ViCA: Efficient Multimodal LLMs with Vision-Only Cross-Attention
作者: Wenjie Liu, Hao Wu, Xin Qiu, Yingqi Fan, Yihan Zhang, Anhao Zhao, Yunpu Ma, Xiaoyu Shen
分类: cs.CV, cs.CL
发布日期: 2026-02-07
🔗 代码/项目: GITHUB
💡 一句话要点
ViCA:提出视觉信息仅通过交叉注意力交互的高效多模态大语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉语言交互 交叉注意力 模型压缩 高效推理
📋 核心要点
- 现有MLLM在每层Transformer中密集处理视觉信息,计算开销巨大,效率低下。
- ViCA架构让视觉tokens绕过自注意力和前馈层,仅在特定层通过交叉注意力与文本交互。
- 实验表明,ViCA在保持精度的前提下,显著降低了视觉侧的计算量,并加速了推理过程。
📝 摘要(中文)
现代多模态大语言模型(MLLMs)采用统一的自注意力机制,在每个Transformer层处理视觉和文本tokens,导致巨大的计算开销。本文重新审视了这种密集视觉处理的必要性,并表明投影的视觉嵌入已经与语言空间很好地对齐,而有效的视觉-语言交互仅发生在少数层中。基于这些见解,我们提出了ViCA(Vision-only Cross-Attention),一种最小的MLLM架构,其中视觉tokens绕过所有自注意力和前馈层,仅通过在选定层中的稀疏交叉注意力与文本交互。在三个MLLM骨干网络、九个多模态基准测试和26个基于剪枝的基线的广泛评估表明,ViCA保留了98%的基线精度,同时将视觉侧计算量减少到4%,始终实现卓越的性能-效率权衡。此外,ViCA提供了一个规则的、硬件友好的推理流水线,在单批次推理中产生超过3.5倍的加速,在多批次推理中产生超过10倍的加速,与纯文本LLM相比,将视觉 grounding 降低到接近零的开销。它也与token剪枝方法正交,并且可以无缝组合以获得进一步的效率提升。我们的代码可在https://github.com/EIT-NLP/ViCA 获得。
🔬 方法详解
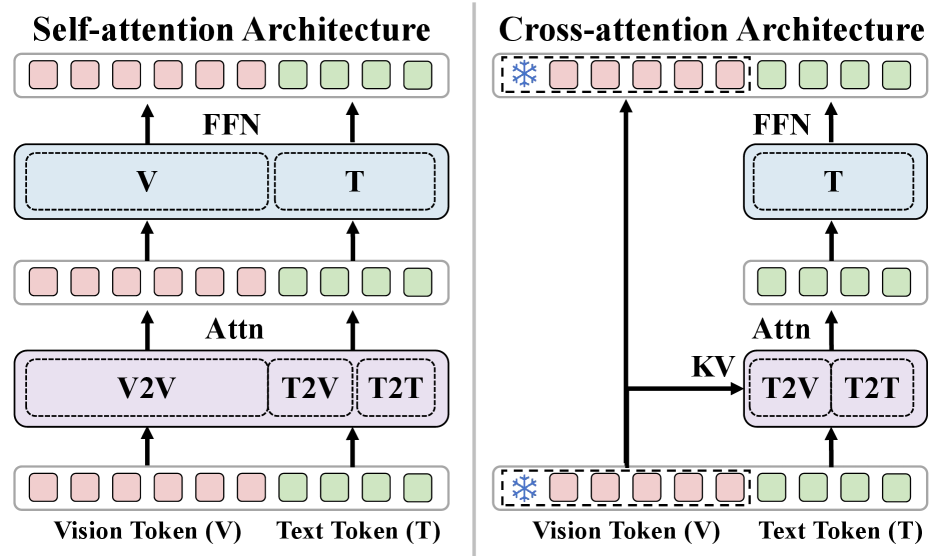
问题定义:现有MLLM模型在处理视觉和文本信息时,通常采用统一的自注意力机制,这意味着视觉tokens需要在每一层Transformer中进行自注意力和前馈计算。这种密集型的视觉处理方式带来了巨大的计算开销,成为提升MLLM效率的瓶颈。现有方法未能充分利用视觉信息与语言空间对齐的特性,导致计算资源的浪费。
核心思路:ViCA的核心思路是减少视觉信息的冗余计算,只在必要的层进行视觉-语言交互。论文观察到,视觉嵌入已经与语言空间对齐,因此视觉tokens不需要在每一层都进行复杂的自注意力和前馈计算。通过让视觉tokens绕过大部分Transformer层,只在选定的层通过交叉注意力与文本tokens交互,可以显著降低计算量。
技术框架:ViCA架构主要包含视觉编码器、文本编码器和交叉注意力模块。视觉编码器负责将图像转换为视觉tokens,文本编码器负责将文本转换为文本tokens。与传统MLLM不同的是,ViCA中的视觉tokens不经过自注意力和前馈层,而是直接输入到选定的Transformer层中的交叉注意力模块,与文本tokens进行交互。交叉注意力模块负责融合视觉和文本信息,并将融合后的信息传递给后续的Transformer层。
关键创新:ViCA最重要的创新点在于提出了视觉信息仅通过交叉注意力交互的架构。这种架构避免了视觉tokens在每一层Transformer中的冗余计算,显著降低了计算量,同时保持了模型的性能。与现有方法相比,ViCA更加高效,可以在相同的计算资源下实现更高的性能。
关键设计:ViCA的关键设计包括:1) 选择合适的Transformer层进行交叉注意力交互。论文通过实验确定了最佳的交叉注意力层数和位置。2) 使用稀疏交叉注意力,进一步降低计算量。3) ViCA可以与token剪枝方法结合,进一步提升效率。具体实现细节包括交叉注意力模块的参数设置、损失函数的设计等。
