FlashVID: Efficient Video Large Language Models via Training-free Tree-based Spatiotemporal Token Merging
作者: Ziyang Fan, Keyu Chen, Ruilong Xing, Yulin Li, Li Jiang, Zhuotao Tian
分类: cs.CV, cs.AI, cs.CL, cs.LG
发布日期: 2026-02-08
备注: Accepted by ICLR 2026 (Oral)
🔗 代码/项目: GITHUB
💡 一句话要点
FlashVID:提出一种免训练的树形时空Token融合方法,高效加速视频大语言模型推理。
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频大语言模型 推理加速 时空Token融合 免训练 长视频理解
📋 核心要点
- 现有VLLM加速方法独立压缩空间和时间冗余,忽略了视频中固有的时空相关性,导致压缩效率受限。
- FlashVID通过注意力与多样性驱动的Token选择和树形时空Token融合,实现细粒度的时空冗余消除,无需额外训练。
- 实验表明,FlashVID在保留极高模型性能的同时,显著提升了推理速度,并能有效扩展VLLM处理长视频的能力。
📝 摘要(中文)
视频大语言模型(VLLMs)在视频理解方面表现出卓越的能力,但需要处理大量的视觉tokens,导致计算效率低下。现有的VLLMs加速框架通常独立地压缩空间和时间冗余,忽略了时空关系,从而导致次优的时空压缩。由于视频的动态特性,高度相关的视觉特征可能会随着时间在空间位置、尺度、方向和其他属性上发生变化。基于此,我们提出了FlashVID,一个用于VLLMs的免训练推理加速框架。具体来说,FlashVID利用基于注意力和多样性的Token选择(ADTS)来选择最具代表性的tokens进行基本视频表示,然后应用基于树的时空Token融合(TSTM)进行细粒度的时空冗余消除。在五个视频理解基准上对三个代表性VLLMs进行的大量实验证明了我们方法的有效性和泛化性。值得注意的是,通过仅保留10%的视觉tokens,FlashVID保留了LLaVA-OneVision 99.1%的性能。因此,FlashVID可以作为一个免训练和即插即用的模块来扩展长视频帧,从而使Qwen2.5-VL的视频帧输入增加10倍,在相同的计算预算内,相对提高了8.6%。代码可在https://github.com/Fanziyang-v/FlashVID 获取。
🔬 方法详解
问题定义:现有视频大语言模型(VLLM)在处理视频时,需要处理大量的视觉tokens,导致计算量巨大,推理速度慢。现有的加速框架通常独立地压缩空间和时间冗余,忽略了视频中存在的时空相关性,导致压缩效率不高,影响了模型的性能。
核心思路:FlashVID的核心思路是利用视频帧之间存在的时空冗余,通过选择最具代表性的tokens并进行融合,从而减少需要处理的tokens数量,提高推理速度。该方法无需额外的训练,可以即插即用,适用于各种VLLM。
技术框架:FlashVID主要包含两个阶段:注意力与多样性驱动的Token选择(ADTS)和树形时空Token融合(TSTM)。首先,ADTS根据tokens的注意力和多样性得分,选择最具代表性的tokens,形成基本的视频表示。然后,TSTM利用树形结构,对选择的tokens进行时空融合,进一步消除冗余。
关键创新:FlashVID的关键创新在于提出了树形时空Token融合(TSTM)方法。与传统的独立空间或时间压缩方法不同,TSTM能够同时考虑空间和时间维度上的冗余,实现更高效的压缩。此外,该方法是免训练的,易于集成到现有的VLLM中。
关键设计:ADTS阶段,注意力得分通过计算token与其他token之间的注意力权重得到,多样性得分则通过计算token特征之间的距离得到。TSTM阶段,采用树形结构进行融合,每个节点将多个子节点的特征进行融合,直到只剩下少量的tokens。融合过程中,可以使用平均池化、最大池化等操作。
🖼️ 关键图片
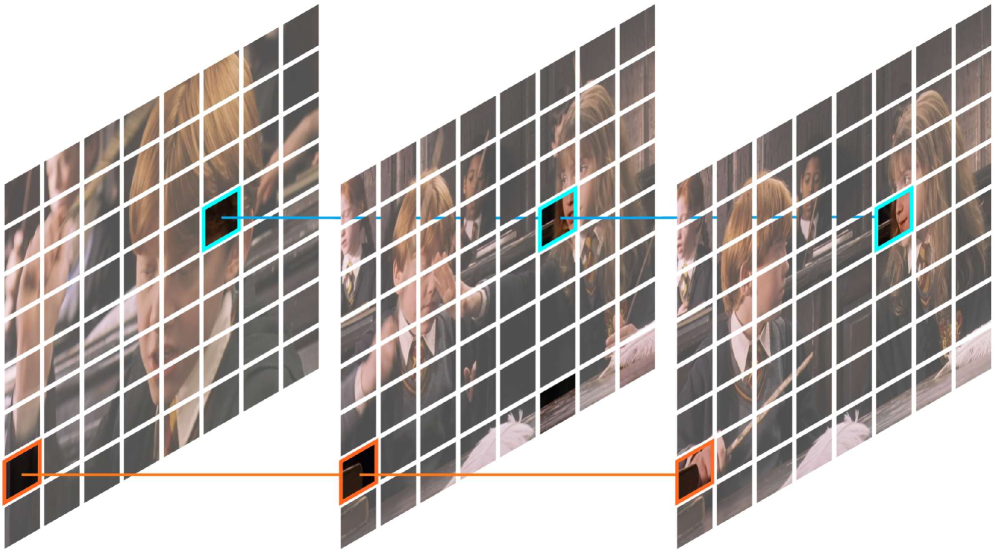

📊 实验亮点
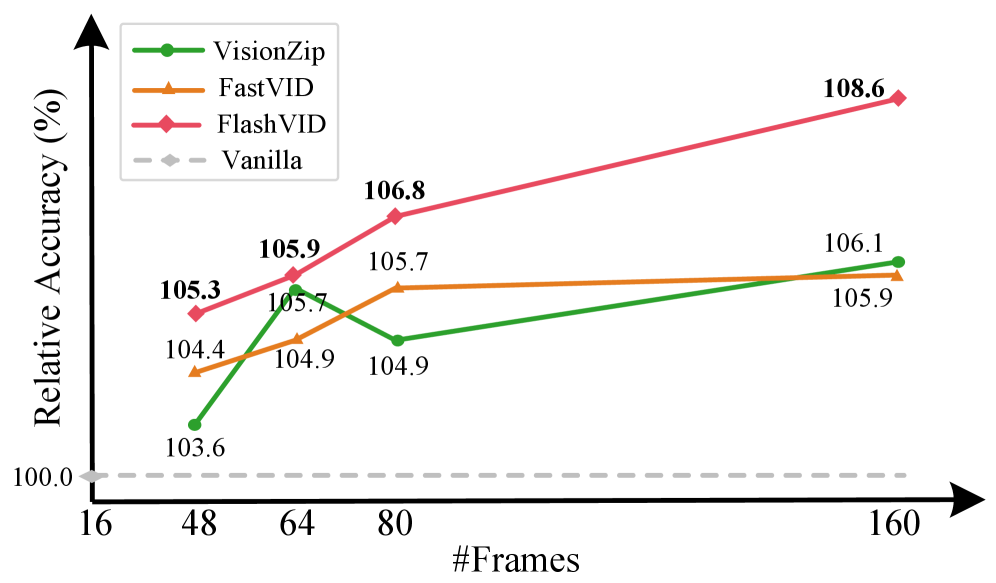
