IM-Animation: An Implicit Motion Representation for Identity-decoupled Character Animation
作者: Zhufeng Xu, Xuan Gao, Feng-Lin Liu, Haoxian Zhang, Zhixue Fang, Yu-Kun Lai, Xiaoqiang Liu, Pengfei Wan, Lin Gao
分类: cs.CV
发布日期: 2026-02-07
💡 一句话要点
提出IM-Animation,通过隐式运动表示实现身份解耦的角色动画
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 角色动画 隐式运动表示 身份解耦 视频生成 扩散模型
📋 核心要点
- 现有角色动画方法在处理空间错位、身体比例变化以及身份信息泄露等方面存在不足。
- 论文提出一种新颖的隐式运动表示,将运动压缩为1D token,并设计时间一致性mask token重定向模块。
- 实验结果表明,该方法在角色动画生成方面取得了优越或具有竞争力的性能,提升了动画质量和一致性。
📝 摘要(中文)
视频扩散模型在角色动画领域取得了显著进展,可以通过驱动视频来驱动静态身份图像,从而合成运动视频。显式方法使用骨骼、DWPose或其他显式结构化信号来表示运动,但难以处理空间错位和身体比例变化。隐式方法直接从驱动视频中捕获高层隐式运动语义,但存在身份信息泄露以及运动和外观之间纠缠的问题。为了解决上述挑战,我们提出了一种新颖的隐式运动表示,将每帧运动压缩成紧凑的1D运动token。这种设计放宽了2D表示中固有的严格空间约束,并有效地防止了运动视频中的身份信息泄露。此外,我们设计了一个基于时间一致性mask token的重定向模块,该模块强制执行时间训练瓶颈,从而减轻了源图像运动的干扰并提高了重定向一致性。我们的方法采用三阶段训练策略,以提高训练效率并确保高保真度。大量实验表明,与最先进的方法相比,我们的隐式运动表示和提出的IM-Animation的生成能力实现了卓越或具有竞争力的性能。
🔬 方法详解
问题定义:现有基于显式运动表示的角色动画方法难以处理空间错位和身体比例变化,而隐式方法则容易出现身份信息泄露和运动与外观的纠缠。这些问题限制了角色动画的真实性和可控性。
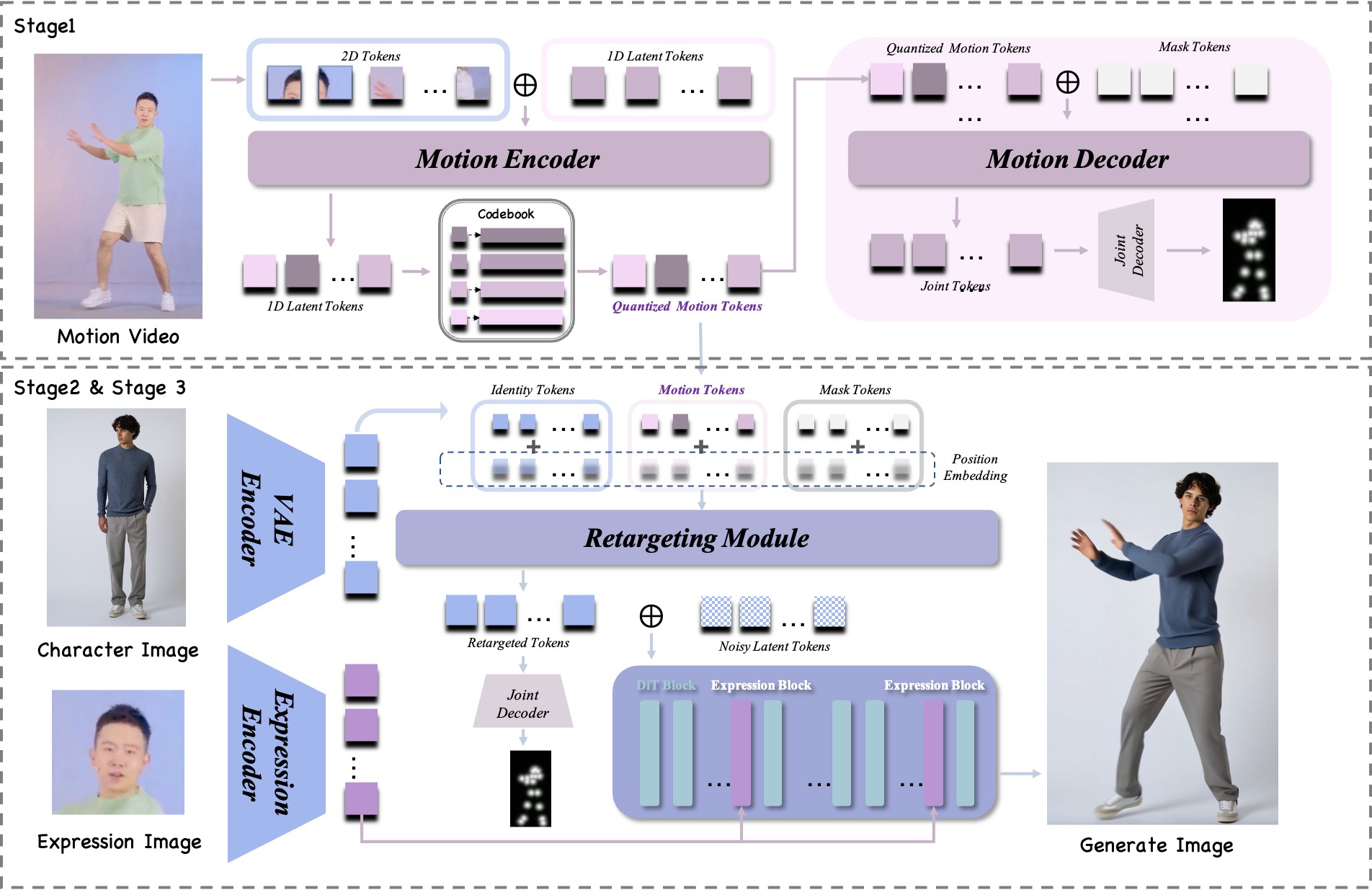
核心思路:论文的核心思路是将每帧的运动信息压缩成紧凑的1D运动token,从而解耦身份信息和运动信息。通过这种方式,可以避免身份信息从运动视频中泄露,并减少运动和外观之间的纠缠。同时,设计时间一致性mask token重定向模块,保证生成视频的时间一致性。
