SIGMA: Selective-Interleaved Generation with Multi-Attribute Tokens
作者: Xiaoyan Zhang, Zechen Bai, Haofan Wang, Yiren Song
分类: cs.CV
发布日期: 2026-02-07
💡 一句话要点
SIGMA:通过多属性Token选择性交错生成,实现扩散模型的多条件组合编辑。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散模型 多属性控制 图像编辑 条件生成 多模态对齐
📋 核心要点
- 现有统一模型在处理多条件输入和灵活合成异构源结果方面存在局限性。
- SIGMA通过引入选择性多属性Token,使模型能够理解和组合多个视觉条件。
- SIGMA在组合编辑、属性迁移和多模态对齐方面表现出色,显著提升了可控性和视觉质量。
📝 摘要(中文)
本文提出SIGMA,一个统一的后训练框架,旨在实现扩散Transformer中交错的多条件生成。SIGMA引入了选择性的多属性Token,包括风格、内容、主题和身份Token,使模型能够解释和组合交错的文本-图像序列中的多个视觉条件。通过在Bagel统一骨干网络上进行70万个交错样本的后训练,SIGMA支持组合编辑、选择性属性迁移和细粒度的多模态对齐。大量实验表明,SIGMA在各种编辑和生成任务中提高了可控性、跨条件一致性和视觉质量,并且在组合任务上相比Bagel有显著提升。
🔬 方法详解
问题定义:现有统一模型,如Bagel,虽然能处理图像编辑任务,但主要局限于单条件输入,无法灵活地组合多个异构来源的信息。这限制了其在复杂场景下的应用,例如需要同时考虑风格、内容和主题的图像编辑。
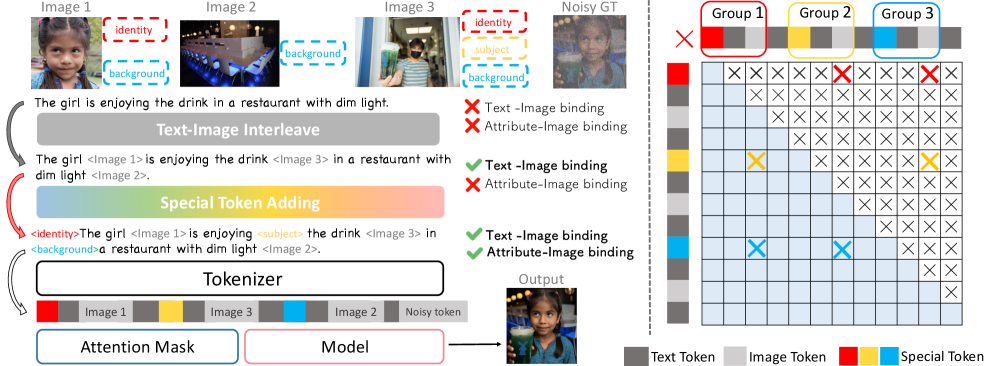
核心思路:SIGMA的核心在于引入“选择性多属性Token”的概念,将不同的视觉条件(如风格、内容、主题、身份)表示为独立的Token。通过交错排列这些Token和文本-图像序列,模型可以学习如何根据不同的属性Token来控制生成过程,从而实现多条件组合编辑。
技术框架:SIGMA采用后训练的方式,在已有的统一扩散Transformer模型(如Bagel)的基础上进行训练。整体流程包括:1)构建包含交错文本-图像序列和多属性Token的数据集;2)使用该数据集对Bagel模型进行后训练,使其能够理解和生成多属性Token;3)在推理阶段,通过调整不同属性Token的组合,控制生成结果。
关键创新:SIGMA的关键创新在于选择性多属性Token的设计和交错生成机制。与传统的单条件输入相比,SIGMA允许模型同时考虑多个视觉条件,并根据这些条件生成相应的图像。这种选择性和组合性是现有方法所不具备的。
关键设计:SIGMA的关键设计包括:1)多属性Token的类型(风格、内容、主题、身份等)的选择,需要根据具体的应用场景进行调整;2)交错序列的构建方式,需要保证不同属性Token之间的语义一致性;3)后训练数据集的规模和质量,直接影响模型的性能。论文中使用700K的交错样本进行训练。
🖼️ 关键图片


📊 实验亮点
实验结果表明,SIGMA在组合编辑任务上显著优于Bagel。例如,在风格迁移和内容编辑的组合任务中,SIGMA能够生成更符合用户意图的图像,并且在可控性和视觉质量方面都有明显提升。定量指标也显示,SIGMA在跨条件一致性方面取得了显著的进步。
🎯 应用场景
SIGMA具有广泛的应用前景,包括图像编辑、风格迁移、内容生成、身份定制等。它可以应用于创意设计、虚拟现实、游戏开发等领域,为用户提供更灵活、更可控的图像生成能力。未来,SIGMA有望成为多模态内容创作的重要工具。
📄 摘要(原文)
Recent unified models such as Bagel demonstrate that paired image-edit data can effectively align multiple visual tasks within a single diffusion transformer. However, these models remain limited to single-condition inputs and lack the flexibility needed to synthesize results from multiple heterogeneous sources. We present SIGMA (Selective-Interleaved Generation with Multi-Attribute Tokens), a unified post-training framework that enables interleaved multi-condition generation within diffusion transformers. SIGMA introduces selective multi-attribute tokens, including style, content, subject, and identity tokens, which allow the model to interpret and compose multiple visual conditions in an interleaved text-image sequence. Through post-training on the Bagel unified backbone with 700K interleaved examples, SIGMA supports compositional editing, selective attribute transfer, and fine-grained multimodal alignment. Extensive experiments show that SIGMA improves controllability, cross-condition consistency, and visual quality across diverse editing and generation tasks, with substantial gains over Bagel on compositional tasks.