Optimizing Few-Step Generation with Adaptive Matching Distillation
作者: Lichen Bai, Zikai Zhou, Shitong Shao, Wenliang Zhong, Shuo Yang, Shuo Chen, Bojun Chen, Zeke Xie
分类: cs.CV, cs.LG
发布日期: 2026-02-07
备注: 25 pages, 15 figures, 11 tables
💡 一句话要点
提出自适应匹配蒸馏(AMD)优化少步生成模型,提升保真度和鲁棒性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 少步生成模型 分布匹配蒸馏 自适应匹配蒸馏 禁区问题 奖励代理
📋 核心要点
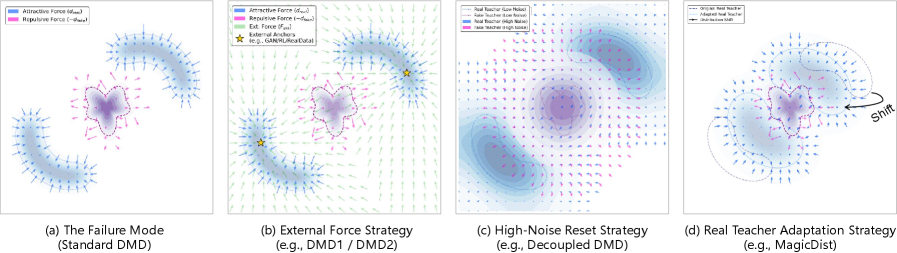
- 现有分布匹配蒸馏方法在“禁区”易失效,即教师指导不可靠,学生排斥力不足的区域。
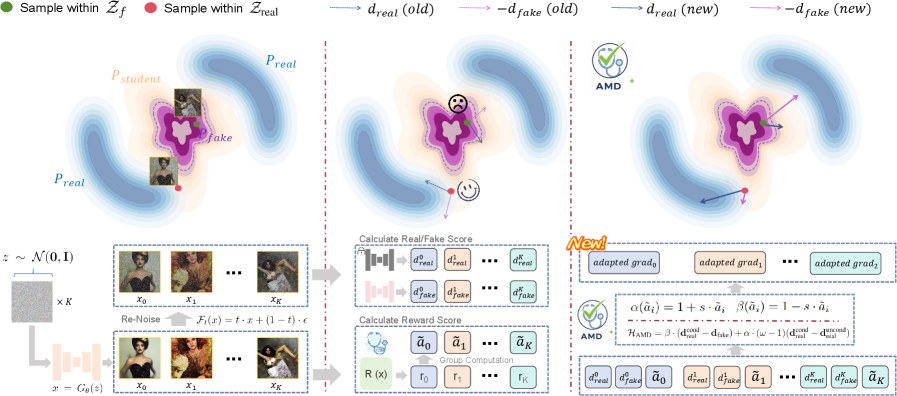
- 提出自适应匹配蒸馏(AMD),通过奖励代理检测并逃离禁区,动态调整梯度优先级,锐化排斥能量壁垒。
- 实验表明,AMD在图像和视频生成任务中显著提升了样本保真度和训练鲁棒性,超越现有技术水平。
📝 摘要(中文)
分布匹配蒸馏(DMD)是一种强大的加速范式,但其稳定性经常在“禁区”中受到影响,这些区域指的是真实教师提供不可靠指导,而虚假教师施加的排斥力不足的区域。本文提出了一个统一的优化框架,将现有技术重新解释为避免这些损坏区域的隐式策略。基于此,我们引入了自适应匹配蒸馏(AMD),这是一种自我纠正机制,它利用奖励代理来显式地检测和逃避禁区。AMD通过结构信号分解动态地优先考虑校正梯度,并引入排斥景观锐化来强制执行陡峭的能量壁垒,以防止失效模式崩溃。在图像和视频生成任务(例如,SDXL, Wan2.1)以及严格的基准测试(例如,VBench, GenEval)中进行的大量实验表明,AMD显著提高了样本保真度和训练鲁棒性。例如,AMD将SDXL上的HPSv2评分从30.64提高到31.25,优于最先进的基线。这些发现验证了显式地纠正禁区内的优化轨迹对于推动少步生成模型的性能上限至关重要。
🔬 方法详解
问题定义:论文旨在解决分布匹配蒸馏(DMD)在少步生成模型训练中,由于“禁区”问题导致的训练不稳定和性能下降。现有方法在这些区域容易受到不可靠的教师指导和不足的学生排斥力影响,导致模型生成质量受损。
核心思路:论文的核心思路是显式地检测并纠正优化轨迹中进入“禁区”的部分。通过引入奖励代理来评估生成样本的质量,从而判断是否进入了“禁区”。然后,通过调整梯度方向和锐化排斥景观,引导模型逃离这些区域,从而提高训练的稳定性和生成质量。
技术框架:AMD框架主要包含以下几个阶段:1) 使用奖励代理评估生成样本的质量;2) 基于奖励信号检测“禁区”;3) 通过结构信号分解动态调整梯度优先级,优先考虑校正梯度;4) 使用排斥景观锐化技术,增强模型逃离“禁区”的能力。整体流程是一个自我纠正的循环,不断优化生成模型的参数。
关键创新:论文的关键创新在于提出了自适应匹配蒸馏(AMD)这一自我纠正机制,它能够显式地检测并逃离“禁区”。与现有方法隐式地避免这些区域不同,AMD通过奖励代理直接评估生成质量,并根据评估结果动态调整优化策略。此外,结构信号分解和排斥景观锐化技术也为逃离“禁区”提供了有效的手段。
