LUCID-SAE: Learning Unified Vision-Language Sparse Codes for Interpretable Concept Discovery
作者: Difei Gu, Yunhe Gao, Gerasimos Chatzoudis, Zihan Dong, Guoning Zhang, Bangwei Guo, Yang Zhou, Mu Zhou, Dimitris Metaxas
分类: cs.CV, cs.AI
发布日期: 2026-02-07
💡 一句话要点
提出LUCID-SAE,学习统一视觉-语言稀疏编码,用于可解释的概念发现。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 稀疏自编码器 多模态学习 视觉语言 可解释性 概念发现
📋 核心要点
- 现有稀疏自编码器(SAE)针对单一模态训练,特征不具备直接可解释性,且解释无法跨域迁移。
- LUCID通过学习视觉和语言的共享潜在字典,并保留模态特定信息,实现跨模态特征对齐和概念共享。
- 实验表明,LUCID能够实现patch级别的概念定位,建立跨模态神经元对应关系,并提升概念聚类的鲁棒性。
📝 摘要(中文)
本研究提出LUCID(Learning Unified vision-language sparse Codes for Interpretable concept Discovery),一种统一的视觉-语言稀疏自编码器,旨在学习图像块和文本token表示的共享潜在字典,同时保留特定模态的私有容量。通过将共享编码与学习到的最优传输匹配目标耦合,实现特征对齐,无需手动标注。LUCID产生可解释的共享特征,支持块级定位,建立跨模态神经元对应关系,并增强了基于相似性的评估中概念聚类问题的鲁棒性。利用对齐特性,我们开发了一种基于术语聚类的自动字典解释流程,无需人工观察。分析表明,LUCID的共享特征捕获了超越对象的各种语义类别,包括动作、属性和抽象概念,展示了一种全面的可解释多模态表示方法。
🔬 方法详解
问题定义:现有稀疏自编码器通常针对单一模态进行训练,导致学习到的特征缺乏跨模态的可比性和可解释性。此外,这些方法产生的字典特征难以直接理解,并且其解释能力无法在不同领域之间迁移。因此,如何学习一种统一的、可解释的跨模态表示,是本研究要解决的核心问题。
核心思路:LUCID的核心思路是构建一个统一的视觉-语言稀疏自编码器,通过共享潜在字典来对齐不同模态的特征表示。同时,为了保留模态特定的信息,LUCID还引入了私有容量。通过这种方式,LUCID能够学习到既具有跨模态一致性,又能够区分不同模态特征的表示。
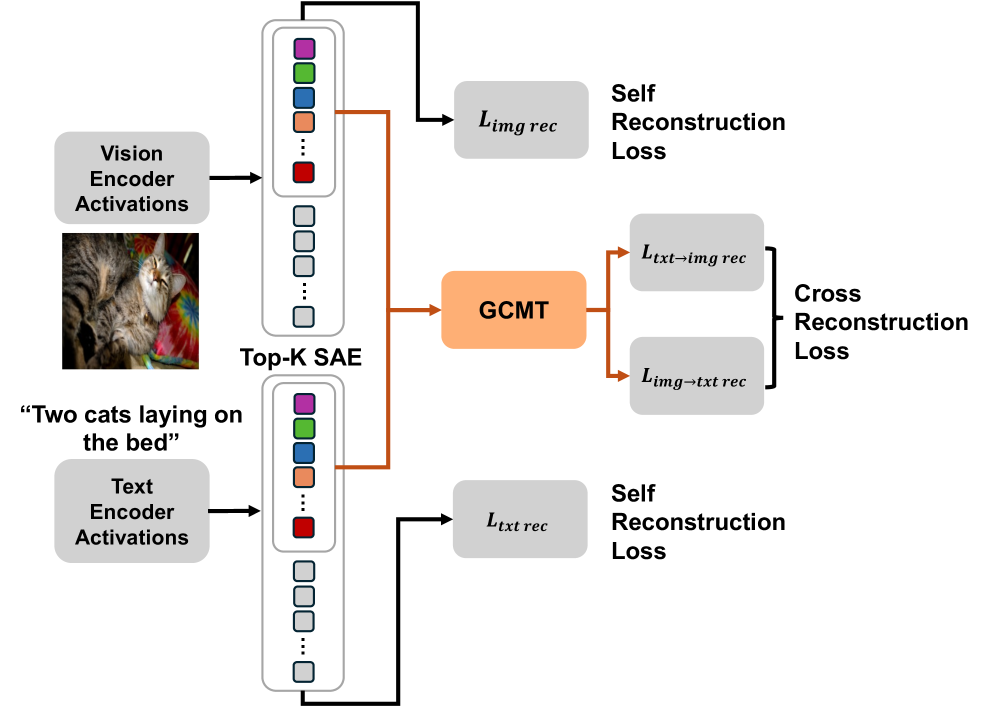
技术框架:LUCID的整体框架包括视觉编码器、语言编码器、共享稀疏自编码器和模态特定的私有自编码器。视觉编码器和语言编码器分别将图像块和文本token映射到特征空间。然后,这些特征被输入到共享稀疏自编码器中,学习共享的潜在表示。同时,视觉和语言特征也分别输入到各自的私有自编码器中,以保留模态特定的信息。最后,通过一个最优传输匹配目标来对齐共享的潜在表示。
关键创新:LUCID最重要的创新点在于它学习了一种统一的视觉-语言稀疏编码,从而实现了跨模态特征的对齐和概念的共享。与现有方法相比,LUCID不需要手动标注,而是通过学习最优传输匹配目标来实现特征对齐。此外,LUCID还能够学习到可解释的共享特征,支持patch级别的概念定位和跨模态神经元对应关系的建立。
关键设计:LUCID的关键设计包括:1) 共享稀疏自编码器的结构,包括编码器和解码器的层数、神经元数量等;2) 最优传输匹配目标的具体形式,以及其权重参数;3) 模态特定的私有自编码器的结构,以及其与共享自编码器的连接方式;4) 稀疏性的约束条件,例如L1正则化系数。
🖼️ 关键图片


