SoulX-FlashHead: Oracle-guided Generation of Infinite Real-time Streaming Talking Heads
作者: Tan Yu, Qian Qiao, Le Shen, Ke Zhou, Jincheng Hu, Dian Sheng, Bo Hu, Haoming Qin, Jun Gao, Changhai Zhou, Shunshun Yin, Siyuan Liu
分类: cs.CV
发布日期: 2026-02-07 (更新: 2026-02-11)
备注: 11 pages, 3 figures
💡 一句话要点
提出SoulX-FlashHead,实现无限实时流式高清逼真说话人头部生成
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation)
关键词: 说话人头部生成 实时流式传输 音频驱动 双向蒸馏 时空预训练 深度学习 生成模型
📋 核心要点
- 现有音频驱动人像生成模型难以兼顾高保真视觉质量和低延迟流式传输,大型模型计算成本高昂,轻量级模型则牺牲了面部整体表达和时间稳定性。
- SoulX-FlashHead通过流式感知时空预训练和Oracle引导的双向蒸馏,从音频特征提取和长序列生成两方面入手,提升了流式说话人头部生成的效果。
- 实验表明,SoulX-FlashHead在HDTF和VFHQ基准上达到SOTA,Lite版本在RTX 4090上可达96FPS,实现了超快交互和视觉连贯性。
📝 摘要(中文)
本文提出SoulX-FlashHead,一个用于实时、无限时长、高保真流式视频生成的统一框架,参数量为13亿。针对流式场景下音频特征不稳定的问题,引入了具备时间音频上下文缓存机制的流式感知时空预训练,确保从短音频片段中提取鲁棒的特征。此外,为了缓解长序列自回归生成中固有的误差累积和身份漂移,提出了Oracle引导的双向蒸馏,利用ground-truth运动先验来提供精确的物理指导。同时,提出了VividHead,一个包含782小时严格对齐素材的大规模高质量数据集,以支持鲁棒训练。大量实验表明,SoulX-FlashHead在HDTF和VFHQ基准测试中取得了最先进的性能。值得注意的是,我们的Lite变体在单个NVIDIA RTX 4090上实现了96 FPS的推理速度,从而在不牺牲视觉连贯性的前提下实现了超快的交互。
🔬 方法详解
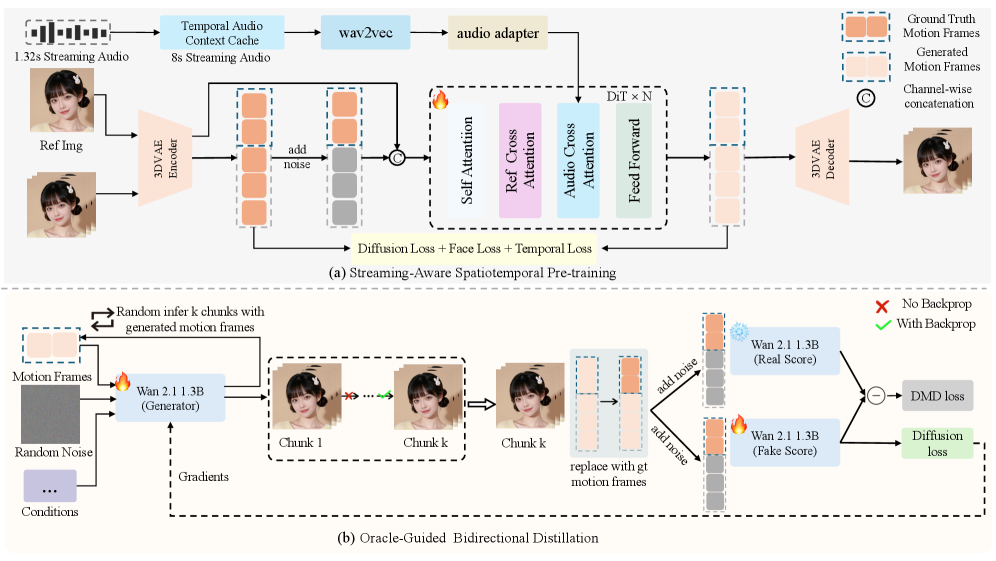
问题定义:论文旨在解决音频驱动的说话人头部生成任务中,现有方法难以同时保证高保真度、低延迟和长时间稳定性的问题。现有方法要么计算量过大,无法实时流式传输;要么为了降低计算量而牺牲了生成质量和时间一致性,导致身份漂移等问题。
核心思路:论文的核心思路是结合流式感知的预训练和Oracle引导的蒸馏,分别解决音频特征提取和长序列生成中的挑战。通过预训练增强模型对短音频片段的鲁棒性,并通过蒸馏引入ground-truth运动先验,从而约束生成过程,避免误差累积和身份漂移。
技术框架:SoulX-FlashHead是一个统一的框架,包含以下主要模块:1) 流式感知时空预训练模块,利用时间音频上下文缓存机制提取鲁棒的音频特征;2) Oracle引导的双向蒸馏模块,利用ground-truth运动先验指导生成过程;3) 生成模块,负责将音频特征和运动先验转化为最终的视频帧。整体流程是:输入音频片段,经过预训练模块提取特征,然后通过蒸馏模块生成运动先验,最后由生成模块生成视频帧。
关键创新:论文的关键创新在于:1) 提出了流式感知的时空预训练方法,通过时间音频上下文缓存机制,增强了模型对短音频片段的鲁棒性;2) 提出了Oracle引导的双向蒸馏方法,利用ground-truth运动先验,有效缓解了长序列生成中的误差累积和身份漂移问题;3) 构建了大规模高质量数据集VividHead,为模型训练提供了充足的数据支持。
关键设计:在流式感知时空预训练中,时间音频上下文缓存机制的具体实现方式未知。在Oracle引导的双向蒸馏中,如何选择合适的ground-truth运动先验,以及如何设计损失函数来有效利用这些先验,是关键的技术细节。此外,生成模块的网络结构和参数设置也会影响最终的生成质量。
