Geometry-Aware Rotary Position Embedding for Consistent Video World Model
作者: Chendong Xiang, Jiajun Liu, Jintao Zhang, Xiao Yang, Zhengwei Fang, Shizun Wang, Zijun Wang, Yingtian Zou, Hang Su, Jun Zhu
分类: cs.CV
发布日期: 2026-02-08 (更新: 2026-02-21)
💡 一句话要点
提出ViewRope,通过几何感知旋转位置编码提升视频世界模型长期一致性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视频世界模型 几何感知 旋转位置编码 长期一致性 Transformer 自注意力 机器人导航
📋 核心要点
- 现有视频世界模型在长序列上缺乏空间一致性,导致场景结构不稳定和重访位置时产生幻觉。
- ViewRope通过引入几何感知旋转位置编码,将相机射线方向融入Transformer自注意力,增强3D一致性。
- ViewBench诊断套件和实验结果表明,ViewRope显著提升了长期一致性,并降低了计算成本。
📝 摘要(中文)
预测性世界模型在显式相机控制下模拟未来观测,对交互式AI至关重要。然而,现有系统缺乏空间持久性,难以在长轨迹上维持稳定的场景结构,并且在相机重访先前观测位置时频繁产生幻觉细节。该问题源于对屏幕空间位置嵌入的依赖,这与3D一致性所需的投影几何相冲突。论文提出ViewRope,一种几何感知编码,将相机射线方向直接注入视频Transformer的自注意力层。通过用相对射线几何而非像素局部性来参数化注意力,ViewRope为模型提供了一种原生的归纳偏置,用于跨时间间隔检索3D一致的内容。此外,论文还提出了几何感知帧稀疏注意力,利用这些几何线索选择性地关注相关的历史帧,从而提高效率而不牺牲记忆一致性。同时,论文提出了ViewBench,一个用于测量循环闭合保真度和几何漂移的诊断套件。实验结果表明,ViewRope在降低计算成本的同时,显著提高了长期一致性。
🔬 方法详解
问题定义:现有视频世界模型在模拟未来观测时,尤其是在长序列和相机运动复杂的场景中,难以保持场景的空间一致性。具体表现为,模型容易产生几何漂移,即对同一场景的不同视角产生不一致的渲染结果,导致在循环闭合等任务中表现不佳。现有方法依赖于屏幕空间的位置编码,这与3D空间的投影几何不兼容,是造成几何漂移的根本原因。
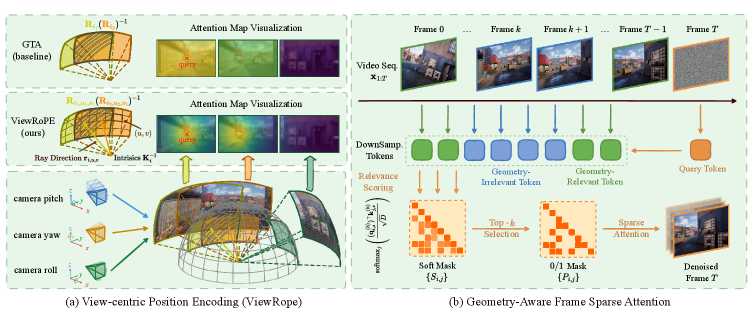
核心思路:ViewRope的核心思路是将相机的几何信息(即相机射线方向)直接编码到Transformer的自注意力机制中,从而使模型能够感知场景的3D结构。通过使用相对射线几何而非像素局部性来参数化注意力,ViewRope为模型提供了一种原生的归纳偏置,使其能够更好地理解和维护场景的3D一致性。这种方法避免了屏幕空间位置编码带来的几何失真问题。
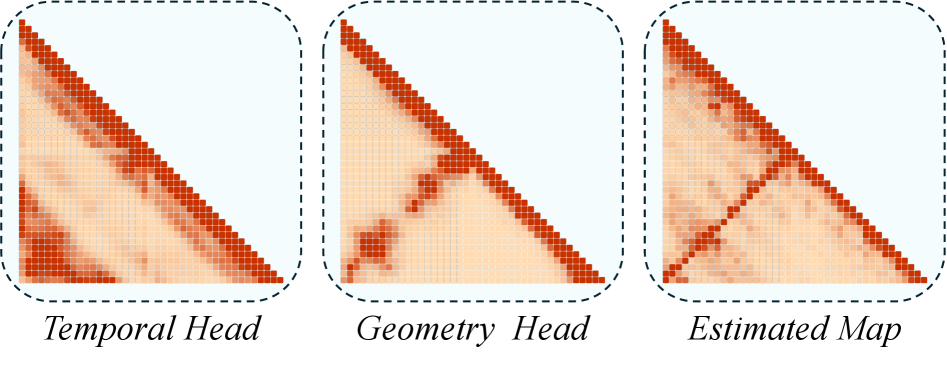
技术框架:ViewRope的整体框架是在视频Transformer的自注意力层中引入几何感知的旋转位置编码。具体来说,对于每个像素,模型计算其对应的相机射线方向,并将这些方向信息编码成旋转矩阵。然后,这些旋转矩阵被用于调整自注意力机制中的查询(Query)和键(Key)向量,从而使注意力权重能够反映像素之间的相对几何关系。此外,论文还提出了几何感知帧稀疏注意力,根据几何相似性选择性地关注历史帧,以提高效率。
关键创新:ViewRope最重要的技术创新在于其几何感知的旋转位置编码。与传统的屏幕空间位置编码不同,ViewRope直接利用相机射线方向来参数化注意力,从而使模型能够更好地理解场景的3D结构。这种方法避免了屏幕空间位置编码带来的几何失真问题,并为模型提供了一种原生的归纳偏置,使其能够更好地维护场景的3D一致性。
