Weak to Strong: VLM-Based Pseudo-Labeling as a Weakly Supervised Training Strategy in Multimodal Video-based Hidden Emotion Understanding Tasks
作者: Yufei Wang, Haixu Liu, Tianxiang Xu, Chuancheng Shi, Hongsheng Xing
分类: cs.CV, cs.AI
发布日期: 2026-02-08
💡 一句话要点
提出基于VLM伪标签的弱监督学习框架,用于多模态视频隐藏情感理解任务
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 弱监督学习 多模态融合 视频情感识别 伪标签生成 大型语言模型 Transformer 类别不平衡
📋 核心要点
- 现有方法在视频隐藏情感理解任务中表现不足,尤其是在类别不平衡的情况下,模型性能较低。
- 利用大型语言模型(VLM)生成伪标签,并结合多模态信息,为模型提供弱监督信号,提升情感识别准确率。
- 实验表明,该方法在iMiGUE数据集上显著提升了情感识别准确率,并验证了MLP在关键点建模中的有效性。
📝 摘要(中文)
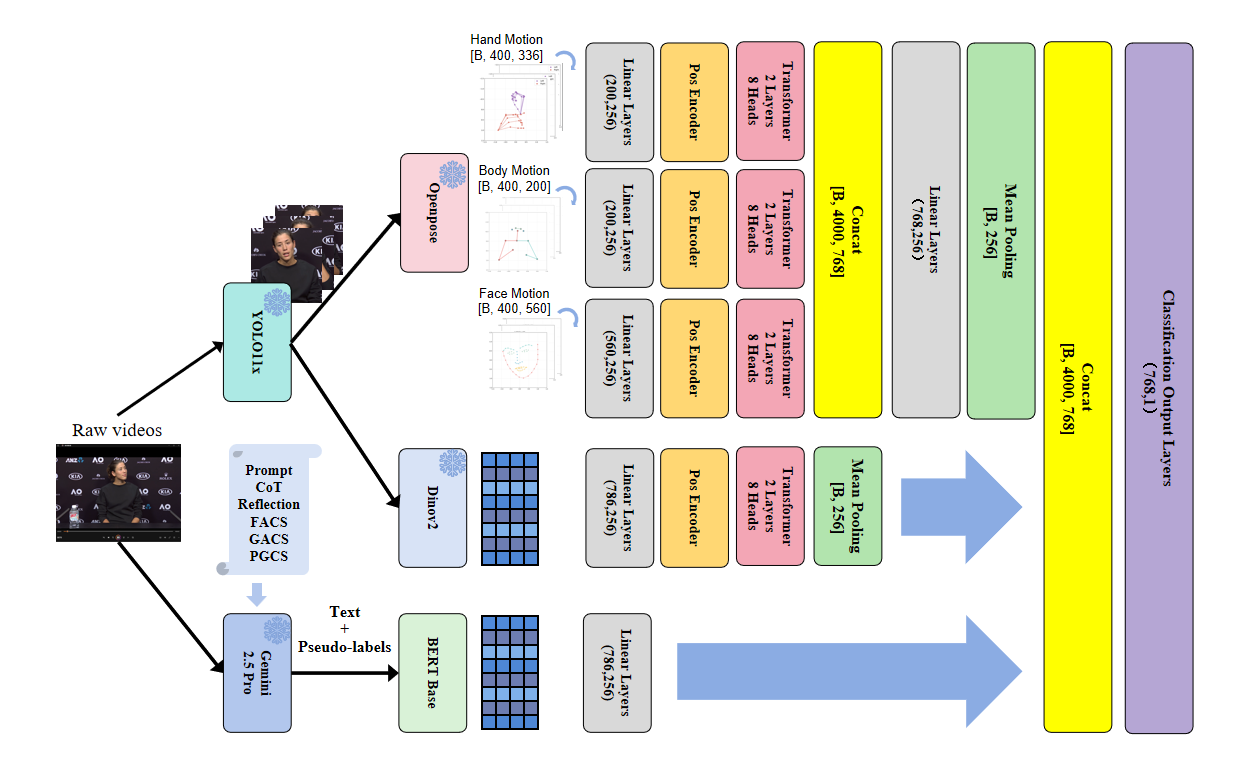
本文旨在解决视频中“隐藏情感”的自动识别问题,提出了一种多模态弱监督框架,并在iMiGUE网球采访数据集上取得了当前最佳结果。首先,使用YOLO 11x逐帧检测并裁剪人像,然后使用DINOv2-Base提取裁剪区域的视觉特征。接着,通过整合思维链和反思提示(CoT + Reflection),Gemini 2.5 Pro自动生成伪标签和推理文本,作为下游模型的弱监督信号。随后,OpenPose生成137维关键点序列,并辅以帧间偏移特征;将常用的图神经网络骨干网络简化为MLP,以高效地建模三个关键点流的时空关系。一个超长序列Transformer独立编码图像和关键点序列,并将它们的表示与BERT编码的采访文本连接起来。每个模态首先独立进行预训练,然后联合微调,并将伪标签样本合并到训练集中以进一步提升性能。实验表明,尽管存在严重的类别不平衡,所提出的方法将准确率从先前工作的0.6以下提升到0.69以上,建立了一个新的公开基准。该研究还验证了“MLP化”的关键点骨干网络可以在此任务中匹配甚至超越基于GCN的对应网络。
🔬 方法详解
问题定义:论文旨在解决视频中隐藏情感的自动识别问题。现有方法在处理类别不平衡和缺乏强监督信号的情况下表现不佳,导致情感识别准确率较低。特别是在iMiGUE这种具有挑战性的数据集上,现有方法难以有效捕捉细微的情感变化。
核心思路:论文的核心思路是利用大型语言模型(VLM)生成高质量的伪标签,作为弱监督信号来训练多模态情感识别模型。通过结合视觉、骨骼关键点和文本信息,模型能够更全面地理解视频中的情感表达。这种方法旨在克服缺乏强监督数据和类别不平衡的挑战。
技术框架:整体框架包含以下几个主要阶段:1) 视觉特征提取:使用YOLO 11x检测人脸,DINOv2-Base提取视觉特征。2) 伪标签生成:利用Gemini 2.5 Pro生成伪标签和推理文本。3) 骨骼关键点提取:使用OpenPose提取137维关键点序列。4) 特征编码:使用Transformer编码视觉和关键点序列,BERT编码文本信息。5) 预训练和微调:每个模态独立预训练,然后联合微调,并加入伪标签数据。
关键创新:最重要的技术创新点在于利用VLM生成伪标签作为弱监督信号。与传统的监督学习方法相比,这种方法能够利用无标签数据,缓解数据稀缺和类别不平衡的问题。此外,将GCN替换为MLP来建模骨骼关键点序列,在保证性能的同时降低了计算复杂度。
