MIND: Benchmarking Memory Consistency and Action Control in World Models
作者: Yixuan Ye, Xuanyu Lu, Yuxin Jiang, Yuchao Gu, Rui Zhao, Qiwei Liang, Jiachun Pan, Fengda Zhang, Weijia Wu, Alex Jinpeng Wang
分类: cs.CV, cs.AI
发布日期: 2026-02-08 (更新: 2026-02-11)
🔗 代码/项目: GITHUB
💡 一句话要点
MIND:用于评估世界模型记忆一致性和动作控制的综合性基准测试
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 世界模型 记忆一致性 动作控制 基准测试 视频理解
📋 核心要点
- 现有世界模型缺乏统一的评估标准,难以衡量其记忆一致性和动作控制能力。
- MIND基准测试通过构建包含多种视角和动作空间的视频数据集,提供了一个综合性的评估平台。
- 实验表明,现有世界模型在长期记忆一致性和跨动作空间泛化方面存在显著挑战。
📝 摘要(中文)
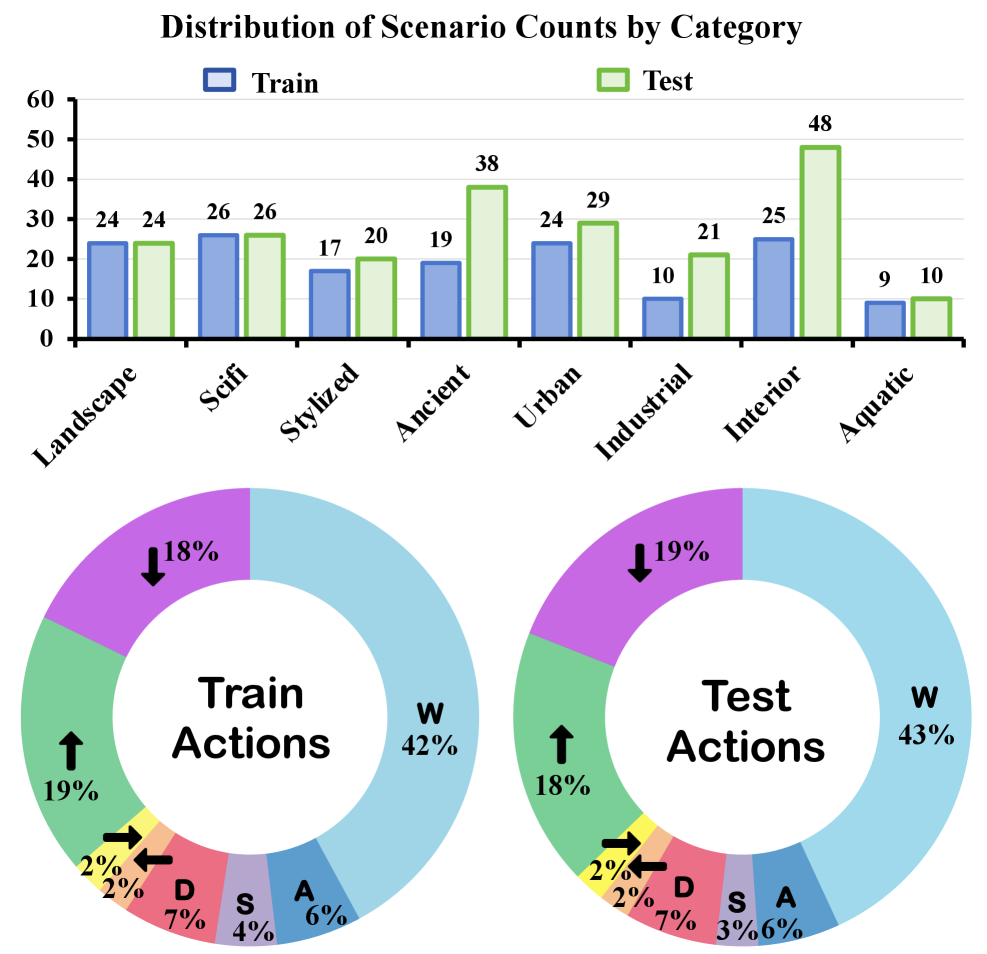
世界模型旨在理解、记忆和预测动态视觉环境,但目前缺乏一个统一的基准来评估其基本能力。为了解决这一问题,我们推出了MIND,这是首个开放域、闭环、可复现的基准测试,用于评估世界模型中的记忆一致性和动作控制。MIND包含250个高质量视频,分辨率为1080p,帧率为24 FPS,其中包括100个第一人称视角和100个第三人称视角的视频片段,它们共享一个动作空间,以及25+25个跨不同动作空间的视频片段,涵盖八个不同的场景。我们设计了一个高效的评估框架来衡量两个核心能力:记忆一致性和动作控制,捕捉跨视角的时序稳定性和上下文连贯性。此外,我们设计了各种动作空间,包括不同的角色移动速度和相机旋转角度,以评估在共享场景下跨不同动作空间的动作泛化能力。为了促进未来在MIND上的性能基准测试,我们引入了MIND-World,一种新颖的交互式Video-to-World基线。大量的实验证明了MIND的完备性,并揭示了当前世界模型中的关键挑战,包括维持长期记忆一致性和跨动作空间泛化的困难。
🔬 方法详解
问题定义:现有世界模型缺乏统一的评估标准,难以全面衡量其在记忆一致性和动作控制方面的能力。特别是在开放域、闭环的交互式环境中,如何评估模型对环境的理解、长期记忆以及根据指令控制动作的能力是一个挑战。现有方法难以有效评估模型在不同视角和动作空间下的泛化能力。
核心思路:MIND基准测试的核心思路是构建一个包含多种视角(第一人称和第三人称)和动作空间的视频数据集,并设计相应的评估指标,以全面衡量世界模型的记忆一致性和动作控制能力。通过提供一个标准化的评估平台,促进世界模型的研究和发展。
技术框架:MIND基准测试包含以下几个主要组成部分:1) 高质量视频数据集:包含250个视频,涵盖不同视角、动作空间和场景。2) 评估框架:设计了用于衡量记忆一致性和动作控制的评估指标,包括时序稳定性和上下文连贯性。3) MIND-World基线模型:提供了一个交互式的Video-to-World基线模型,用于未来性能基准测试。
关键创新:MIND基准测试的关键创新在于:1) 首次提出了一个开放域、闭环、可复现的基准测试,用于评估世界模型的记忆一致性和动作控制能力。2) 构建了一个包含多种视角和动作空间的高质量视频数据集,更全面地评估模型的泛化能力。3) 设计了一个高效的评估框架,能够准确衡量模型的时序稳定性和上下文连贯性。
关键设计:MIND基准测试的关键设计包括:1) 视频数据集的构建:精心设计了不同视角和动作空间的视频片段,以覆盖各种可能的交互场景。2) 评估指标的设计:采用了多种评估指标,包括衡量记忆一致性的指标(如预测的准确性)和衡量动作控制的指标(如动作执行的成功率)。3) MIND-World基线模型的设计:采用了一种交互式的Video-to-World模型,能够根据视频输入预测未来的状态和动作。