关键设计:AMD的关键设计包括:1) 奖励代理的选择,需要能够准确评估生成样本的质量;2) 结构信号分解的具体实现,如何将梯度分解为校正梯度和其他成分;3) 排斥景观锐化的方法,如何增强模型对“禁区”的排斥力。此外,损失函数的设计也至关重要,需要平衡生成质量和训练稳定性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,AMD在SDXL等模型上显著提升了生成质量。例如,在SDXL模型上,AMD将HPSv2评分从30.64提高到31.25,超越了现有最佳基线方法。此外,在VBench和GenEval等基准测试中,AMD也表现出优异的性能,验证了其在提升样本保真度和训练鲁棒性方面的有效性。
🎯 应用场景
该研究成果可广泛应用于图像、视频等生成模型的训练加速和性能提升,尤其是在计算资源受限或需要快速生成高质量内容的应用场景中,例如移动设备上的图像编辑、实时视频生成、以及需要快速迭代设计的创意工具等。该方法能够提升生成模型的鲁棒性和生成质量,具有重要的实际应用价值。
📄 摘要(原文)
Distribution Matching Distillation (DMD) is a powerful acceleration paradigm, yet its stability is often compromised in Forbidden Zone, regions where the real teacher provides unreliable guidance while the fake teacher exerts insufficient repulsive force. In this work, we propose a unified optimization framework that reinterprets prior art as implicit strategies to avoid these corrupted regions. Based on this insight, we introduce Adaptive Matching Distillation (AMD), a self-correcting mechanism that utilizes reward proxies to explicitly detect and escape Forbidden Zones. AMD dynamically prioritizes corrective gradients via structural signal decomposition and introduces Repulsive Landscape Sharpening to enforce steep energy barriers against failure mode collapse. Extensive experiments across image and video generation tasks (e.g., SDXL, Wan2.1) and rigorous benchmarks (e.g., VBench, GenEval) demonstrate that AMD significantly enhances sample fidelity and training robustness. For instance, AMD improves the HPSv2 score on SDXL from 30.64 to 31.25, outperforming state-of-the-art baselines. These findings validate that explicitly rectifying optimization trajectories within Forbidden Zones is essential for pushing the performance ceiling of few-step generative models.