Multimodal Information Fusion for Chart Understanding: A Survey of MLLMs -- Evolution, Limitations, and Cognitive Enhancement
作者: Zhihang Yi, Jian Zhao, Jiancheng Lv, Tao Wang
分类: cs.CV, cs.AI, cs.CL, cs.LG
发布日期: 2026-02-08
💡 一句话要点
综述MLLM在图表理解中的应用:演进、局限与认知增强
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图表理解 多模态融合 大型语言模型 MLLM 信息抽取
📋 核心要点
- 现有图表理解方法在融合视觉和语言信息方面存在挑战,特别是如何有效提取图表中的深层语义。
- 本文通过综述MLLM在图表理解中的应用,系统地梳理了该领域的核心组件和发展脉络。
- 论文分析了现有模型的局限性,并提出了未来研究方向,包括对齐技术和强化学习等认知增强方法。
📝 摘要(中文)
图表理解是一项典型的信息融合任务,需要无缝集成图形和文本数据以提取意义。多模态大型语言模型(MLLM)的出现彻底改变了这一领域,但基于MLLM的图表分析领域仍然分散且缺乏系统组织。本综述通过构建该领域的核心组成部分,提供了一个全面的发展路线图。首先,分析了图表中融合视觉和语言信息的基本挑战。然后,对下游任务和数据集进行分类,引入了一种规范和非规范基准的新颖分类法,以突出该领域不断扩大的范围。随后,介绍了方法论的全面演变,追溯了从经典深度学习技术到利用复杂融合策略的最先进MLLM范式的进展。通过批判性地检查当前模型的局限性,特别是它们的感知和推理缺陷,确定了有希望的未来方向,包括先进的对齐技术和用于认知增强的强化学习。本综述旨在使研究人员和从业人员能够结构化地理解MLLM如何改变图表信息融合,并促进朝着更强大和可靠的系统发展。
🔬 方法详解
问题定义:图表理解旨在从图表中提取信息和洞察,需要同时处理视觉和文本信息。现有方法在处理复杂图表、进行高级推理以及有效融合多模态信息方面存在局限性。此外,缺乏对MLLM在图表理解中应用的系统性研究和组织。
核心思路:本文的核心思路是对基于MLLM的图表理解领域进行全面综述,分析其演进历程、关键技术和局限性,并展望未来发展方向。通过对现有方法进行分类和比较,为研究人员和从业者提供一个结构化的理解框架。
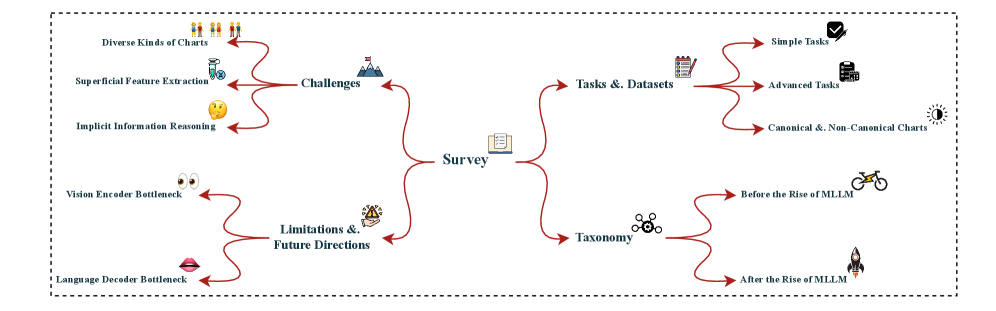
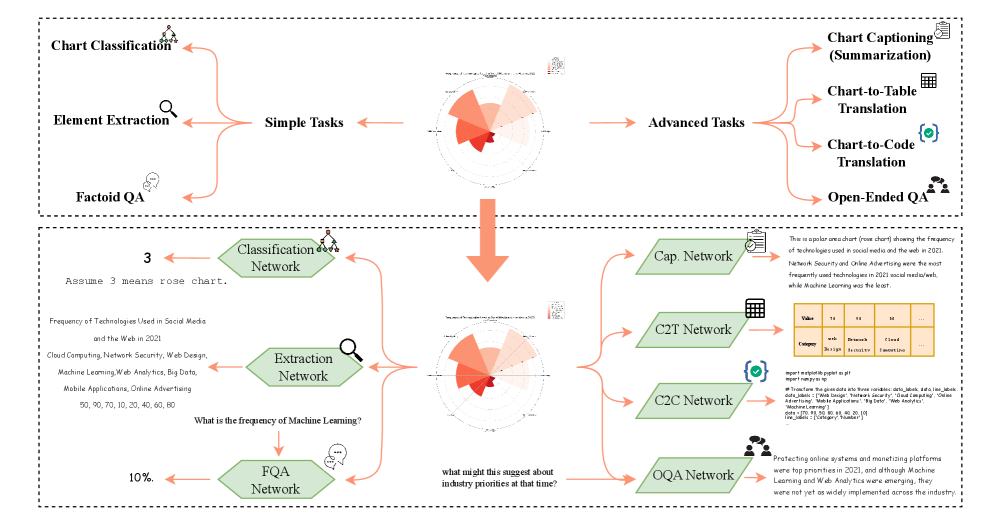
技术框架:本文首先分析了图表理解中的信息融合挑战,然后对下游任务和数据集进行了分类,并提出了规范和非规范基准的新分类法。接着,回顾了从经典深度学习到MLLM的演进过程,重点介绍了各种融合策略。最后,讨论了当前模型的局限性,并提出了未来研究方向。
关键创新:本文的创新之处在于对MLLM在图表理解中的应用进行了系统性的综述和组织,填补了该领域缺乏全面性研究的空白。提出的规范和非规范基准分类法有助于更好地评估和比较不同方法的性能。此外,对未来研究方向的展望为该领域的发展提供了指导。
关键设计:本文主要关注对现有方法的分析和比较,没有提出新的模型或算法。但是,文中讨论了各种融合策略、对齐技术和认知增强方法,这些都是MLLM在图表理解中的关键技术细节。具体参数设置、损失函数和网络结构等细节取决于具体的模型和任务。
🖼️ 关键图片
📊 实验亮点
本文对MLLM在图表理解中的应用进行了全面的综述,涵盖了从经典深度学习到最先进MLLM范式的演进过程。通过分析现有模型的局限性,指出了未来研究方向,例如先进的对齐技术和用于认知增强的强化学习。提出的规范和非规范基准分类法有助于更好地评估和比较不同方法的性能。