🖼️ 关键图片


📊 实验亮点
实验结果表明,ViCA在保持98%基线精度的前提下,将视觉侧的计算量降低到4%。在单批次推理中,ViCA实现了超过3.5倍的加速,在多批次推理中实现了超过10倍的加速。ViCA在多个多模态基准测试中取得了与现有方法相当甚至更好的性能,证明了其高效性和有效性。
🎯 应用场景
ViCA架构可以应用于各种需要高效多模态理解的场景,例如智能客服、图像搜索、视频分析、机器人导航等。通过降低计算成本,ViCA使得MLLM能够在资源受限的设备上运行,并加速了多模态应用的部署。未来,ViCA可以进一步扩展到其他模态,例如音频、3D点云等,实现更广泛的应用。
📄 摘要(原文)
Modern multimodal large language models (MLLMs) adopt a unified self-attention design that processes visual and textual tokens at every Transformer layer, incurring substantial computational overhead. In this work, we revisit the necessity of such dense visual processing and show that projected visual embeddings are already well-aligned with the language space, while effective vision-language interaction occurs in only a small subset of layers. Based on these insights, we propose ViCA (Vision-only Cross-Attention), a minimal MLLM architecture in which visual tokens bypass all self-attention and feed-forward layers, interacting with text solely through sparse cross-attention at selected layers. Extensive evaluations across three MLLM backbones, nine multimodal benchmarks, and 26 pruning-based baselines show that ViCA preserves 98% of baseline accuracy while reducing visual-side computation to 4%, consistently achieving superior performance-efficiency trade-offs. Moreover, ViCA provides a regular, hardware-friendly inference pipeline that yields over 3.5x speedup in single-batch inference and over 10x speedup in multi-batch inference, reducing visual grounding to near-zero overhead compared with text-only LLMs. It is also orthogonal to token pruning methods and can be seamlessly combined for further efficiency gains. Our code is available at https://github.com/EIT-NLP/ViCA.