ViT-5: Vision Transformers for The Mid-2020s
作者: Feng Wang, Sucheng Ren, Tiezheng Zhang, Predrag Neskovic, Anand Bhattad, Cihang Xie, Alan Yuille
分类: cs.CV
发布日期: 2026-02-08
备注: Code is available at https://github.com/wangf3014/ViT-5
💡 一句话要点
ViT-5:通过架构改进,为2020年代中期视觉任务提供更优的Vision Transformer骨干网络。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Vision Transformer 图像分类 图像生成 骨干网络 架构改进
📋 核心要点
- 现有Vision Transformer在架构设计上存在改进空间,限制了其在复杂视觉任务中的性能。
- ViT-5通过对Vision Transformer的Normalization、激活函数、位置编码等组件进行精细化改进,提升模型性能。
- 实验表明,ViT-5在图像分类和生成任务上均优于现有ViT模型,并具有更好的表征学习能力。
📝 摘要(中文)
本文系统性地研究了如何通过利用过去五年中的架构进步来改进Vision Transformer骨干网络。在保留经典的Attention-FFN结构的同时,我们进行了一个组件级的优化,包括归一化、激活函数、位置编码、门控机制和可学习的tokens。这些更新构成了一个新一代的Vision Transformer,我们称之为ViT-5。大量的实验表明,ViT-5在理解和生成基准测试中始终优于最先进的普通Vision Transformer。在ImageNet-1k分类上,ViT-5-Base在相当的计算量下达到了84.2%的top-1准确率,超过了DeiT-III-Base的83.8%。ViT-5也可以作为生成建模的更强骨干网络:当插入到SiT扩散框架中时,它实现了1.84的FID,而使用原始ViT骨干网络时为2.06。除了主要指标外,ViT-5还表现出改进的表征学习和良好的空间推理行为,并且可以在任务之间可靠地迁移。凭借与当代基础模型实践相一致的设计,ViT-5为2020年代中期的视觉骨干网络提供了一个简单的即插即用升级方案。
🔬 方法详解
问题定义:现有Vision Transformer虽然取得了显著进展,但在Normalization、激活函数、位置编码等组件的设计上仍有优化空间,限制了其在各种视觉任务中的性能。论文旨在通过系统性地改进这些组件,提升Vision Transformer的整体性能。
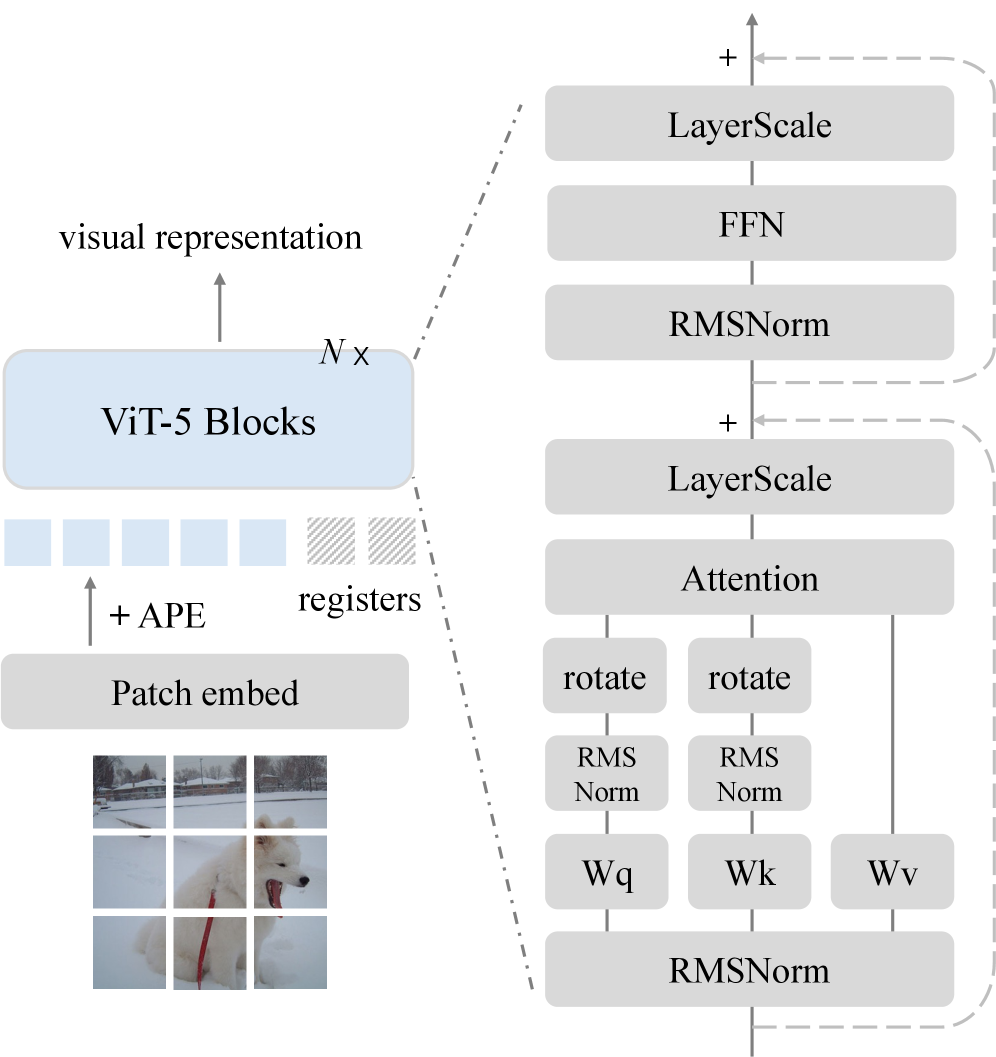
核心思路:论文的核心思路是在保持Vision Transformer基本Attention-FFN结构不变的前提下,逐个优化Normalization、激活函数、位置编码、门控机制和可学习的tokens等关键组件。通过这种方式,可以充分利用近年来在Transformer架构设计上的最新进展,从而提升模型的性能。
技术框架:ViT-5的整体架构仍然是基于Transformer的编码器结构,主要包括以下几个模块:输入嵌入层(包括位置编码)、Transformer编码器层(包含自注意力机制和前馈网络)、以及输出层。关键的改进在于Transformer编码器层内部的组件,例如Normalization层、激活函数、门控机制等。
关键创新:ViT-5的关键创新在于其组件级的优化策略。它不是简单地堆叠更多的Transformer层,而是深入研究了每个组件对模型性能的影响,并采用了最先进的设计。例如,采用了更有效的Normalization方法,更适合视觉任务的激活函数,以及更精确的位置编码方式。
