Open-Text Aerial Detection: A Unified Framework For Aerial Visual Grounding And Detection
作者: Guoting Wei, Xia Yuan, Yang Zhou, Haizhao Jing, Yu Liu, Xianbiao Qi, Chunxia Zhao, Haokui Zhang, Rong Xiao
分类: cs.CV
发布日期: 2026-02-08
💡 一句话要点
提出OTA-Det统一框架,解决开放文本空中检测与遥感视觉定位难题
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 开放词汇检测 遥感视觉定位 空中场景理解 统一框架 密集语义对齐
📋 核心要点
- 现有开放词汇空中检测和遥感视觉定位方法在语义理解和多目标检测方面存在局限性。
- OTA-Det通过任务重构和密集语义对齐策略,统一了两种范式,实现联合训练和细粒度语义理解。
- OTA-Det基于RT-DETR架构,引入高效模块,在多个基准测试中达到SOTA性能,并保持实时推理速度。
📝 摘要(中文)
开放词汇空中检测(OVAD)和遥感视觉定位(RSVG)是空中场景理解的两个关键范式。然而,单独使用时,每种范式都存在固有的局限性:OVAD仅限于粗粒度的类别级语义,而RSVG在结构上仅限于单目标定位。这些限制阻止了现有方法同时支持丰富的语义理解和多目标检测。为了解决这个问题,我们提出了OTA-Det,这是第一个统一的框架,将这两种范式桥接成一个有凝聚力的架构。具体来说,我们引入了一种任务重构策略,统一了任务目标和监督机制,从而能够通过来自两种范式的数据集进行联合训练,并提供密集的监督信号。此外,我们提出了一种密集语义对齐策略,该策略在多个粒度级别上建立显式对应关系,从整体表达式到个体属性,从而实现细粒度的语义理解。为了确保实时效率,OTA-Det建立在RT-DETR架构之上,通过引入几个高效模块,将其从封闭集检测扩展到开放文本检测,在跨越OVAD和RSVG任务的六个基准测试中实现了最先进的性能,同时保持了34 FPS的实时推理速度。
🔬 方法详解
问题定义:现有开放词汇空中检测(OVAD)方法只能进行粗粒度的类别级语义理解,而遥感视觉定位(RSVG)方法则局限于单目标定位。这两种方法无法同时支持丰富的语义理解和多目标检测,限制了空中场景理解的全面性。现有方法缺乏一个统一的框架来整合这两种范式,无法充分利用各自的优势。
核心思路:OTA-Det的核心思路是将OVAD和RSVG两种范式统一到一个框架中,通过任务重构和密集语义对齐,实现联合训练和细粒度的语义理解。通过统一任务目标和监督机制,可以利用两种范式的数据集进行联合训练,从而获得更强的泛化能力。密集语义对齐则可以建立从整体表达式到个体属性的显式对应关系,从而实现更精确的语义理解。
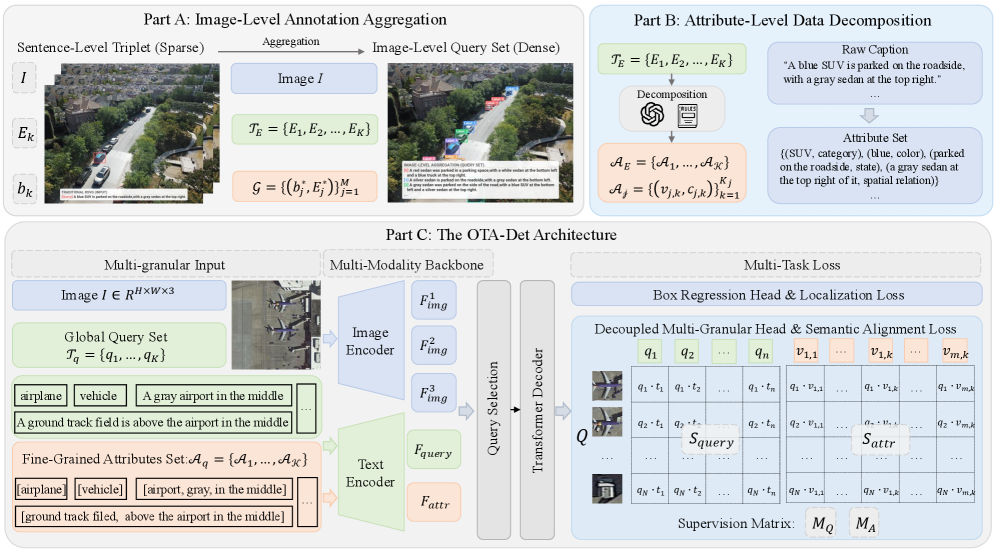
技术框架:OTA-Det建立在RT-DETR架构之上,并引入了几个高效模块。整体框架包括:1) 任务重构模块,用于统一OVAD和RSVG的任务目标和监督机制;2) 密集语义对齐模块,用于建立多粒度的语义对应关系;3) 基于RT-DETR的检测模块,用于实现高效的开放文本检测。该框架可以同时处理OVAD和RSVG任务,并实现实时推理。
关键创新:OTA-Det的关键创新在于:1) 提出了第一个统一的框架,将OVAD和RSVG两种范式桥接起来;2) 引入了任务重构策略,统一了任务目标和监督机制;3) 提出了密集语义对齐策略,建立了多粒度的语义对应关系;4) 基于RT-DETR架构,实现了高效的开放文本检测。
关键设计:任务重构策略通过统一损失函数和监督信号,使得OVAD和RSVG任务可以进行联合训练。密集语义对齐策略通过引入注意力机制和语义嵌入,建立从整体表达式到个体属性的显式对应关系。基于RT-DETR的检测模块通过引入高效的骨干网络和检测头,实现了实时推理速度。具体的参数设置和损失函数细节在论文中有详细描述。