关键设计:在伪标签生成阶段,使用了Chain-of-Thought和Reflection prompting (CoT + Reflection) 来提高伪标签的质量。在骨骼关键点建模中,使用MLP替代GCN,并添加了帧间偏移特征来增强时序信息。在模型训练中,采用了多阶段训练策略,包括独立预训练和联合微调,以充分利用不同模态的信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在iMiGUE数据集上取得了显著的性能提升,将准确率从0.6以下提升到0.69以上,建立了新的公开基准。此外,研究验证了使用MLP替代GCN建模骨骼关键点序列的有效性,在保证性能的同时降低了计算复杂度。
🎯 应用场景
该研究成果可应用于人机交互、心理健康评估、市场调研等领域。通过自动识别视频中隐藏的情感,可以更准确地理解用户的情感状态,从而提供更个性化的服务和支持。未来,该技术有望在情感计算领域发挥重要作用,促进人工智能在情感理解方面的发展。
📄 摘要(原文)
To tackle the automatic recognition of "concealed emotions" in videos, this paper proposes a multimodal weak-supervision framework and achieves state-of-the-art results on the iMiGUE tennis-interview dataset. First, YOLO 11x detects and crops human portraits frame-by-frame, and DINOv2-Base extracts visual features from the cropped regions. Next, by integrating Chain-of-Thought and Reflection prompting (CoT + Reflection), Gemini 2.5 Pro automatically generates pseudo-labels and reasoning texts that serve as weak supervision for downstream models. Subsequently, OpenPose produces 137-dimensional key-point sequences, augmented with inter-frame offset features; the usual graph neural network backbone is simplified to an MLP to efficiently model the spatiotemporal relationships of the three key-point streams. An ultra-long-sequence Transformer independently encodes both the image and key-point sequences, and their representations are concatenated with BERT-encoded interview transcripts. Each modality is first pre-trained in isolation, then fine-tuned jointly, with pseudo-labeled samples merged into the training set for further gains. Experiments demonstrate that, despite severe class imbalance, the proposed approach lifts accuracy from under 0.6 in prior work to over 0.69, establishing a new public benchmark. The study also validates that an "MLP-ified" key-point backbone can match - or even surpass - GCN-based counterparts in this task.