关键设计:ViT-5在Normalization方面可能采用了LayerScale或RMSNorm等方法,激活函数可能选择了GELU或SwiGLU等,位置编码可能使用了旋转位置编码(RoPE)或条件位置编码等。此外,门控机制可能采用了SimpleGate或gMLP等。具体的参数设置和网络结构细节需要在论文中进一步查找。
🖼️ 关键图片


📊 实验亮点
ViT-5在ImageNet-1k分类任务上,ViT-5-Base在相当的计算量下达到了84.2%的top-1准确率,超过了DeiT-III-Base的83.8%。在SiT扩散框架中,ViT-5实现了1.84的FID,而使用原始ViT骨干网络时为2.06。这些结果表明,ViT-5在图像理解和生成任务上均取得了显著的性能提升。
🎯 应用场景
ViT-5作为一种通用的视觉骨干网络,可以广泛应用于图像分类、目标检测、图像分割、图像生成等各种视觉任务。它还可以作为基础模型,通过微调或迁移学习的方式,应用于各种特定领域的视觉应用中,例如医学图像分析、遥感图像处理等。ViT-5的改进设计有望推动视觉Transformer在实际应用中的普及。
📄 摘要(原文)
This work presents a systematic investigation into modernizing Vision Transformer backbones by leveraging architectural advancements from the past five years. While preserving the canonical Attention-FFN structure, we conduct a component-wise refinement involving normalization, activation functions, positional encoding, gating mechanisms, and learnable tokens. These updates form a new generation of Vision Transformers, which we call ViT-5. Extensive experiments demonstrate that ViT-5 consistently outperforms state-of-the-art plain Vision Transformers across both understanding and generation benchmarks. On ImageNet-1k classification, ViT-5-Base reaches 84.2\% top-1 accuracy under comparable compute, exceeding DeiT-III-Base at 83.8\%. ViT-5 also serves as a stronger backbone for generative modeling: when plugged into an SiT diffusion framework, it achieves 1.84 FID versus 2.06 with a vanilla ViT backbone. Beyond headline metrics, ViT-5 exhibits improved representation learning and favorable spatial reasoning behavior, and transfers reliably across tasks. With a design aligned with contemporary foundation-model practices, ViT-5 offers a simple drop-in upgrade over vanilla ViT for mid-2020s vision backbones.