Revealing the Semantic Selection Gap in DINOv3 through Training-Free Few-Shot Segmentation
作者: Hussni Mohd Zakir, Eric Tatt Wei Ho
分类: cs.CV, cs.AI
发布日期: 2026-02-07
备注: 10 pages, 3 figures, 7 tables
🔗 代码/项目: GITHUB
💡 一句话要点
FSSDINO:揭示DINOv3中语义选择差距的免训练少样本分割方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 少样本语义分割 自监督学习 视觉Transformer DINOv3 免训练 特征选择 语义选择差距
📋 核心要点
- 现有少样本语义分割方法依赖复杂解码器或测试时自适应,计算成本高昂且效果提升有限。
- FSSDINO利用DINOv3的冻结特征,通过类别原型和Gram矩阵细化,实现免训练的少样本分割。
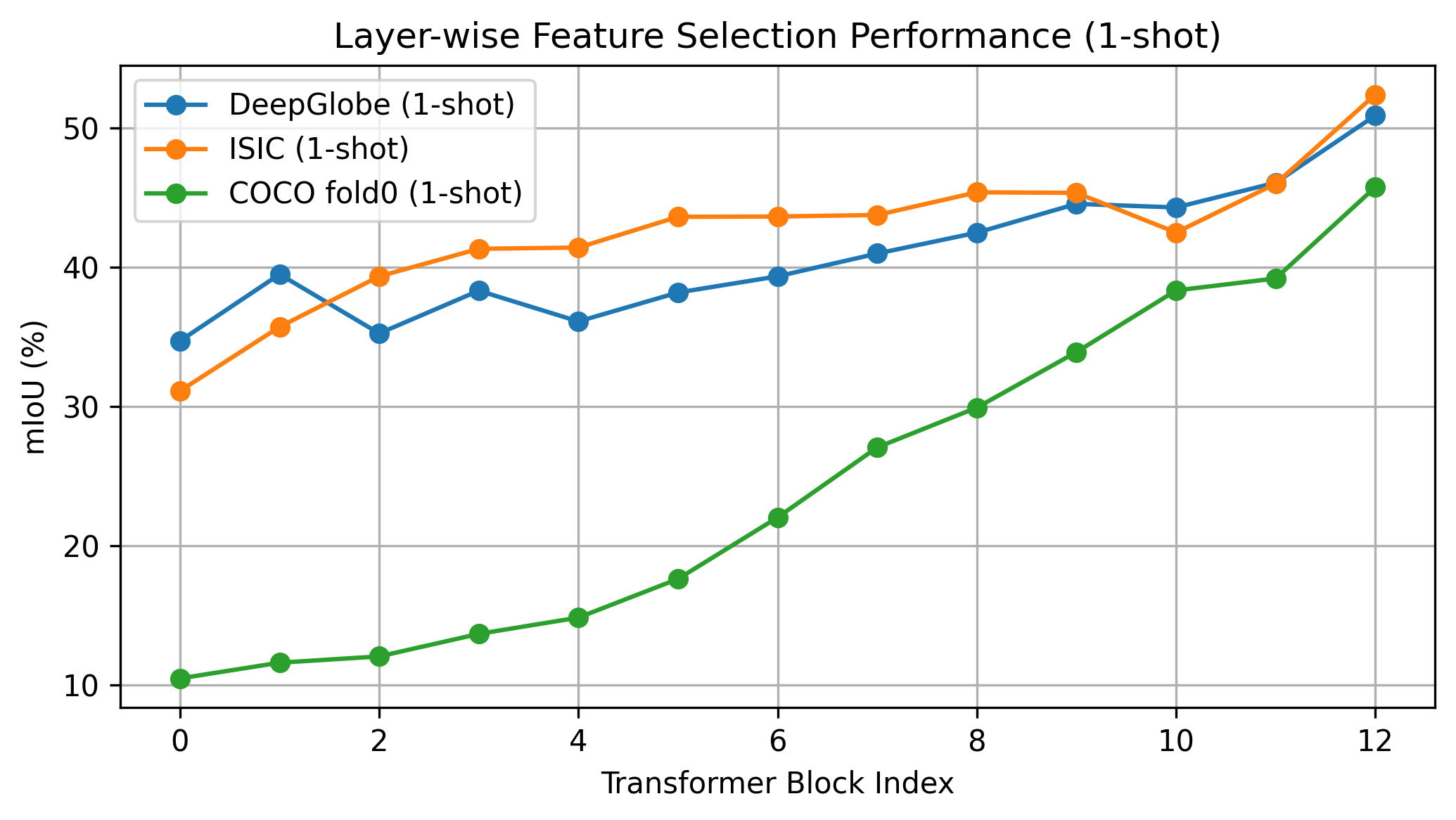
- 实验表明,FSSDINO在多个基准测试中表现出色,并揭示了DINOv3中最后一层特征与最优中间层特征的性能差距。
📝 摘要(中文)
本研究探索了冻结的DINOv3特征在少样本语义分割(FSS)中的内在能力,提出了一种免训练的基线方法FSSDINO,该方法利用类别特定的原型和Gram矩阵细化。在二元、多类和跨域(CDFSS)基准测试中,结果表明,这种应用于骨干网络最后一层的极简方法,与涉及复杂解码器或测试时自适应的专用方法相比,具有很强的竞争力。关键在于,我们进行了一个Oracle引导的层分析,发现标准最后一层特征与全局最优中间表示之间存在显著的性能差距。我们揭示了一个“最安全与最优”的困境:虽然Oracle证明可以获得更高的性能,与计算密集型自适应方法的结果相匹配,但当前无监督和支持引导的选择指标始终产生低于最后一层基线的性能。这体现了基础模型中的“语义选择差距”,即传统启发式方法无法可靠地识别高保真特征。我们的工作将“最后一层”确立为一个极具竞争力的基线,并对DINOv3中潜在的语义潜力进行了严格的诊断。代码已公开。