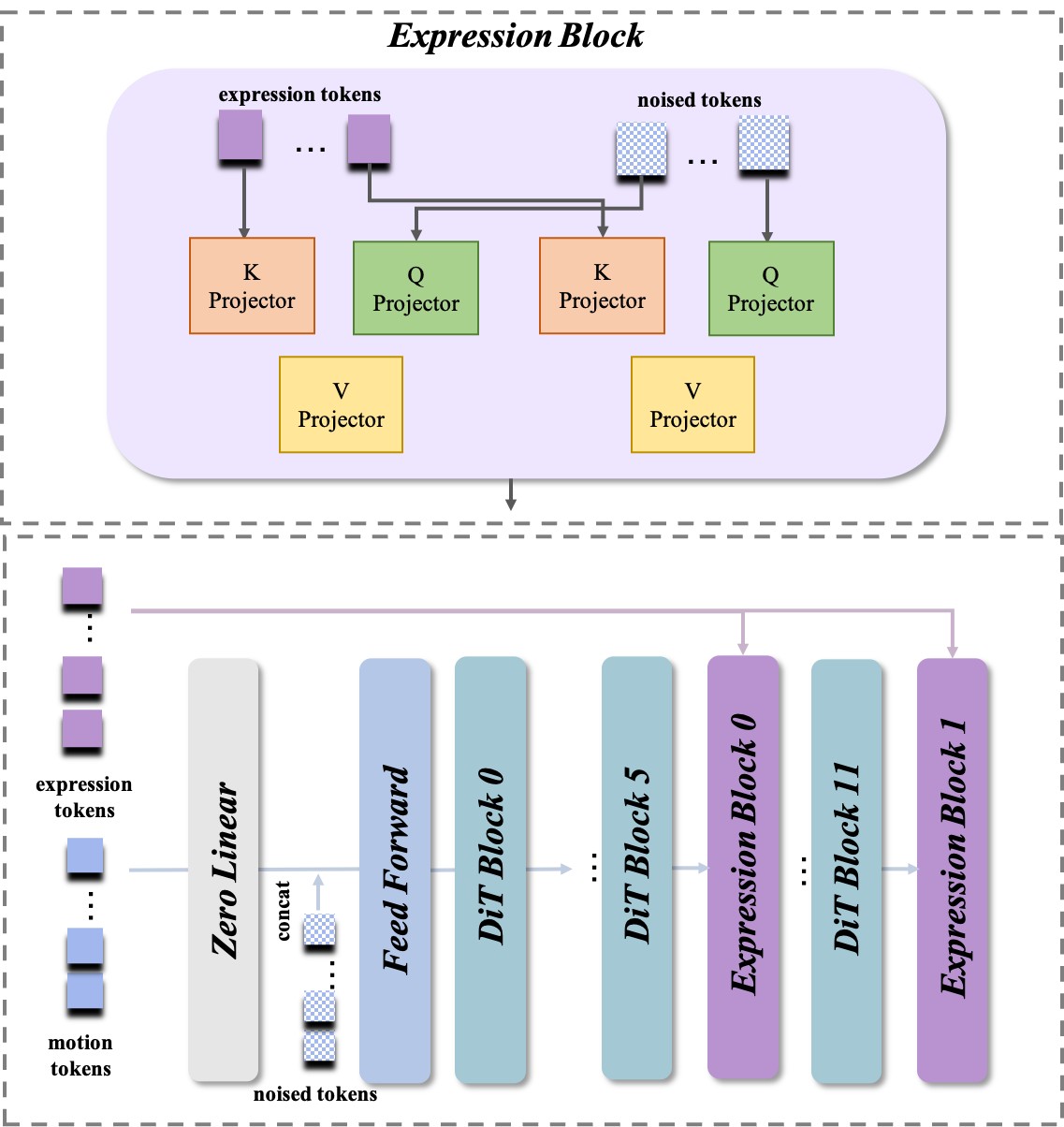
技术框架:IM-Animation采用三阶段训练策略。第一阶段训练一个基础的视频生成模型。第二阶段,引入隐式运动表示模块,学习将运动信息编码为1D token。第三阶段,训练时间一致性mask token重定向模块,以提高生成视频的时间一致性。整体框架包含运动编码器、身份编码器、解码器和时间一致性模块。
关键创新:该方法最重要的创新点在于提出了隐式运动表示,将运动信息压缩成1D token,从而有效地解耦了身份信息和运动信息。与现有方法相比,该方法不需要显式的运动结构,并且能够更好地处理空间错位和身体比例变化。
关键设计:时间一致性mask token重定向模块通过在训练过程中引入时间瓶颈来强制模型学习时间一致性。具体来说,该模块使用mask token来屏蔽部分帧的运动信息,并要求模型根据剩余的帧来预测被屏蔽的帧。损失函数包括重构损失和时间一致性损失,用于优化模型。
🖼️ 关键图片

📊 实验亮点
实验结果表明,IM-Animation在角色动画生成方面取得了优越或具有竞争力的性能。与现有方法相比,IM-Animation能够生成更高质量、身份一致的角色动画,并且能够更好地处理空间错位和身体比例变化。在定量评估方面,IM-Animation在FID和LPIPS等指标上均优于其他方法,表明其生成视频的质量和真实性更高。
🎯 应用场景
该研究成果可应用于电影制作、游戏开发、虚拟现实和增强现实等领域,能够生成高质量、身份一致的角色动画。该方法可以降低动画制作的成本和时间,并为用户提供更加个性化和可控的角色动画体验。未来,该技术有望应用于更复杂的场景和角色,例如多人互动动画和实时动画生成。
📄 摘要(原文)
Recent progress in video diffusion models has markedly advanced character animation, which synthesizes motioned videos by animating a static identity image according to a driving video. Explicit methods represent motion using skeleton, DWPose or other explicit structured signals, but struggle to handle spatial mismatches and varying body scales. %proportions. Implicit methods, on the other hand, capture high-level implicit motion semantics directly from the driving video, but suffer from identity leakage and entanglement between motion and appearance. To address the above challenges, we propose a novel implicit motion representation that compresses per-frame motion into compact 1D motion tokens. This design relaxes strict spatial constraints inherent in 2D representations and effectively prevents identity information leakage from the motion video. Furthermore, we design a temporally consistent mask token-based retargeting module that enforces a temporal training bottleneck, mitigating interference from the source images' motion and improving retargeting consistency. Our methodology employs a three-stage training strategy to enhance the training efficiency and ensure high fidelity. Extensive experiments demonstrate that our implicit motion representation and the propose IM-Animation's generative capabilities are achieve superior or competitive performance compared with state-of-the-art methods.