🖼️ 关键图片


📊 实验亮点
SoulX-FlashHead在HDTF和VFHQ基准测试中取得了state-of-the-art的性能。更重要的是,其Lite版本在单个NVIDIA RTX 4090上实现了96 FPS的推理速度,这表明该模型可以在保证高视觉质量的同时,实现超快的实时交互。这一结果显著优于现有方法,为实时流式说话人头部生成提供了新的解决方案。
🎯 应用场景
该研究成果可广泛应用于虚拟主播、在线会议、远程教育、游戏娱乐等领域。通过SoulX-FlashHead,用户可以使用极低的延迟生成逼真的说话人头部视频,从而实现更自然、更流畅的交互体验。未来,该技术有望进一步应用于个性化内容创作、数字人定制等领域,具有广阔的应用前景。
📄 摘要(原文)
Achieving a balance between high-fidelity visual quality and low-latency streaming remains a formidable challenge in audio-driven portrait generation. Existing large-scale models often suffer from prohibitive computational costs, while lightweight alternatives typically compromise on holistic facial representations and temporal stability. In this paper, we propose SoulX-FlashHead, a unified 1.3B-parameter framework designed for real-time, infinite-length, and high-fidelity streaming video generation. To address the instability of audio features in streaming scenarios, we introduce Streaming-Aware Spatiotemporal Pre-training equipped with a Temporal Audio Context Cache mechanism, which ensures robust feature extraction from short audio fragments. Furthermore, to mitigate the error accumulation and identity drift inherent in long-sequence autoregressive generation, we propose Oracle-Guided Bidirectional Distillation, leveraging ground-truth motion priors to provide precise physical guidance. We also present VividHead, a large-scale, high-quality dataset containing 782 hours of strictly aligned footage to support robust training. Extensive experiments demonstrate that SoulX-FlashHead achieves state-of-the-art performance on HDTF and VFHQ benchmarks. Notably, our Lite variant achieves an inference speed of 96 FPS on a single NVIDIA RTX 4090, facilitating ultra-fast interaction without sacrificing visual coherence.