🖼️ 关键图片


📊 实验亮点
实验结果表明,现有世界模型在MIND基准测试上表现出明显的局限性,尤其是在长期记忆一致性和跨动作空间泛化方面。例如,模型在维持长时间序列的上下文连贯性方面存在困难,并且在不同动作空间下的性能差异较大。MIND-World基线模型虽然取得了一定的成果,但仍有很大的提升空间,为未来的研究提供了明确的方向。
🎯 应用场景
MIND基准测试的潜在应用领域包括机器人导航、自动驾驶、游戏AI和虚拟现实等。通过提高世界模型的记忆一致性和动作控制能力,可以使智能体更好地理解和适应复杂环境,从而实现更智能、更自主的决策和行为。该研究的实际价值在于推动世界模型的发展,并为相关应用提供更可靠的技术支持。未来,MIND可以扩展到更多场景和任务,为更广泛的研究提供基准。
📄 摘要(原文)
World models aim to understand, remember, and predict dynamic visual environments, yet a unified benchmark for evaluating their fundamental abilities remains lacking. To address this gap, we introduce MIND, the first open-domain closed-loop revisited benchmark for evaluating Memory consIstency and action coNtrol in worlD models. MIND contains 250 high-quality videos at 1080p and 24 FPS, including 100 (first-person) + 100 (third-person) video clips under a shared action space and 25 + 25 clips across varied action spaces covering eight diverse scenes. We design an efficient evaluation framework to measure two core abilities: memory consistency and action control, capturing temporal stability and contextual coherence across viewpoints. Furthermore, we design various action spaces, including different character movement speeds and camera rotation angles, to evaluate the action generalization capability across different action spaces under shared scenes. To facilitate future performance benchmarking on MIND, we introduce MIND-World, a novel interactive Video-to-World baseline. Extensive experiments demonstrate the completeness of MIND and reveal key challenges in current world models, including the difficulty of maintaining long-term memory consistency and generalizing across action spaces. Code: https://github.com/CSU-JPG/MIND.