PAND: Prompt-Aware Neighborhood Distillation for Lightweight Fine-Grained Visual Classification
作者: Qiuming Luo, Yuebing Li, Feng Li, Chang Kong
分类: cs.CV, cs.AI, cs.LG, cs.MM
发布日期: 2026-02-08
备注: 6pages, 3 figures, conference
🔗 代码/项目: GITHUB
💡 一句话要点
提出PAND:提示感知邻域蒸馏,用于轻量级细粒度图像分类
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 细粒度视觉分类 知识蒸馏 视觉-语言模型 提示学习 邻域蒸馏
📋 核心要点
- 现有细粒度视觉分类方法依赖固定提示和全局对齐,难以有效利用大规模视觉-语言模型的知识。
- PAND框架通过提示感知语义校准生成自适应语义锚点,并利用邻域感知结构蒸馏约束学生网络的局部决策结构。
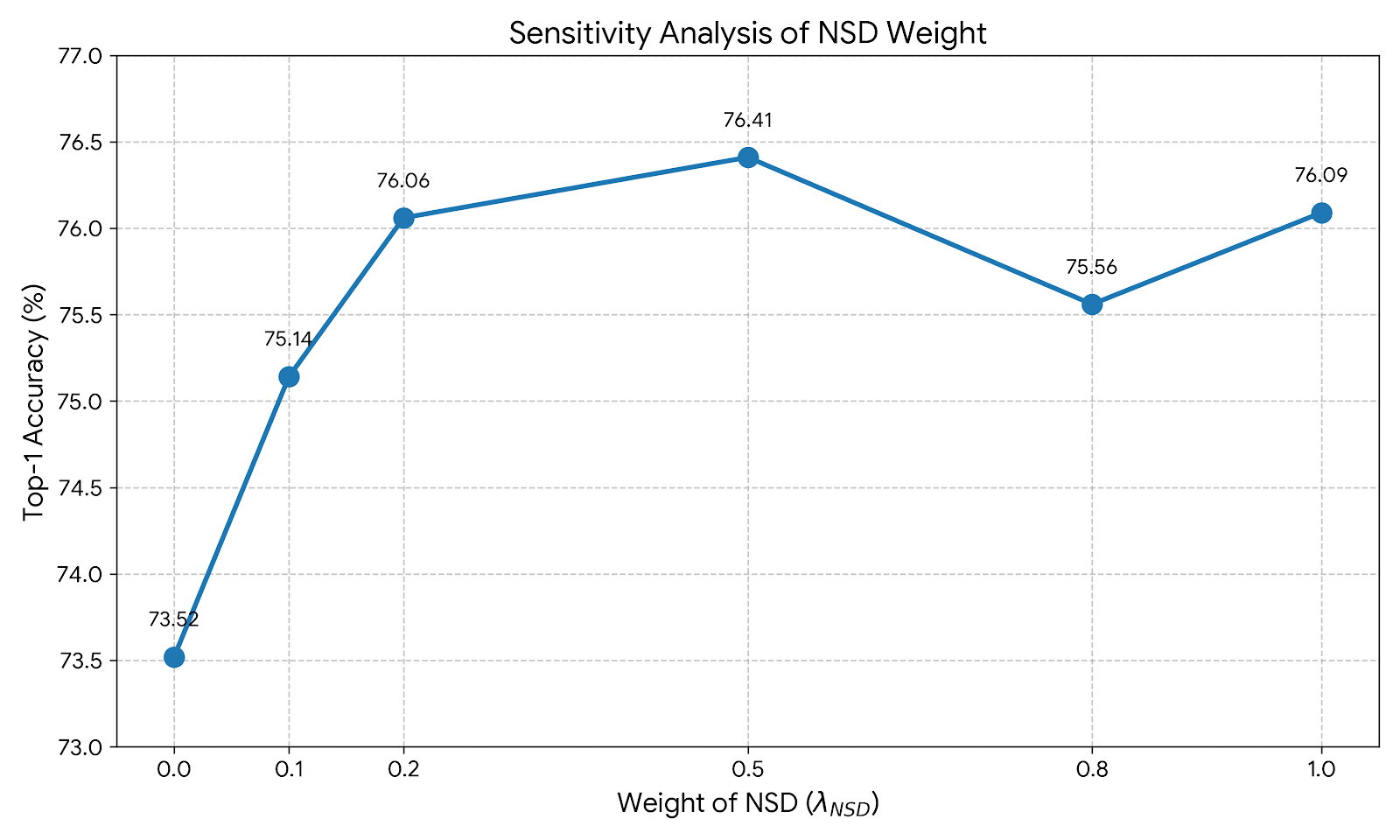
- 实验表明,PAND在多个细粒度视觉分类数据集上超越现有方法,ResNet-18在CUB-200上达到76.09%的准确率。
📝 摘要(中文)
在大规模视觉-语言模型(VLMs)中提取知识到轻量级网络对于细粒度视觉分类(FGVC)至关重要,但也极具挑战,因为其依赖于固定的提示和全局对齐。为了解决这个问题,我们提出了PAND(Prompt-Aware Neighborhood Distillation),这是一个两阶段框架,将语义校准与结构转移解耦。首先,我们结合提示感知语义校准来生成自适应语义锚点。其次,我们引入了一种邻域感知结构蒸馏策略来约束学生网络的局部决策结构。PAND在四个FGVC基准测试中始终优于最先进的方法。值得注意的是,我们的ResNet-18学生网络在CUB-200上实现了76.09%的准确率,超过了强大的基线VL2Lite 3.4%。代码可在https://github.com/LLLVTA/PAND获取。
🔬 方法详解
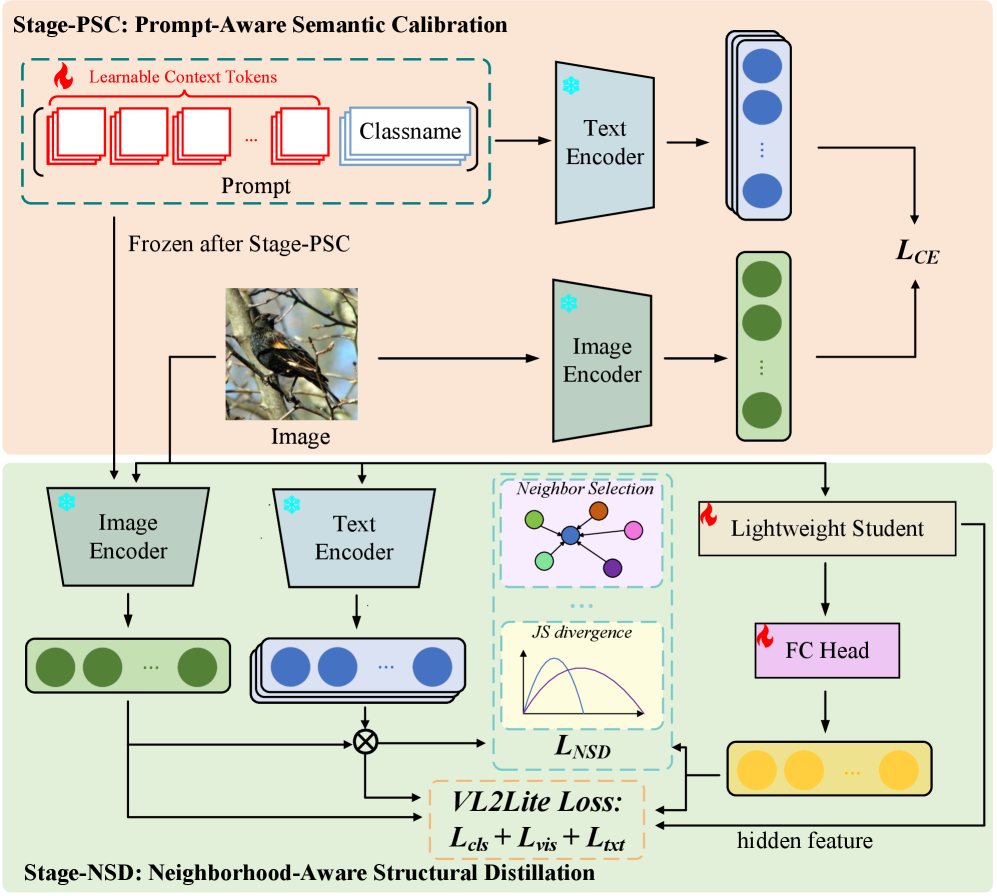
