EasyTune: Efficient Step-Aware Fine-Tuning for Diffusion-Based Motion Generation
作者: Xiaofeng Tan, Wanjiang Weng, Haodong Lei, Hongsong Wang
分类: cs.CV
发布日期: 2026-02-08
期刊: ICLR 2026
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
EasyTune:一种高效的步进式微调方法,用于扩散模型驱动的运动生成。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 扩散模型 运动生成 微调 步进式优化 偏好学习 自精炼 可微奖励 运动对齐
📋 核心要点
- 现有基于扩散模型的运动生成方法在与下游目标对齐时,存在优化效率低、粒度粗糙以及内存消耗高等问题。
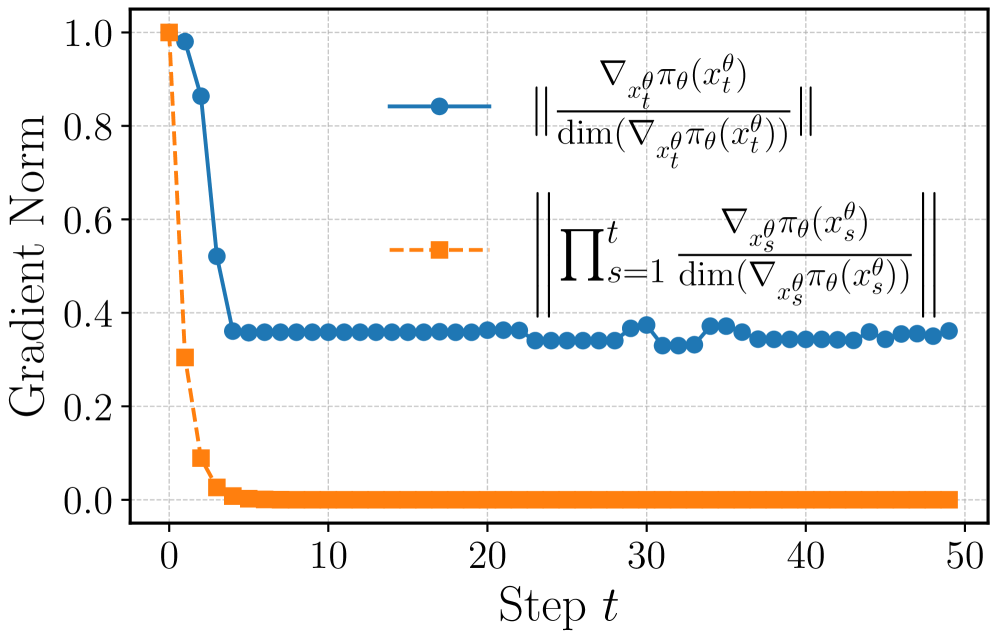
- EasyTune通过在每个去噪步骤中进行微调,解耦了去噪轨迹中不同步骤之间的递归依赖关系,从而实现更高效和细粒度的优化。
- EasyTune结合自精炼偏好学习机制,动态识别偏好对并进行偏好学习,缓解了偏好运动对稀缺的问题,实验表明其性能优于现有方法。
📝 摘要(中文)
近年来,运动生成模型取得了显著进展,但在与下游目标对齐方面仍面临挑战。最近的研究表明,使用可微奖励直接对齐扩散模型的偏好可以产生有希望的结果。然而,这些方法存在(1)低效且粗粒度的优化以及(2)高内存消耗的问题。本文从理论和实验上确定了这些限制的关键原因:去噪轨迹中不同步骤之间的递归依赖关系。受此启发,我们提出了EasyTune,它在每个去噪步骤中微调扩散模型,而不是在整个轨迹上进行微调。这解耦了递归依赖关系,使我们能够执行(1)密集和细粒度的优化,以及(2)内存高效的优化。此外,偏好运动对的稀缺性限制了运动奖励模型训练的可用性。为此,我们进一步引入了一种自精炼偏好学习(SPL)机制,该机制动态识别偏好对并进行偏好学习。大量实验表明,EasyTune在对齐(MM-Dist)改进方面优于DRaFT-50 8.2%,同时仅需要其31.16%的额外内存开销,并实现了7.3倍的训练加速。
🔬 方法详解
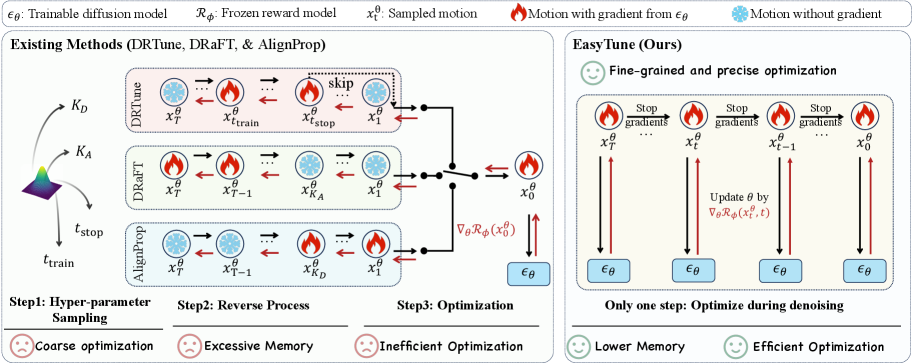
问题定义:论文旨在解决扩散模型在运动生成任务中,与下游目标对齐时存在的优化效率低、内存消耗高的问题。现有方法通常在整个去噪轨迹上进行微调,忽略了去噪过程中不同步骤之间的依赖关系,导致优化过程粗糙且效率低下。此外,训练偏好奖励模型所需的偏好运动数据通常比较稀缺。
核心思路:EasyTune的核心思路是解耦去噪轨迹中不同步骤之间的依赖关系,通过在每个去噪步骤上进行独立的微调,实现更细粒度和高效的优化。这种步进式的微调方式允许模型更精确地调整每个步骤的生成结果,从而更好地与下游目标对齐。同时,引入自精炼偏好学习机制,解决偏好数据稀缺的问题。
技术框架:EasyTune主要包含两个核心模块:步进式微调和自精炼偏好学习。步进式微调模块在扩散模型的每个去噪步骤中,利用可微奖励函数进行微调,优化每个步骤的生成结果。自精炼偏好学习模块则动态地识别和选择高质量的偏好运动对,用于训练偏好奖励模型,从而提高奖励模型的准确性和泛化能力。
关键创新:EasyTune的关键创新在于其步进式的微调策略,它将传统的全局微调分解为一系列局部微调,从而解耦了去噪步骤之间的依赖关系,实现了更高效和细粒度的优化。此外,自精炼偏好学习机制能够有效地利用有限的偏好数据,提高奖励模型的训练效果。
关键设计:EasyTune的关键设计包括:(1) 步进式微调的损失函数,它基于可微奖励函数,引导每个去噪步骤的生成结果向期望的目标靠近。(2) 自精炼偏好学习的偏好对选择策略,它根据一定的指标(例如奖励值差异)动态地选择高质量的偏好对,用于训练奖励模型。(3) 针对特定运动生成任务设计的奖励函数,用于评估生成运动的质量和与目标任务的对齐程度。
🖼️ 关键图片
📊 实验亮点
