VidVec: Unlocking Video MLLM Embeddings for Video-Text Retrieval
作者: Issar Tzachor, Dvir Samuel, Rami Ben-Ari
分类: cs.CV, cs.AI
发布日期: 2026-02-08
备注: Project page: https://iyttor.github.io/VidVec/
💡 一句话要点
VidVec:利用视频MLLM嵌入实现视频-文本检索,无需额外视觉训练。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频检索 多模态学习 大型语言模型 零样本学习 文本对齐
📋 核心要点
- 现有方法利用MLLM进行视频理解时,性能不如专门的视频基础模型,存在提升空间。
- VidVec的核心思想是利用预训练MLLM中间层已有的知识,结合文本对齐策略,实现高效的视频-文本嵌入。
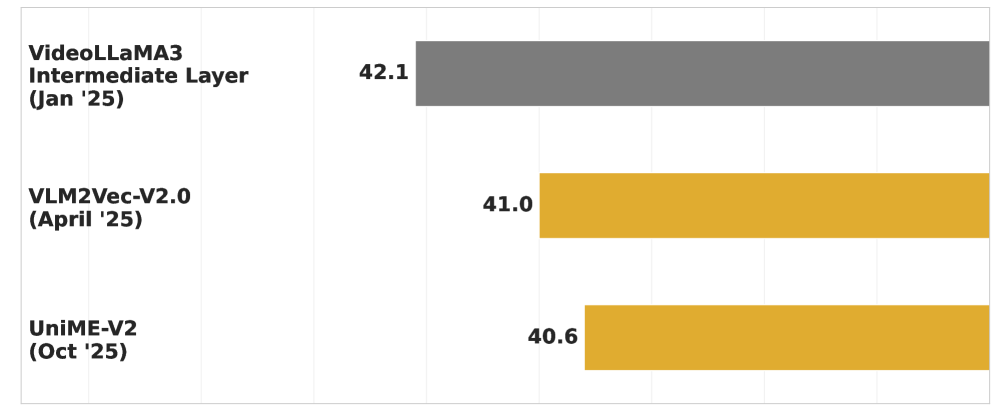
- 实验表明,VidVec无需额外视觉训练,即可在视频检索任务上取得显著的性能提升,达到SOTA水平。
📝 摘要(中文)
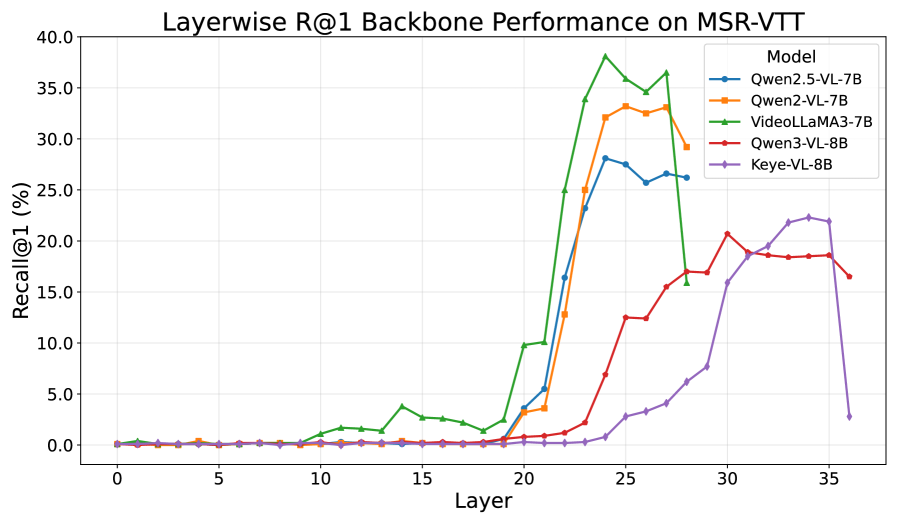
最近的研究已将生成式多模态大型语言模型(MLLMs)应用于视觉任务的嵌入提取器,通常通过微调来产生通用表示。然而,它们在视频上的性能仍然不如视频基础模型(VFMs)。在本文中,我们专注于利用MLLM进行视频-文本嵌入和检索。我们首先进行系统的逐层分析,表明中间(预训练)MLLM层已经编码了大量的任务相关信息。利用这一洞察力,我们证明了将中间层嵌入与校准的MLLM头部相结合,可以在没有任何训练的情况下产生强大的零样本检索性能。在此基础上,我们引入了一种轻量级的基于文本的对齐策略,该策略将密集的视频字幕映射到简短的摘要,并支持与任务相关的视频-文本嵌入学习,而无需视觉监督。值得注意的是,除了文本之外,没有任何微调,我们的方法优于当前的方法,通常幅度很大,在常见的视频检索基准上实现了最先进的结果。
🔬 方法详解
问题定义:论文旨在提升视频-文本检索任务的性能,现有方法依赖于对MLLM进行视觉微调,但效果不如专门的视频基础模型。痛点在于如何更有效地利用MLLM的知识,同时避免昂贵的视觉训练。
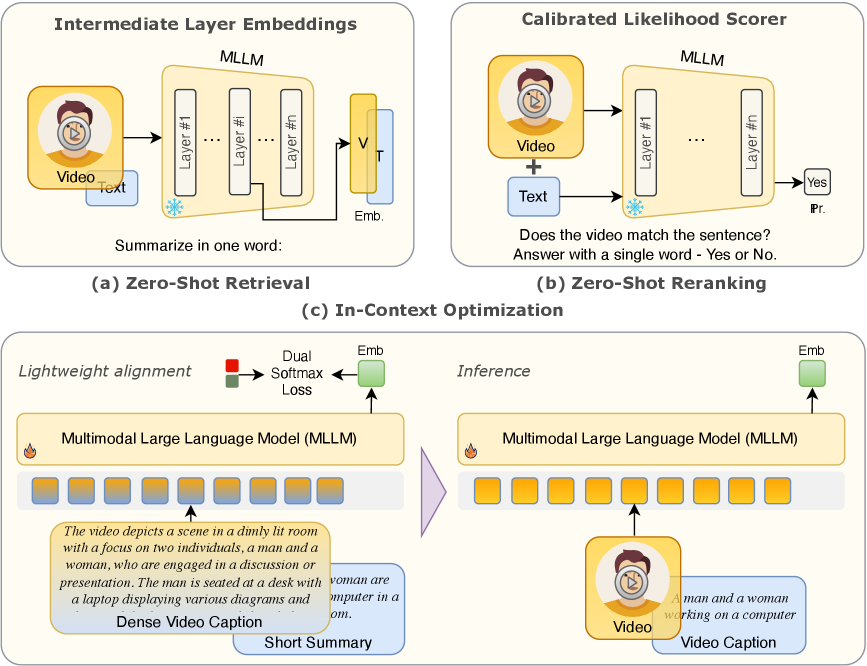
核心思路:论文的核心思路是,预训练的MLLM中间层已经包含了大量的任务相关信息,因此可以直接利用这些信息进行视频-文本嵌入。此外,通过文本对齐策略,可以将视频字幕映射到简短摘要,从而实现无视觉监督的视频-文本嵌入学习。
技术框架:VidVec方法主要包含两个阶段:1)利用预训练MLLM的中间层提取视频特征,并使用校准的MLLM头部进行特征调整。2)引入文本对齐策略,将密集的视频字幕映射到简短的摘要,从而实现无视觉监督的视频-文本嵌入学习。整体流程无需额外的视觉训练。
关键创新:最重要的创新点在于,发现并有效利用了预训练MLLM中间层中蕴含的视频语义信息,避免了对MLLM进行大规模视觉微调的需求。此外,提出的文本对齐策略,实现了无视觉监督的视频-文本嵌入学习,降低了训练成本。
