MambaFusion: Adaptive State-Space Fusion for Multimodal 3D Object Detection
作者: Venkatraman Narayanan, Bala Sai, Rahul Ahuja, Pratik Likhar, Varun Ravi Kumar, Senthil Yogamani
分类: cs.CV
发布日期: 2026-02-08 (更新: 2026-02-12)
💡 一句话要点
MambaFusion:面向多模态3D目标检测的自适应状态空间融合
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态融合 3D目标检测 状态空间模型 自动驾驶 BEV感知
📋 核心要点
- 现有BEV融合方法在上下文建模、空间融合和不确定性推理方面存在不足,限制了3D目标检测的性能。
- MambaFusion通过交织SSM和Transformer,并引入多模态对齐和可靠性感知融合,实现高效自适应的3D感知。
- MambaFusion在nuScenes数据集上取得了SOTA性能,验证了SSM与可靠性驱动融合结合的有效性。
📝 摘要(中文)
可靠的3D目标检测是自动驾驶的基础,而使用相机和激光雷达的多模态融合算法仍然是一个持续的挑战。相机提供密集的视觉线索,但深度信息不准确;激光雷达提供精确的3D结构,但覆盖范围稀疏。现有的基于BEV的融合框架已经取得了良好的进展,但它们在低效的上下文建模、空间不变融合以及不确定性推理方面存在困难。我们引入了MambaFusion,一个统一的多模态检测框架,实现了高效、自适应和物理基础的3D感知。MambaFusion将选择性状态空间模型(SSM)与窗口Transformer交织在一起,以线性时间传播全局上下文,同时保持局部几何保真度。多模态令牌对齐(MTA)模块和可靠性感知融合门根据空间置信度和校准一致性动态地重新加权相机-激光雷达特征。最后,结构条件扩散头将基于图的推理与不确定性感知去噪相结合,从而增强了物理合理性和校准置信度。MambaFusion在nuScenes基准测试中建立了新的最先进性能,同时以线性时间复杂度运行。该框架表明,将基于SSM的效率与可靠性驱动的融合相结合,可以为现实世界的自动驾驶系统产生鲁棒、时间稳定和可解释的3D感知。
🔬 方法详解
问题定义:论文旨在解决多模态3D目标检测中,如何有效融合相机和激光雷达数据,并克服现有方法在上下文建模、空间不变融合和不确定性推理方面的局限性。现有方法通常难以在全局上下文建模和局部几何保真度之间取得平衡,且对不同模态数据的可靠性考虑不足。
核心思路:论文的核心思路是利用选择性状态空间模型(SSM)的高效全局上下文建模能力,并结合窗口Transformer的局部几何保真度,同时引入多模态令牌对齐和可靠性感知融合机制,以自适应地融合不同模态的数据。此外,使用结构条件扩散头来增强物理合理性和校准置信度。
技术框架:MambaFusion框架包含以下主要模块:1) 交织的SSM和窗口Transformer,用于高效的上下文建模;2) 多模态令牌对齐(MTA)模块,用于对齐相机和激光雷达特征;3) 可靠性感知融合门,用于动态地重新加权不同模态的特征;4) 结构条件扩散头,用于增强物理合理性和校准置信度。整体流程是从多模态数据中提取特征,然后通过上述模块进行融合和推理,最终输出3D目标检测结果。
关键创新:MambaFusion的关键创新在于:1) 将SSM引入多模态3D目标检测,实现了线性时间复杂度的全局上下文建模;2) 提出了多模态令牌对齐(MTA)模块和可靠性感知融合门,实现了自适应的模态融合;3) 使用结构条件扩散头,增强了物理合理性和校准置信度。与现有方法相比,MambaFusion在效率、自适应性和鲁棒性方面都有显著提升。
关键设计:论文中关键的设计包括:SSM的具体实现方式(例如,选择性状态空间模型的参数设置),窗口Transformer的窗口大小和层数,多模态令牌对齐模块的具体对齐策略,可靠性感知融合门的权重计算方式,以及结构条件扩散头的扩散过程和损失函数设计。这些细节共同决定了MambaFusion的性能。