🎯 应用场景
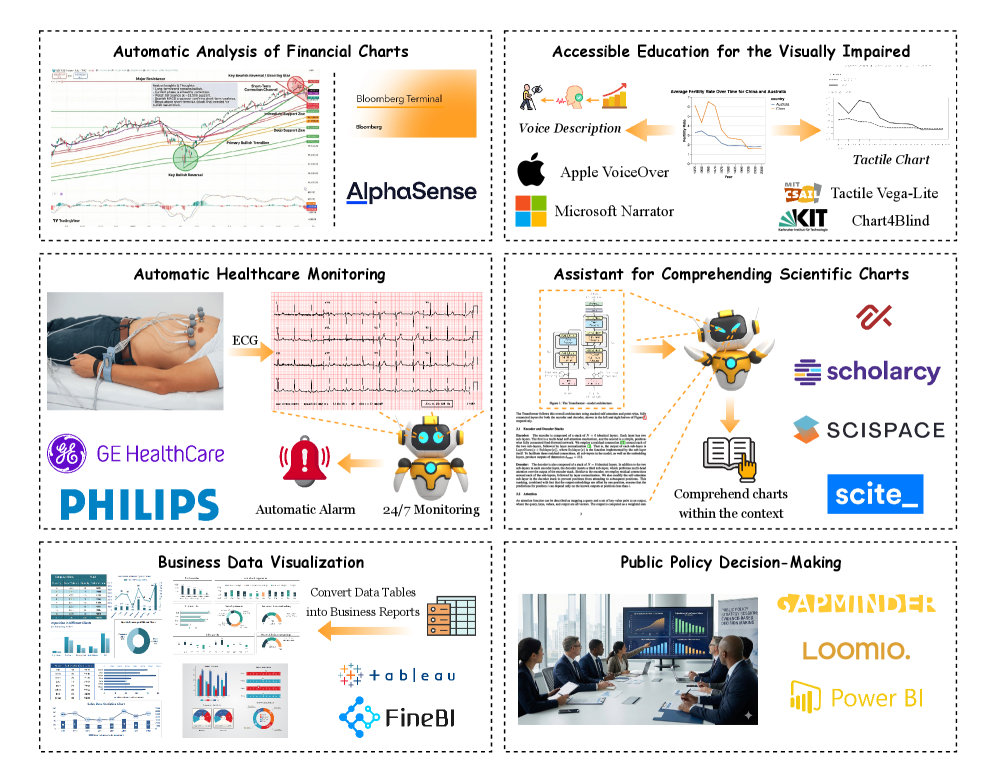
该研究成果可应用于商业智能、数据分析、科学研究等领域,帮助用户更高效地理解和利用图表信息。通过提升图表理解能力,可以辅助决策制定、发现数据模式和趋势,并促进知识的传播和共享。未来,更强大的图表理解系统有望实现自动化报告生成、智能数据可视化等功能。
📄 摘要(原文)
Chart understanding is a quintessential information fusion task, requiring the seamless integration of graphical and textual data to extract meaning. The advent of Multimodal Large Language Models (MLLMs) has revolutionized this domain, yet the landscape of MLLM-based chart analysis remains fragmented and lacks systematic organization. This survey provides a comprehensive roadmap of this nascent frontier by structuring the domain's core components. We begin by analyzing the fundamental challenges of fusing visual and linguistic information in charts. We then categorize downstream tasks and datasets, introducing a novel taxonomy of canonical and non-canonical benchmarks to highlight the field's expanding scope. Subsequently, we present a comprehensive evolution of methodologies, tracing the progression from classic deep learning techniques to state-of-the-art MLLM paradigms that leverage sophisticated fusion strategies. By critically examining the limitations of current models, particularly their perceptual and reasoning deficits, we identify promising future directions, including advanced alignment techniques and reinforcement learning for cognitive enhancement. This survey aims to equip researchers and practitioners with a structured understanding of how MLLMs are transforming chart information fusion and to catalyze progress toward more robust and reliable systems.