关键设计:文本对齐策略的关键在于如何将密集的视频字幕映射到简短的摘要。具体实现细节未知,但推测可能使用了文本摘要模型或相似的技术。此外,如何选择合适的MLLM中间层,以及如何校准MLLM头部,也是影响性能的关键因素,具体参数设置未知。
🖼️ 关键图片
📊 实验亮点
VidVec在多个视频检索基准数据集上取得了state-of-the-art的结果,无需任何视觉微调。具体性能提升幅度未知,但论文强调了显著的性能提升。该方法在效率和性能之间取得了良好的平衡,为视频理解领域的研究提供了新的思路。
🎯 应用场景
VidVec方法可广泛应用于视频检索、视频推荐、视频内容理解等领域。该研究降低了视频理解模型的训练成本,有望推动多模态大模型在视频领域的应用,并提升相关应用的智能化水平。未来,该方法可以扩展到其他视频相关的任务,例如视频问答、视频摘要等。
📄 摘要(原文)
Recent studies have adapted generative Multimodal Large Language Models (MLLMs) into embedding extractors for vision tasks, typically through fine-tuning to produce universal representations. However, their performance on video remains inferior to Video Foundation Models (VFMs). In this paper, we focus on leveraging MLLMs for video-text embedding and retrieval. We first conduct a systematic layer-wise analysis, showing that intermediate (pre-trained) MLLM layers already encode substantial task-relevant information. Leveraging this insight, we demonstrate that combining intermediate-layer embeddings with a calibrated MLLM head yields strong zero-shot retrieval performance without any training. Building on these findings, we introduce a lightweight text-based alignment strategy which maps dense video captions to short summaries and enables task-related video-text embedding learning without visual supervision. Remarkably, without any fine-tuning beyond text, our method outperforms current methods, often by a substantial margin, achieving state-of-the-art results across common video retrieval benchmarks.