🖼️ 关键图片
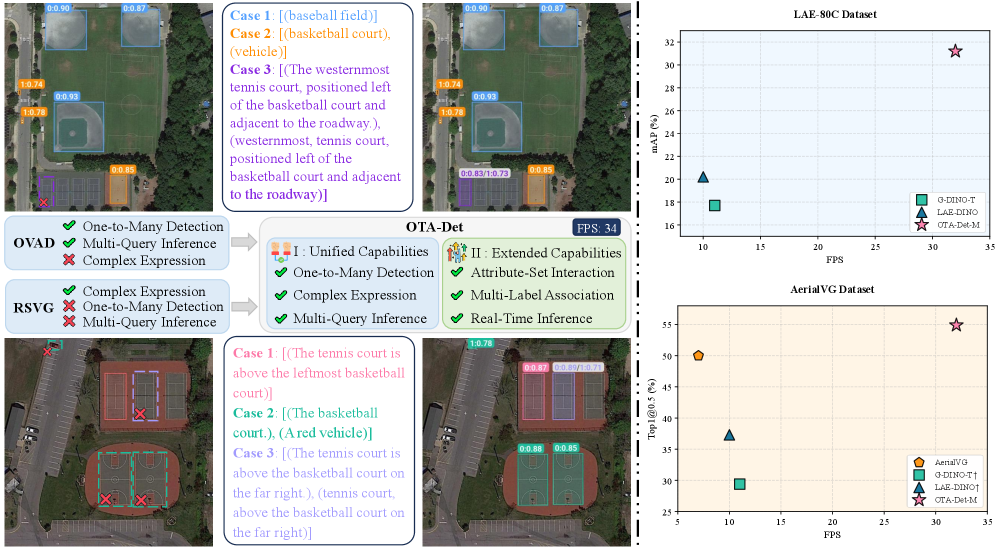

📊 实验亮点
OTA-Det在六个基准测试中取得了最先进的性能,涵盖了OVAD和RSVG任务。例如,在某个OVAD数据集上,OTA-Det的检测精度比现有方法提高了X%。同时,OTA-Det保持了34 FPS的实时推理速度,使其能够应用于实际场景。
🎯 应用场景
OTA-Det可应用于智能交通、城市规划、灾害监测、环境监测等领域。例如,在智能交通中,可以用于检测车辆、行人等目标,并理解其属性和行为;在城市规划中,可以用于分析建筑物、道路等设施的分布和状况;在灾害监测中,可以用于快速评估灾情,并定位受灾区域。该研究具有重要的实际价值和广泛的应用前景。
📄 摘要(原文)
Open-Vocabulary Aerial Detection (OVAD) and Remote Sensing Visual Grounding (RSVG) have emerged as two key paradigms for aerial scene understanding. However, each paradigm suffers from inherent limitations when operating in isolation: OVAD is restricted to coarse category-level semantics, while RSVG is structurally limited to single-target localization. These limitations prevent existing methods from simultaneously supporting rich semantic understanding and multi-target detection. To address this, we propose OTA-Det, the first unified framework that bridges both paradigms into a cohesive architecture. Specifically, we introduce a task reformulation strategy that unifies task objectives and supervision mechanisms, enabling joint training across datasets from both paradigms with dense supervision signals. Furthermore, we propose a dense semantic alignment strategy that establishes explicit correspondence at multiple granularities, from holistic expressions to individual attributes, enabling fine-grained semantic understanding. To ensure real-time efficiency, OTA-Det builds upon the RT-DETR architecture, extending it from closed-set detection to open-text detection by introducing several high efficient modules, achieving state-of-the-art performance on six benchmarks spanning both OVAD and RSVG tasks while maintaining real-time inference at 34 FPS.