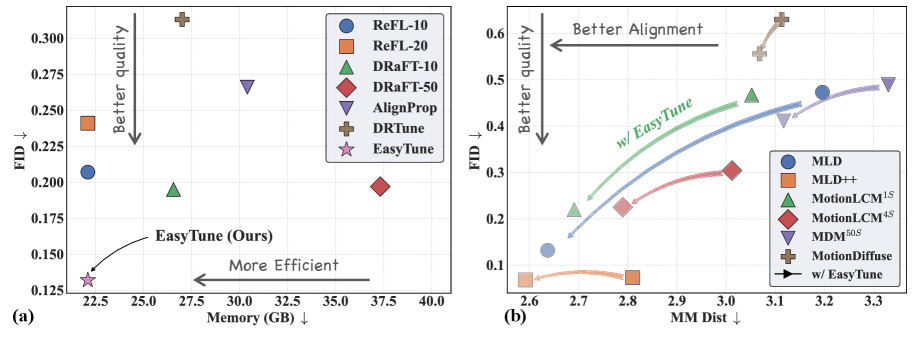
实验结果表明,EasyTune在运动对齐方面优于DRaFT-50 8.2%(MM-Dist指标),同时仅需DRaFT-50 31.16%的额外内存开销,并实现了7.3倍的训练加速。这些数据充分证明了EasyTune在优化效率、内存消耗和性能方面的优势。
🎯 应用场景
EasyTune在运动生成领域具有广泛的应用前景,例如可以用于生成更逼真、更符合人类习惯的虚拟角色动画,也可以用于机器人运动规划,使机器人能够更自然、更高效地完成各种任务。此外,该方法还可以应用于其他基于扩散模型的生成任务,例如图像生成、音频生成等,具有重要的实际价值和潜在的未来影响。
📄 摘要(原文)
In recent years, motion generative models have undergone significant advancement, yet pose challenges in aligning with downstream objectives. Recent studies have shown that using differentiable rewards to directly align the preference of diffusion models yields promising results. However, these methods suffer from (1) inefficient and coarse-grained optimization with (2) high memory consumption. In this work, we first theoretically and empirically identify the key reason of these limitations: the recursive dependence between different steps in the denoising trajectory. Inspired by this insight, we propose EasyTune, which fine-tunes diffusion at each denoising step rather than over the entire trajectory. This decouples the recursive dependence, allowing us to perform (1) a dense and fine-grained, and (2) memory-efficient optimization. Furthermore, the scarcity of preference motion pairs restricts the availability of motion reward model training. To this end, we further introduce a Self-refinement Preference Learning (SPL) mechanism that dynamically identifies preference pairs and conducts preference learning. Extensive experiments demonstrate that EasyTune outperforms DRaFT-50 by 8.2% in alignment (MM-Dist) improvement while requiring only 31.16% of its additional memory overhead and achieving a 7.3x training speedup. The project page is available at this link {https://xiaofeng-tan.github.io/projects/EasyTune/index.html}.