的核心思路是研究后训练量化(PTQ)对MLLM在VQA任务中准确性和可靠性的影响,并提出一种结合选择器置信度估计器的方法来提升量化后模型的可靠性。通过分析不同量化方法和量化级别对模型性能的影响,找到在效率和可靠性之间的最佳平衡点。
技术框架:论文的技术框架主要包括以下几个步骤:1) 选择两个MLLM模型(Qwen2-VL-7B和Idefics3-8B)作为研究对象;2) 使用无数据(HQQ)和数据感知(MBQ)两种后训练量化方法对模型进行量化,并设置不同的位宽;3) 在VQA任务上评估量化后模型的准确率和可靠性;4) 针对量化导致的可靠性下降,引入选择器置信度估计器,并进行调整以适应多模态设置;5) 在不同的量化级别和分布外(OOD)场景下测试选择器的鲁棒性。
关键创新:论文的关键创新在于:1) 系统性地研究了后训练量化对MLLM在VQA任务中可靠性的影响,填补了该领域的研究空白;2) 提出了将选择器置信度估计器应用于量化多模态模型的方案,有效提升了量化后模型的可靠性。与现有方法相比,该方法能够在压缩模型的同时,尽可能地保持模型的可靠性,从而更好地满足实际应用的需求。
关键设计:论文的关键设计包括:1) 选择了两种具有代表性的后训练量化方法(HQQ和MBQ),分别代表无数据和数据感知的量化策略;2) 使用了多个位宽进行量化,以便分析量化级别对模型性能的影响;3) 针对多模态设置,对选择器置信度估计器进行了调整,使其能够更好地评估量化后模型的可靠性;4) 在分布外(OOD)场景下测试了选择器的鲁棒性,以评估其在实际应用中的泛化能力。
🖼️ 关键图片
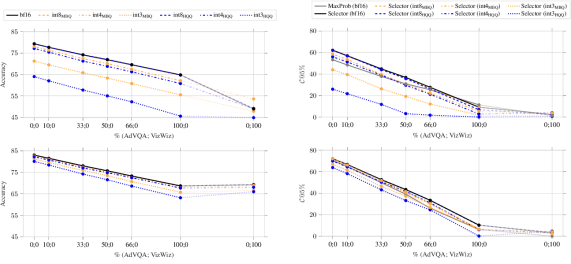
📊 实验亮点
实验结果表明,后训练量化会降低MLLM在VQA任务中的准确性和可靠性。数据感知量化方法(MBQ)能够缓解这种影响。选择器置信度估计器可以显著减轻量化带来的可靠性损失。int4 MBQ和选择器的组合实现了最佳的效率-可靠性权衡,在内存需求减少约75%的情况下,性能接近未压缩模型。
🎯 应用场景
该研究成果可应用于需要高效率和高可靠性的多模态应用场景,例如智能客服、自动驾驶、医疗诊断等。通过对多模态大语言模型进行量化压缩,可以降低模型部署的硬件成本和功耗,使其能够在边缘设备上运行。同时,结合选择器置信度估计器可以提高模型的可靠性,减少错误答案的产生,从而提升用户体验和安全性。
📄 摘要(原文)
Multimodal Large Language Models (MLLM) are increasingly deployed in domains where both reliability and efficiency are critical. However, current models remain overconfident, producing highly certain but incorrect answers. At the same time, their large size limits deployment on edge devices, necessitating compression. We study the intersection of these two challenges by analyzing how Post-Training Quantization (PTQ) compression affects both accuracy and reliability in Visual Question Answering (VQA). We evaluate two MLLMs, Qwen2-VL-7B and Idefics3-8B, quantized with data-free (HQQ) and data-aware (MBQ) methods across multiple bit widths. To counteract the reduction in reliability caused by quantization, we adapt the Selector confidence estimator for quantized multimodal settings and test its robustness across various quantization levels and out-of-distribution (OOD) scenarios. We find that PTQ degrades both accuracy and reliability. Data-aware methods soften the effect thereof. The Selector substantially mitigates the reliability impact. The combination of int4 MBQ and the Selector achieves the best efficiency-reliability trade-off, closing in on uncompressed performance at approx. 75% less memory demand. Overall, we present the first systematic study linking quantization and reliability in multimodal settings.