问题定义:细粒度视觉分类(FGVC)旨在区分属于同一大类的细微视觉差异。现有方法通常依赖于固定的文本提示,无法充分利用大规模视觉-语言模型(VLMs)的知识。此外,全局对齐忽略了局部结构信息,限制了知识迁移的效率。因此,如何有效地将VLMs的知识蒸馏到轻量级网络,同时关注局部结构,是FGVC面临的关键问题。
核心思路:PAND的核心思路是将知识蒸馏过程解耦为语义校准和结构转移两个阶段。首先,通过提示感知语义校准,使学生网络能够适应不同的语义环境,生成更具判别性的语义锚点。其次,通过邻域感知结构蒸馏,约束学生网络的局部决策结构,使其能够更好地模仿教师网络的行为。这种解耦的方式能够更有效地利用VLMs的知识,并提高学生网络的性能。
技术框架:PAND框架包含两个主要阶段:提示感知语义校准和邻域感知结构蒸馏。在提示感知语义校准阶段,首先利用VLMs生成图像的语义表示,然后通过自适应提示学习模块,生成针对特定图像的提示。这些提示用于指导学生网络学习更具判别性的语义特征。在邻域感知结构蒸馏阶段,首先构建教师网络和学生网络的特征邻域图,然后利用结构蒸馏损失,约束学生网络的局部决策结构与教师网络保持一致。
关键创新:PAND的关键创新在于提出了提示感知语义校准和邻域感知结构蒸馏两种策略。提示感知语义校准能够使学生网络适应不同的语义环境,生成更具判别性的语义特征。邻域感知结构蒸馏能够约束学生网络的局部决策结构,使其能够更好地模仿教师网络的行为。与现有方法相比,PAND能够更有效地利用VLMs的知识,并提高学生网络的性能。
关键设计:在提示感知语义校准阶段,使用了可学习的提示嵌入,通过注意力机制与图像特征进行融合,生成自适应提示。在邻域感知结构蒸馏阶段,使用了KL散度作为结构蒸馏损失,用于衡量教师网络和学生网络特征邻域图之间的差异。此外,还使用了对比学习损失,用于增强学生网络特征的判别性。
🖼️ 关键图片

📊 实验亮点
PAND在CUB-200、Stanford Dogs、NABirds和iNaturalist 2018四个细粒度视觉分类基准测试中均取得了显著的性能提升。特别是在CUB-200数据集上,使用ResNet-18作为学生网络时,PAND达到了76.09%的准确率,超过了强大的基线VL2Lite 3.4%。实验结果表明,PAND能够有效利用大规模视觉-语言模型的知识,提高轻量级网络的性能。
🎯 应用场景
PAND框架可应用于各种细粒度图像分类任务,例如鸟类识别、车型识别、植物识别等。该方法能够有效利用大规模视觉-语言模型的知识,提高轻量级网络的性能,从而在资源受限的场景下实现高效的细粒度图像分类。未来,该方法可以进一步扩展到其他视觉任务,例如目标检测、图像分割等。
📄 摘要(原文)
Distilling knowledge from large Vision-Language Models (VLMs) into lightweight networks is crucial yet challenging in Fine-Grained Visual Classification (FGVC), due to the reliance on fixed prompts and global alignment. To address this, we propose PAND (Prompt-Aware Neighborhood Distillation), a two-stage framework that decouples semantic calibration from structural transfer. First, we incorporate Prompt-Aware Semantic Calibration to generate adaptive semantic anchors. Second, we introduce a neighborhood-aware structural distillation strategy to constrain the student's local decision structure. PAND consistently outperforms state-of-the-art methods on four FGVC benchmarks. Notably, our ResNet-18 student achieves 76.09% accuracy on CUB-200, surpassing the strong baseline VL2Lite by 3.4%. Code is available at https://github.com/LLLVTA/PAND.