实验结果表明,FlashVID在保留少量视觉tokens(例如10%)的情况下,能够保持接近原始模型的性能(例如LLaVA-OneVision的99.1%)。此外,FlashVID能够显著提升VLLM处理长视频的能力,例如使Qwen2.5-VL的视频帧输入增加10倍,并在相同计算预算内实现8.6%的相对性能提升。
🎯 应用场景
FlashVID可广泛应用于视频理解、视频问答、视频摘要等领域。通过提高VLLM的推理效率,FlashVID可以支持更长的视频输入,从而提升模型在复杂场景下的应用能力。此外,FlashVID的免训练特性使其易于部署到各种VLLM中,具有很高的实用价值。
📄 摘要(原文)
Although Video Large Language Models (VLLMs) have shown remarkable capabilities in video understanding, they are required to process high volumes of visual tokens, causing significant computational inefficiency. Existing VLLMs acceleration frameworks usually compress spatial and temporal redundancy independently, which overlooks the spatiotemporal relationships, thereby leading to suboptimal spatiotemporal compression. The highly correlated visual features are likely to change in spatial position, scale, orientation, and other attributes over time due to the dynamic nature of video. Building on this insight, we introduce FlashVID, a training-free inference acceleration framework for VLLMs. Specifically, FlashVID utilizes Attention and Diversity-based Token Selection (ADTS) to select the most representative tokens for basic video representation, then applies Tree-based Spatiotemporal Token Merging (TSTM) for fine-grained spatiotemporal redundancy elimination. Extensive experiments conducted on three representative VLLMs across five video understanding benchmarks demonstrate the effectiveness and generalization of our method. Notably, by retaining only 10% of visual tokens, FlashVID preserves 99.1% of the performance of LLaVA-OneVision. Consequently, FlashVID can serve as a training-free and plug-and-play module for extending long video frames, which enables a 10x increase in video frame input to Qwen2.5-VL, resulting in a relative improvement of 8.6% within the same computational budget. Code is available at https://github.com/Fanziyang-v/FlashVID.