🔬 方法详解
问题定义:论文旨在解决少样本语义分割(FSS)问题,即在只有少量标注样本的情况下,对图像进行像素级别的语义分割。现有方法通常需要复杂的解码器或测试时自适应,增加了计算成本,并且可能无法充分利用预训练模型的潜力。论文关注的是如何更有效地利用自监督学习得到的视觉Transformer(ViT)模型,如DINOv3,来进行FSS任务,并探究其内部特征表示的潜力。
核心思路:论文的核心思路是利用DINOv3预训练模型提取的特征,通过简单的原型学习和Gram矩阵细化,实现免训练的FSS。关键在于发现并利用DINOv3模型中不同层所蕴含的语义信息,并找到一种有效的方法来选择或组合这些信息,以达到最佳的分割效果。论文假设DINOv3的中间层可能包含更优的语义信息,但现有的选择策略无法有效利用。
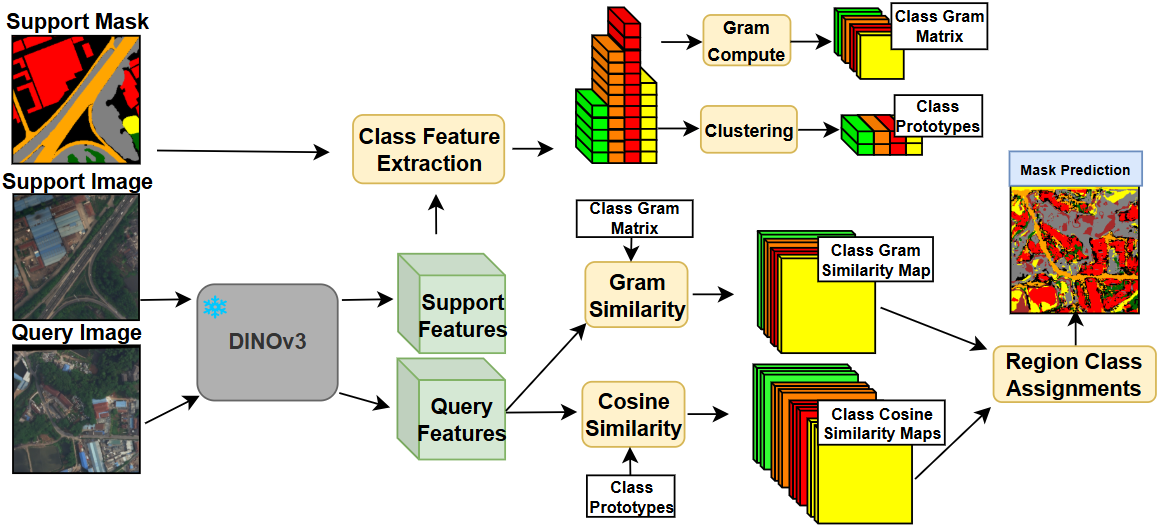
技术框架:FSSDINO的整体框架包括以下几个步骤:1) 使用DINOv3提取图像特征;2) 基于支持集图像的特征,为每个类别构建原型;3) 利用Gram矩阵细化原型特征;4) 使用原型特征对查询图像进行像素级别的分类,得到分割结果。论文还引入了Oracle引导的层分析,用于评估不同层特征的潜在性能。
关键创新:论文的关键创新在于:1) 提出了一个免训练的FSS基线方法FSSDINO,证明了DINOv3预训练特征的强大能力;2) 通过Oracle引导的层分析,揭示了DINOv3中最后一层特征与最优中间层特征之间存在“语义选择差距”,即现有方法无法有效利用中间层的语义信息;3) 提出了“最安全与最优”的困境,强调了选择合适特征的重要性。
关键设计:FSSDINO的关键设计包括:1) 使用DINOv3的冻结特征,避免了额外的训练;2) 使用类别特定的原型来表示每个类别的语义信息;3) 使用Gram矩阵细化原型特征,增强其判别能力;4) 使用余弦相似度来度量像素特征与原型特征之间的相似度,从而进行像素级别的分类。Oracle引导的层分析通过遍历所有可能的层组合,找到最优的特征组合,作为性能上限的参考。
