Fine-R1: Make Multi-modal LLMs Excel in Fine-Grained Visual Recognition by Chain-of-Thought Reasoning
作者: Hulingxiao He, Zijun Geng, Yuxin Peng
分类: cs.CV, cs.AI
发布日期: 2026-02-07 (更新: 2026-02-10)
备注: Published as a conference paper at ICLR 2026. The models are available at https://huggingface.co/collections/StevenHH2000/fine-r1
🔗 代码/项目: GITHUB
💡 一句话要点
Fine-R1:通过思维链推理提升多模态LLM在细粒度视觉识别中的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 细粒度视觉识别 多模态大语言模型 思维链推理 策略优化 小样本学习
📋 核心要点
- 现有MLLM在细粒度视觉识别上表现不足,且需要大量标注数据,泛化能力差,限制了其应用。
- Fine-R1通过思维链监督微调和三重增强策略优化,提升MLLM在细粒度视觉识别上的性能和泛化能力。
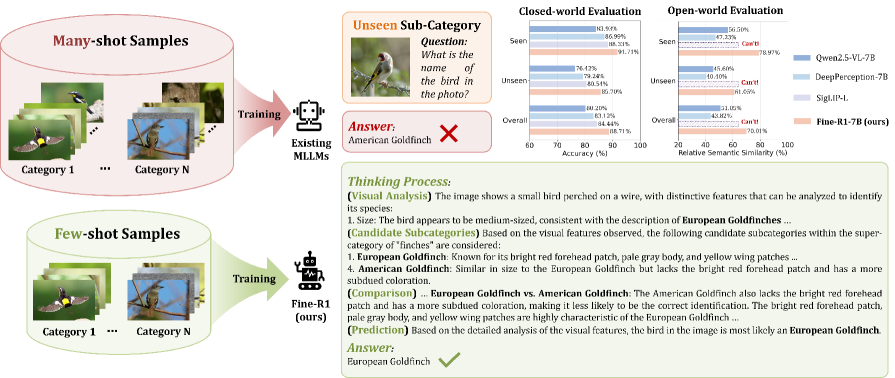
- 实验表明,Fine-R1仅用少量样本训练,即可超越现有MLLM和CLIP模型,在已见和未见类别上均有提升。
📝 摘要(中文)
视觉世界中的任何实体都可以根据共享特征进行分层分组,并映射到细粒度的子类别。多模态大型语言模型(MLLM)在粗粒度视觉任务上表现出色,但在细粒度视觉识别(FGVR)方面却表现不佳。将通用MLLM适配到FGVR通常需要大量的标注数据,这导致获取成本高昂,与专用于判别任务的对比CLIP模型相比,存在显著的性能差距。此外,MLLM容易过度拟合已见过的子类别,并且对未见过的子类别泛化能力较差。为了解决这些挑战,我们提出了Fine-R1,这是一种通过R1风格的训练框架为FGVR量身定制的MLLM:(1)思维链监督微调,我们构建了一个高质量的FGVR CoT数据集,其中包含“视觉分析、候选子类别、比较和预测”的原理,将模型转变为强大的开放世界分类器;(2)三重增强策略优化,其中类内增强混合来自同一类别内的锚图像和正图像的轨迹,以提高对类内方差的鲁棒性,而类间增强最大化跨子类别的图像的响应区分,以增强判别能力。仅使用4-shot训练,Fine-R1在识别已见和未见的子类别方面均优于现有的通用MLLM、推理MLLM,甚至对比CLIP模型,显示出在知识密集型领域工作的潜力,在这些领域中,为所有子类别收集专家注释非常困难。
🔬 方法详解
问题定义:论文旨在解决多模态大型语言模型(MLLM)在细粒度视觉识别(FGVR)任务中的不足。现有方法要么需要大量标注数据,成本高昂;要么容易过拟合已见过的类别,泛化能力差。这限制了MLLM在需要精细区分的视觉任务中的应用。
核心思路:论文的核心思路是通过思维链(Chain-of-Thought, CoT)推理和策略优化,引导MLLM学习细粒度的视觉特征和判别能力。CoT推理使得模型能够逐步分析图像,比较候选类别,最终做出预测,从而提高识别的准确性。策略优化则通过增强类内鲁棒性和类间区分性,提高模型的泛化能力。
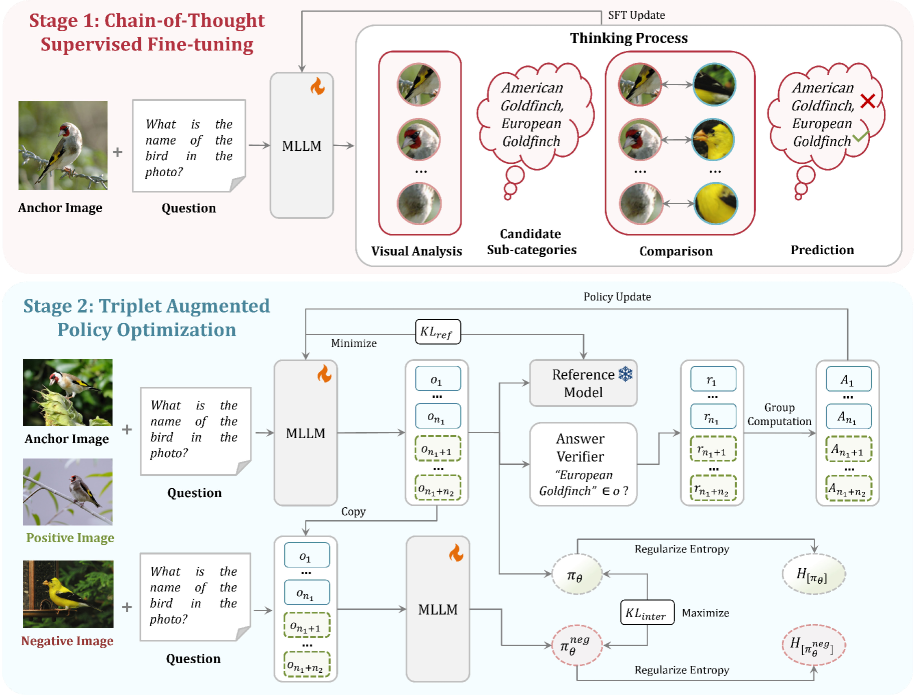
技术框架:Fine-R1的训练框架包含两个主要阶段:(1)思维链监督微调(Chain-of-Thought Supervised Fine-tuning):构建包含视觉分析、候选子类别、比较和预测等推理步骤的CoT数据集,并使用该数据集对MLLM进行微调,使其具备CoT推理能力。(2)三重增强策略优化(Triplet Augmented Policy Optimization):使用强化学习方法,通过类内增强和类间增强,优化模型的策略,提高其鲁棒性和判别能力。
关键创新:论文的关键创新在于将思维链推理和策略优化相结合,用于提升MLLM在细粒度视觉识别中的性能。传统的MLLM通常直接将图像映射到类别标签,而Fine-R1通过CoT推理,模拟人类专家的思考过程,从而更好地理解图像内容。此外,三重增强策略优化能够有效地提高模型的泛化能力,使其能够识别未见过的类别。
关键设计:在思维链监督微调阶段,论文精心设计了CoT数据集,包含了详细的视觉分析、候选子类别、比较和预测等步骤。在三重增强策略优化阶段,论文采用了类内增强和类间增强两种策略。类内增强通过混合同一类别内的图像,提高模型对类内差异的鲁棒性。类间增强则通过最大化不同类别图像之间的响应差异,提高模型的判别能力。具体的损失函数和网络结构细节在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
