Rethinking Practical and Efficient Quantization Calibration for Vision-Language Models
作者: Zhenhao Shang, Haizhao Jing, Guoting Wei, Haokui Zhang, Rong Xiao, Jianqing Gao, Peng Wang
分类: cs.CV
发布日期: 2026-02-08
💡 一句话要点
提出TLQ框架,解决视觉-语言模型量化校准中视觉和文本token差异问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 后训练量化 量化校准 token级别重要性 逐层量化
📋 核心要点
- 视觉-语言模型(VLM)中,视觉和文本token的差异给量化校准带来挑战,现有方法难以有效处理。
- TLQ框架通过梯度信息指导,设计token级别的重要性集成机制,构建细粒度的校准集,提升校准效果。
- TLQ采用多GPU逐层校准方案,与量化推理路径保持一致,并在多个模型和设置下验证了性能提升。
📝 摘要(中文)
后训练量化(PTQ)是部署大型语言模型而无需微调的主要方法,量化性能通常受到PTQ中校准的强烈影响。相比之下,在视觉-语言模型(VLM)中,视觉和文本token在激活分布和对量化误差的敏感性方面的显着差异,对PTQ期间的有效校准提出了重大挑战。在这项工作中,我们重新思考了VLM中PTQ校准应该对齐的内容,并提出了Token-level Importance-aware Layer-wise Quantization框架(TLQ)。在梯度信息的指导下,我们设计了一种token级别的重要性集成机制来处理量化误差,并使用它来构建token级别的校准集,从而实现更细粒度的校准策略。此外,TLQ引入了一种多GPU、量化暴露的逐层校准方案。该方案保持了逐层校准过程与真实量化推理路径的一致性,并将复杂的逐层校准工作负载分配到多个RTX3090 GPU上,从而减少了对A100 GPU大内存的依赖。TLQ在两个模型、三个模型规模和两个量化设置中进行了评估,在所有设置中都持续实现了性能改进,表明其强大的量化稳定性。代码将公开发布。
🔬 方法详解
问题定义:现有视觉-语言模型(VLM)的后训练量化(PTQ)方法在校准过程中面临挑战,主要原因是视觉和文本token在激活分布和对量化误差的敏感性上存在显著差异。传统的PTQ校准方法难以有效处理这种差异,导致量化后的模型性能下降。现有方法通常忽略了token级别的重要性,并且校准过程与实际量化推理路径不一致,限制了量化性能的提升。
核心思路:TLQ框架的核心思路是针对VLM中视觉和文本token的差异性,提出一种token级别的重要性感知的逐层量化校准方法。通过梯度信息来评估每个token的重要性,并据此构建token级别的校准集,从而实现更细粒度的校准策略。此外,TLQ还采用量化暴露的逐层校准方案,保证校准过程与实际量化推理路径的一致性。
技术框架:TLQ框架主要包含两个关键模块:token级别的重要性集成机制和多GPU量化暴露的逐层校准方案。首先,利用梯度信息计算每个token的重要性,并将其集成到量化误差的校准过程中。然后,基于token级别的重要性,构建一个更具代表性的校准集。其次,采用多GPU并行处理,加速逐层校准过程,并确保校准过程与实际量化推理路径一致。
关键创新:TLQ框架的关键创新在于:1) 提出了一种token级别的重要性集成机制,能够更准确地评估每个token对量化误差的影响;2) 构建了token级别的校准集,从而实现更细粒度的校准策略;3) 引入了多GPU量化暴露的逐层校准方案,保证校准过程与实际量化推理路径的一致性,并加速校准过程。
关键设计:在token级别的重要性集成机制中,使用梯度信息作为token重要性的度量标准。具体来说,计算每个token对应的梯度范数,并将其作为该token的重要性权重。在构建token级别的校准集时,根据token的重要性权重进行采样,选择对量化误差影响较大的token作为校准样本。在多GPU量化暴露的逐层校准方案中,将模型的不同层分配到不同的GPU上进行并行校准,并通过量化操作模拟实际的量化推理过程。
🖼️ 关键图片
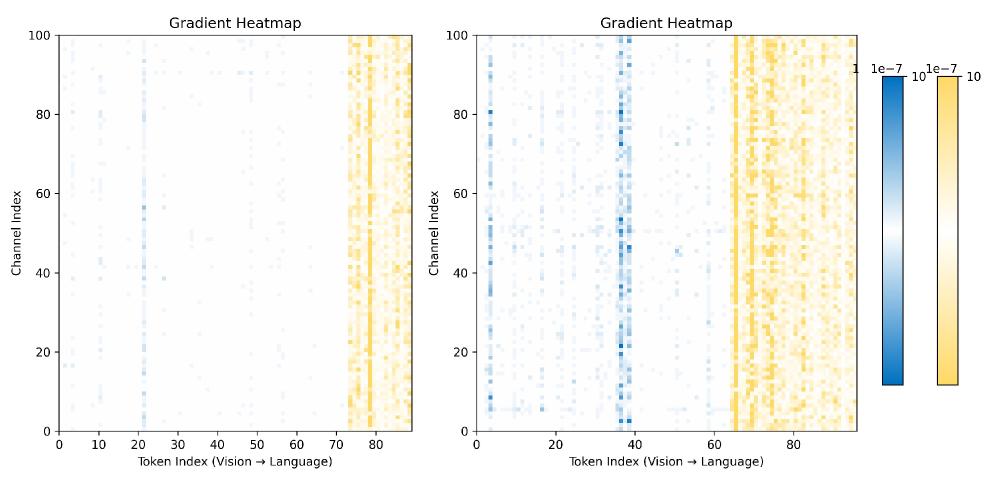
📊 实验亮点
TLQ框架在两个模型、三个模型规模和两个量化设置中进行了评估,实验结果表明,TLQ在所有设置中都持续实现了性能改进,证明了其强大的量化稳定性。具体性能提升数据在论文中给出,相较于基线方法,TLQ在各种VLM任务上均取得了显著的性能提升。
🎯 应用场景
TLQ框架可应用于各种视觉-语言模型的部署和加速,尤其是在资源受限的边缘设备上。通过降低模型大小和计算复杂度,TLQ能够提升VLM在移动设备、嵌入式系统等场景下的应用性能,例如图像描述、视觉问答、跨模态检索等任务。该研究有助于推动VLM在实际应用中的普及。
📄 摘要(原文)
Post-training quantization (PTQ) is a primary approach for deploying large language models without fine-tuning, and the quantized performance is often strongly affected by the calibration in PTQ. By contrast, in vision-language models (VLMs), substantial differences between visual and text tokens in their activation distributions and sensitivities to quantization error pose significant challenges for effective calibration during PTQ. In this work, we rethink what PTQ calibration should align with in VLMs and propose the Token-level Importance-aware Layer-wise Quantization framework (TLQ). Guided by gradient information, we design a token-level importance integration mechanism for quantization error, and use it to construct a token-level calibration set, enabling a more fine-grained calibration strategy. Furthermore, TLQ introduces a multi-GPU, quantization-exposed layer-wise calibration scheme. This scheme keeps the layer-wise calibration procedure consistent with the true quantized inference path and distributes the complex layer-wise calibration workload across multiple RTX3090 GPUs, thereby reducing reliance on the large memory of A100 GPUs. TLQ is evaluated across two models, three model scales, and two quantization settings, consistently achieving performance improvements across all settings, indicating its strong quantization stability. The code will be released publicly.