🖼️ 关键图片


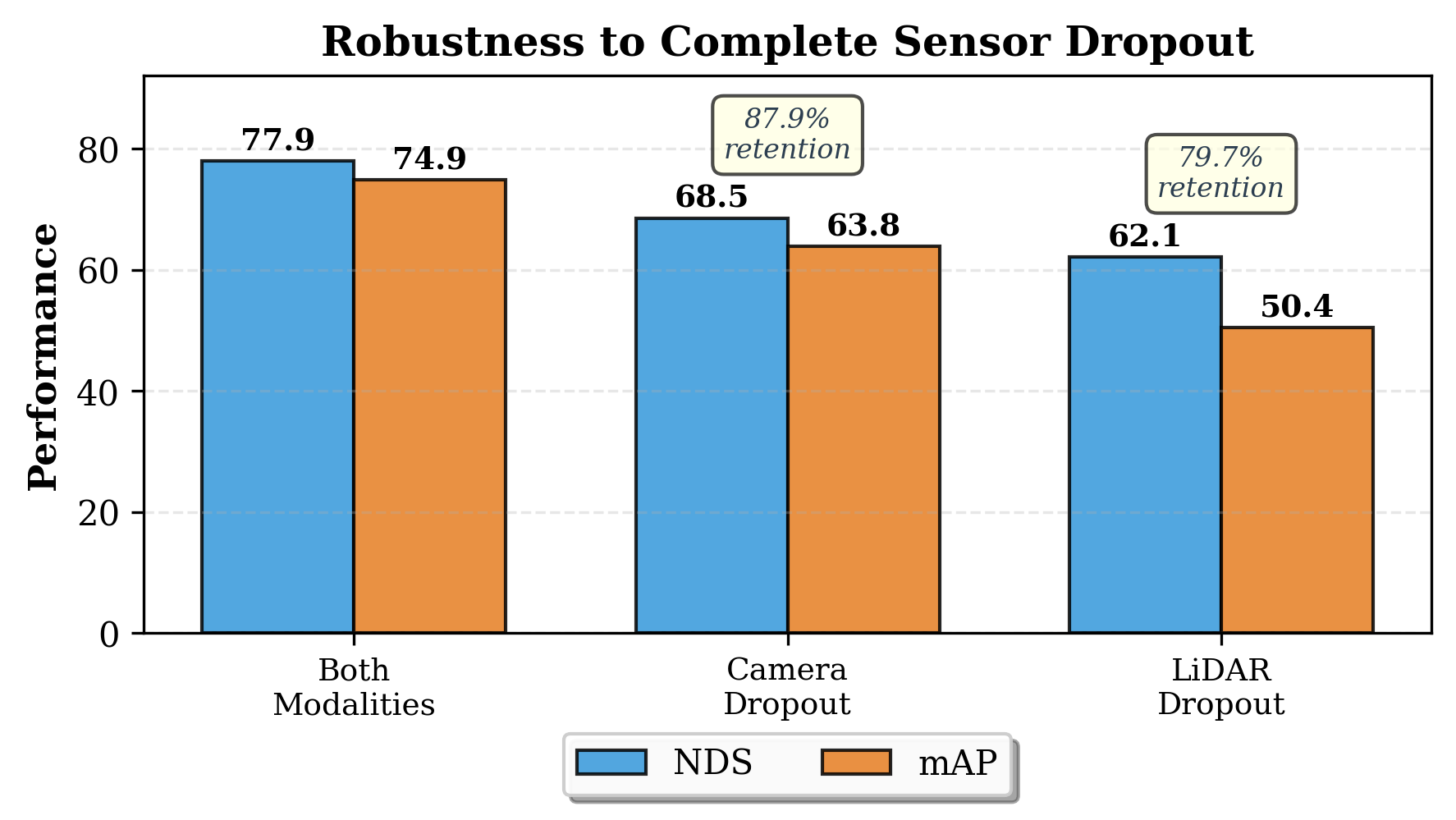
📊 实验亮点
MambaFusion在nuScenes数据集上取得了state-of-the-art的性能,证明了其在多模态3D目标检测方面的优越性。该方法在保持高精度的同时,还具有线性时间复杂度,使其更适用于实时性要求高的应用场景。
🎯 应用场景
MambaFusion在自动驾驶领域具有广泛的应用前景,可以提升车辆对周围环境的感知能力,从而提高驾驶安全性。此外,该技术还可以应用于机器人、智能交通等领域,实现更可靠、更高效的3D环境感知。
📄 摘要(原文)
Reliable 3D object detection is fundamental to autonomous driving, and multimodal fusion algorithms using cameras and LiDAR remain a persistent challenge. Cameras provide dense visual cues but ill posed depth; LiDAR provides a precise 3D structure but sparse coverage. Existing BEV-based fusion frameworks have made good progress, but they have difficulties including inefficient context modeling, spatially invariant fusion, and reasoning under uncertainty. We introduce MambaFusion, a unified multi-modal detection framework that achieves efficient, adaptive, and physically grounded 3D perception. MambaFusion interleaves selective state-space models (SSMs) with windowed transformers to propagate the global context in linear time while preserving local geometric fidelity. A multi-modal token alignment (MTA) module and reliability-aware fusion gates dynamically re-weight camera-LiDAR features based on spatial confidence and calibration consistency. Finally, a structure-conditioned diffusion head integrates graph-based reasoning with uncertainty-aware denoising, enforcing physical plausibility, and calibrated confidence. MambaFusion establishes new state-of-the-art performance on nuScenes benchmarks while operating with linear-time complexity. The framework demonstrates that coupling SSM-based efficiency with reliability-driven fusion yields robust, temporally stable, and interpretable 3D perception for real-world autonomous driving systems.