TeleBoost: A Systematic Alignment Framework for High-Fidelity, Controllable, and Robust Video Generation
作者: Yuanzhi Liang, Xuan'er Wu, Yirui Liu, Yijie Fang, Yizhen Fan, Ke Hao, Rui Li, Ruiying Liu, Ziqi Ni, Peng Yu, Yanbo Wang, Haibin Huang, Qizhen Weng, Chi Zhang, Xuelong Li
分类: cs.CV, cs.AI
发布日期: 2026-02-07
💡 一句话要点
TeleBoost:用于高保真、可控和鲁棒视频生成的系统对齐框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频生成 后训练 强化学习 监督学习 偏好学习 时间一致性 可控性
📋 核心要点
- 现有视频生成模型在长时序一致性、指令遵循和可控性方面存在不足,难以直接应用于实际生产环境。
- TeleBoost框架通过整合监督策略塑造、强化学习和偏好细化,构建了一个稳定性约束的优化堆栈,提升视频生成质量。
- 该框架着重解决视频生成中的高rollout成本、时序累积误差以及反馈异构性等实际问题,提升模型在真实场景下的性能。
📝 摘要(中文)
本文提出了一种系统的后训练框架,旨在将预训练的视频生成器转化为面向生产的模型,使其能够遵循指令、具有可控性,并在长时间范围内保持鲁棒性。该框架将监督策略塑造、奖励驱动的强化学习和基于偏好的细化整合到一个单一的、具有稳定性约束的优化堆栈中。该框架围绕实际的视频生成约束进行设计,包括高昂的 rollout 成本、时间上累积的失败模式,以及异构、不确定且通常弱区分性的反馈。通过将优化视为一个分阶段的、诊断驱动的过程,而不是一系列孤立的技巧,本文总结了一个连贯的方案,用于提高感知保真度、时间一致性和提示遵循性,同时保留初始化时建立的可控性。最终的框架为构建可扩展的后训练流水线提供了一个清晰的蓝图,该流水线在实际部署环境中保持稳定、可扩展和有效。
🔬 方法详解
问题定义:现有的视频生成模型,即使经过预训练,仍然难以满足实际应用的需求。它们在生成长视频时容易出现时间不一致性,对指令的遵循程度不高,并且缺乏足够的可控性。此外,训练这些模型通常需要大量的计算资源和时间,尤其是在处理长视频时,rollout成本非常高。反馈信号通常是异构的、不确定的,并且区分度不高,这使得训练过程更加困难。
核心思路:TeleBoost的核心思路是将后训练过程视为一个系统性的对齐过程,而不是一系列孤立的技巧。它将监督策略塑造、奖励驱动的强化学习和基于偏好的细化整合到一个统一的优化框架中。通过这种方式,可以逐步地提高模型的性能,同时保持训练的稳定性。该框架特别关注实际视频生成中的约束,如高rollout成本、时间上的累积误差以及反馈的异构性。
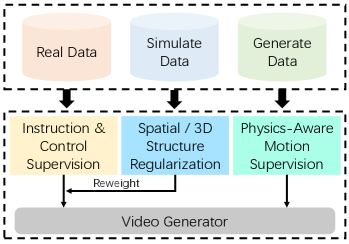
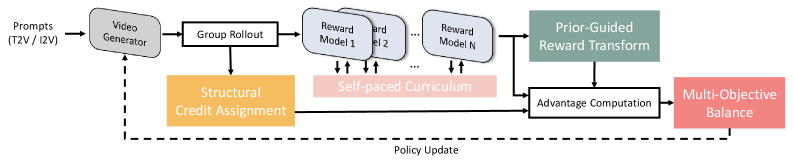
技术框架:TeleBoost框架包含三个主要的阶段:监督策略塑造、奖励驱动的强化学习和基于偏好的细化。首先,使用监督学习来引导模型生成符合指令的视频。然后,使用强化学习来优化模型的长期性能,并解决时间上的累积误差。最后,使用基于偏好的细化来进一步提高视频的质量,并使其更符合人类的偏好。整个框架采用稳定性约束的优化堆栈,以确保训练过程的稳定性和可扩展性。
关键创新:TeleBoost的关键创新在于其系统性的对齐框架,它将多种训练方法整合到一个统一的优化过程中。与传统的孤立地应用各种技巧的方法不同,TeleBoost将后训练视为一个整体,并针对实际视频生成中的约束进行优化。此外,该框架还引入了稳定性约束,以确保训练过程的稳定性和可扩展性。
关键设计:TeleBoost框架的关键设计包括:(1) 使用监督学习来初始化模型的策略,使其能够生成符合指令的视频;(2) 使用奖励函数来衡量模型的长期性能,并指导强化学习过程;(3) 使用基于偏好的细化来进一步提高视频的质量,并使其更符合人类的偏好;(4) 引入稳定性约束,以确保训练过程的稳定性和可扩展性。具体的参数设置、损失函数和网络结构等细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
摘要中未提供具体的实验数据或对比基线。但该框架旨在提高视频生成的感知保真度、时间一致性和提示遵循性,同时保留初始化时建立的可控性。通过系统性的对齐框架,有望在这些方面取得显著的提升,并为构建可扩展的后训练流水线提供清晰的蓝图。
🎯 应用场景
TeleBoost框架可应用于各种视频生成场景,如电影制作、游戏开发、广告创意等。它可以帮助用户快速生成高质量、可控且符合特定需求的视频内容,降低视频制作的成本和时间。该框架的鲁棒性和可扩展性使其能够适应不同的应用场景和数据规模,具有广阔的应用前景。
📄 摘要(原文)
Post-training is the decisive step for converting a pretrained video generator into a production-oriented model that is instruction-following, controllable, and robust over long temporal horizons. This report presents a systematical post-training framework that organizes supervised policy shaping, reward-driven reinforcement learning, and preference-based refinement into a single stability-constrained optimization stack. The framework is designed around practical video-generation constraints, including high rollout cost, temporally compounding failure modes, and feedback that is heterogeneous, uncertain, and often weakly discriminative. By treating optimization as a staged, diagnostic-driven process rather than a collection of isolated tricks, the report summarizes a cohesive recipe for improving perceptual fidelity, temporal coherence, and prompt adherence while preserving the controllability established at initialization. The resulting framework provides a clear blueprint for building scalable post-training pipelines that remain stable, extensible, and effective in real-world deployment settings.