🖼️ 关键图片
📊 实验亮点
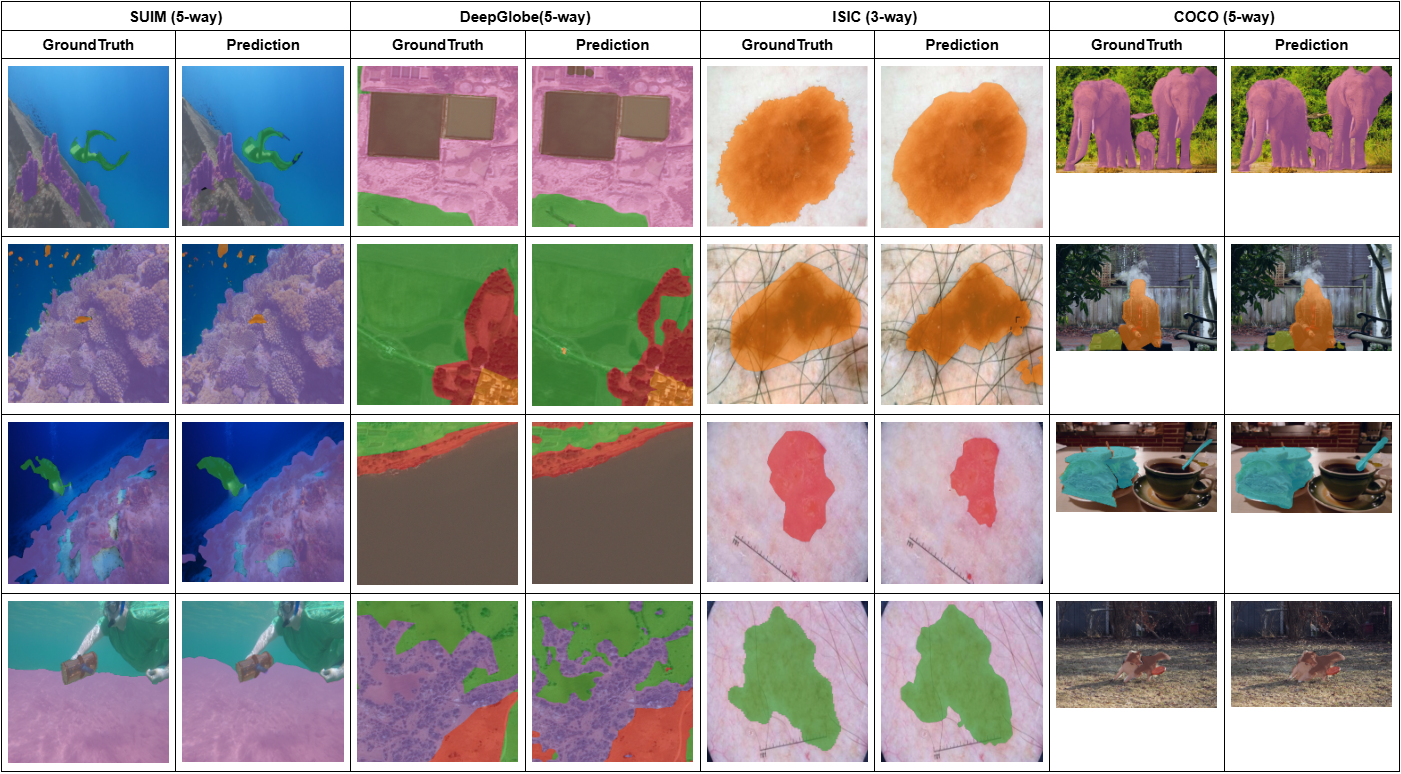
FSSDINO在二元、多类和跨域少样本语义分割任务上取得了有竞争力的结果,证明了DINOv3特征的有效性。Oracle引导的层分析表明,通过选择合适的中间层特征,性能可以进一步提升,甚至可以与需要大量计算资源的自适应方法相媲美。该研究揭示了DINOv3中存在的“语义选择差距”,为未来的研究方向提供了新的思路。
🎯 应用场景
该研究成果可应用于各种需要快速部署和少量标注数据的语义分割场景,例如医疗图像分析、遥感图像解译、自动驾驶等领域。通过充分挖掘预训练模型的潜力,可以降低对大量标注数据的依赖,加速模型在实际场景中的应用。
📄 摘要(原文)
Recent self-supervised Vision Transformers (ViTs), such as DINOv3, provide rich feature representations for dense vision tasks. This study investigates the intrinsic few-shot semantic segmentation (FSS) capabilities of frozen DINOv3 features through a training-free baseline, FSSDINO, utilizing class-specific prototypes and Gram-matrix refinement. Our results across binary, multi-class, and cross-domain (CDFSS) benchmarks demonstrate that this minimal approach, applied to the final backbone layer, is highly competitive with specialized methods involving complex decoders or test-time adaptation. Crucially, we conduct an Oracle-guided layer analysis, identifying a significant performance gap between the standard last-layer features and globally optimal intermediate representations. We reveal a "Safest vs. Optimal" dilemma: while the Oracle proves higher performance is attainable, matching the results of compute-intensive adaptation methods, current unsupervised and support-guided selection metrics consistently yield lower performance than the last-layer baseline. This characterizes a "Semantic Selection Gap" in Foundation Models, a disconnect where traditional heuristics fail to reliably identify high-fidelity features. Our work establishes the "Last-Layer" as a deceptively strong baseline and provides a rigorous diagnostic of the latent semantic potentials in DINOv3.The code is publicly available at https://github.com/hussni0997/fssdino.