Fine-R1在4-shot训练下,超越了现有的通用MLLM、推理MLLM以及对比CLIP模型,在已见和未见子类别的识别上均取得了显著的性能提升。这表明Fine-R1在数据稀缺的情况下,依然能够有效地学习细粒度的视觉特征,并具备良好的泛化能力,验证了所提出方法的有效性。
🎯 应用场景
Fine-R1在生物物种识别、医学图像诊断、工业产品缺陷检测等领域具有广泛的应用前景。该方法能够有效提升机器在细粒度视觉任务中的识别精度和泛化能力,降低对大量标注数据的依赖,从而加速相关领域的智能化进程,具有重要的实际应用价值和未来发展潜力。
📄 摘要(原文)
Any entity in the visual world can be hierarchically grouped based on shared characteristics and mapped to fine-grained sub-categories. While Multi-modal Large Language Models (MLLMs) achieve strong performance on coarse-grained visual tasks, they often struggle with Fine-Grained Visual Recognition (FGVR). Adapting general-purpose MLLMs to FGVR typically requires large amounts of annotated data, which is costly to obtain, leaving a substantial performance gap compared to contrastive CLIP models dedicated for discriminative tasks. Moreover, MLLMs tend to overfit to seen sub-categories and generalize poorly to unseen ones. To address these challenges, we propose Fine-R1, an MLLM tailored for FGVR through an R1-style training framework: (1) Chain-of-Thought Supervised Fine-tuning, where we construct a high-quality FGVR CoT dataset with rationales of "visual analysis, candidate sub-categories, comparison, and prediction", transition the model into a strong open-world classifier; and (2) Triplet Augmented Policy Optimization, where Intra-class Augmentation mixes trajectories from anchor and positive images within the same category to improve robustness to intra-class variance, while Inter-class Augmentation maximizes the response distinction conditioned on images across sub-categories to enhance discriminative ability. With only 4-shot training, Fine-R1 outperforms existing general MLLMs, reasoning MLLMs, and even contrastive CLIP models in identifying both seen and unseen sub-categories, showing promise in working in knowledge-intensive domains where gathering expert annotations for all sub-categories is arduous. Code is available at https://github.com/PKU-ICST-MIPL/FineR1_ICLR2026.