📊 实验亮点
LUCID在多个实验中表现出色。通过自动字典解释流程,LUCID能够捕获多种语义类别,包括对象、动作、属性和抽象概念。实验结果表明,LUCID能够有效地对齐跨模态特征,并提升概念聚类的鲁棒性。此外,LUCID还能够建立跨模态神经元对应关系,为理解多模态表示提供了新的视角。
🎯 应用场景
LUCID的应用场景广泛,包括跨模态信息检索、视觉问答、图像描述生成等。通过学习可解释的跨模态表示,LUCID可以提升这些任务的性能,并提供更具解释性的结果。此外,LUCID还可以用于知识发现,例如自动识别图像和文本中存在的概念,并建立它们之间的联系。未来,LUCID有望应用于机器人视觉、智能助手等领域。
📄 摘要(原文)
Sparse autoencoders (SAEs) offer a natural path toward comparable explanations across different representation spaces. However, current SAEs are trained per modality, producing dictionaries whose features are not directly understandable and whose explanations do not transfer across domains. In this study, we introduce LUCID (Learning Unified vision-language sparse Codes for Interpretable concept Discovery), a unified vision-language sparse autoencoder that learns a shared latent dictionary for image patch and text token representations, while reserving private capacity for modality-specific details. We achieve feature alignment by coupling the shared codes with a learned optimal transport matching objective without the need of labeling. LUCID yields interpretable shared features that support patch-level grounding, establish cross-modal neuron correspondence, and enhance robustness against the concept clustering problem in similarity-based evaluation. Leveraging the alignment properties, we develop an automated dictionary interpretation pipeline based on term clustering without manual observations. Our analysis reveals that LUCID's shared features capture diverse semantic categories beyond objects, including actions, attributes, and abstract concepts, demonstrating a comprehensive approach to interpretable multimodal representations.