关键设计:ViewRope的关键设计包括:1) 使用旋转矩阵来编码相机射线方向,以便于在自注意力机制中进行操作;2) 设计了几何感知帧稀疏注意力,根据几何相似性选择性地关注历史帧,以提高效率;3) 提出了ViewBench,一个用于测量循环闭合保真度和几何漂移的诊断套件,用于评估模型的性能。具体的参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
实验结果表明,ViewRope在多个基准测试中显著提高了视频世界模型的长期一致性。例如,在循环闭合任务中,ViewRope的性能优于现有方法,并且能够有效地减少几何漂移。此外,ViewRope的几何感知帧稀疏注意力机制在提高效率的同时,并没有牺牲记忆一致性。ViewBench诊断套件为评估视频世界模型的长期一致性提供了一个新的标准。
🎯 应用场景
ViewRope在机器人导航、增强现实、虚拟现实等领域具有广泛的应用前景。通过提高视频世界模型的长期一致性,ViewRope可以帮助机器人更好地理解和导航复杂环境,并为用户提供更逼真和沉浸式的AR/VR体验。此外,ViewRope还可以应用于视频编辑、三维重建等领域,提高相关任务的性能和效率。
📄 摘要(原文)
Predictive world models that simulate future observations under explicit camera control are fundamental to interactive AI. Despite rapid advances, current systems lack spatial persistence: they fail to maintain stable scene structures over long trajectories, frequently hallucinating details when cameras revisit previously observed locations. We identify that this geometric drift stems from reliance on screen-space positional embeddings, which conflict with the projective geometry required for 3D consistency. We introduce \textbf{ViewRope}, a geometry-aware encoding that injects camera-ray directions directly into video transformer self-attention layers. By parameterizing attention with relative ray geometry rather than pixel locality, ViewRope provides a model-native inductive bias for retrieving 3D-consistent content across temporal gaps. We further propose \textbf{Geometry-Aware Frame-Sparse Attention}, which exploits these geometric cues to selectively attend to relevant historical frames, improving efficiency without sacrificing memory consistency. We also present \textbf{ViewBench}, a diagnostic suite measuring loop-closure fidelity and geometric drift. Our results demonstrate that ViewRope substantially improves long-term consistency while reducing computational costs.