Cross-View World Models
作者: Rishabh Sharma, Gijs Hogervorst, Wayne E. Mackey, David J. Heeger, Stefano Martiniani
分类: cs.CV, cs.LG
发布日期: 2026-02-07
备注: 12 pages, 7 figures
💡 一句话要点
提出跨视角世界模型,通过视角一致性学习环境的3D表征,提升智能体规划能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 跨视角学习 世界模型 几何正则化 3D表征学习 多视角一致性
📋 核心要点
- 现有世界模型通常仅从单一视角(通常是自我中心视角)进行规划,限制了在需要其他视角辅助的任务中的表现。
- XVWM通过跨视角预测训练,利用不同视角之间的几何一致性,学习环境的视角不变3D表征,从而提升规划能力。
- 在Aimlabs数据集上的实验表明,多视角一致性能够有效学习空间表征,并为多智能体环境中的视角转换提供基础。
📝 摘要(中文)
本文提出跨视角世界模型(XVWM),通过跨视角预测目标进行训练:给定一个视角的帧序列,预测采取行动后相同或不同视角的未来状态。强制跨视角一致性充当几何正则化:由于输入和输出视角可能几乎没有或没有视觉重叠,为了跨视角进行预测,模型必须学习环境3D结构的视角不变表示。我们使用Aimlabs(一个瞄准训练平台,提供精确对齐的多摄像头记录和高频动作标签)的同步多视角游戏数据进行训练。由此产生的模型为智能体提供跨视角的并行想象流,使其能够在最适合任务的参考系中进行规划,同时从自我中心视角执行。结果表明,多视角一致性为空间基础表示提供了强大的学习信号。最后,从另一个视角预测行动的后果可能为多智能体环境中的视角转换奠定基础。
🔬 方法详解
问题定义:现有世界模型主要依赖于单一视角进行环境建模和规划,这在某些任务中存在局限性。例如,导航任务从鸟瞰视角进行规划可能更有效,但传统方法难以利用这种跨视角信息。因此,如何让智能体能够理解和利用不同视角的场景信息,从而提升其规划能力,是一个亟待解决的问题。
核心思路:本文的核心思路是利用跨视角预测作为一种几何正则化手段,迫使模型学习环境的视角不变3D表征。通过让模型预测从一个视角观察到的状态在另一个视角下的未来状态,模型必须理解不同视角之间的几何关系,从而学习到更鲁棒和泛化的环境表示。
技术框架:XVWM的整体框架包含一个编码器,用于将不同视角的输入帧序列编码成潜在状态表示;一个动作编码器,用于编码智能体的动作;以及一个解码器,用于根据潜在状态和动作预测未来状态在目标视角下的图像。训练过程中,模型接收一个视角的图像序列和动作序列作为输入,并预测另一个视角的未来图像。
关键创新:XVWM的关键创新在于引入了跨视角预测目标,通过强制模型学习不同视角之间的一致性,从而学习到环境的视角不变3D表征。这种方法不需要显式的3D重建或监督信息,而是通过自监督的方式学习到几何信息,使得模型能够更好地理解和利用不同视角的场景信息。
关键设计:XVWM使用变分自编码器(VAE)作为其核心架构,以学习潜在状态表示。损失函数包括重构损失(用于确保预测图像与真实图像相似)和KL散度损失(用于正则化潜在空间)。此外,为了更好地利用多视角信息,模型使用了多层感知机(MLP)来融合不同视角的特征表示。
🖼️ 关键图片

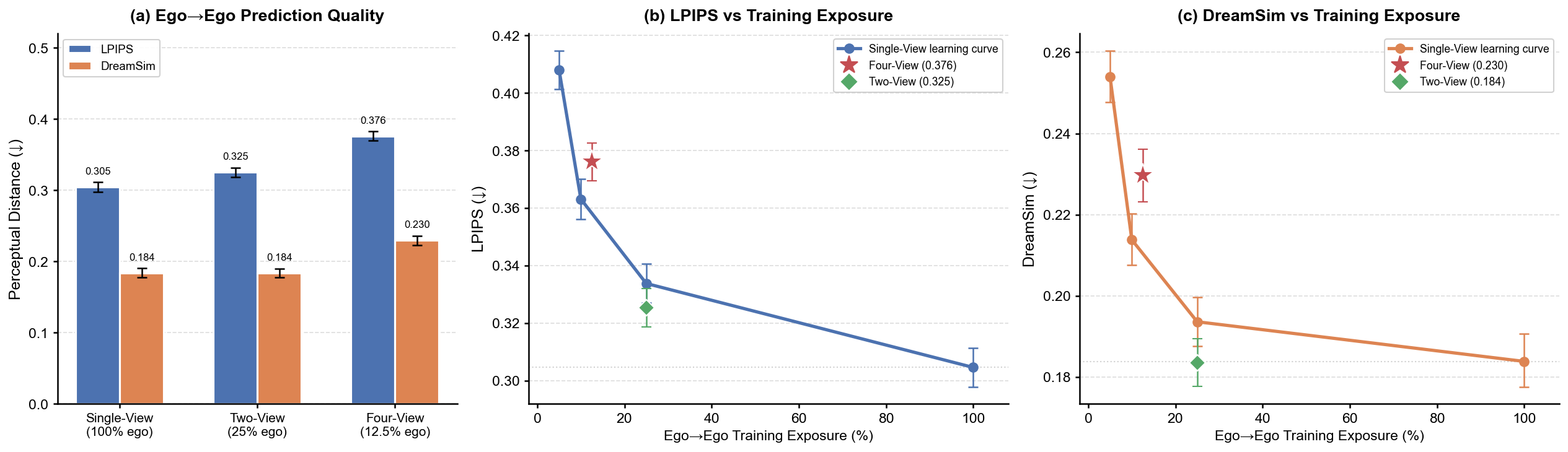
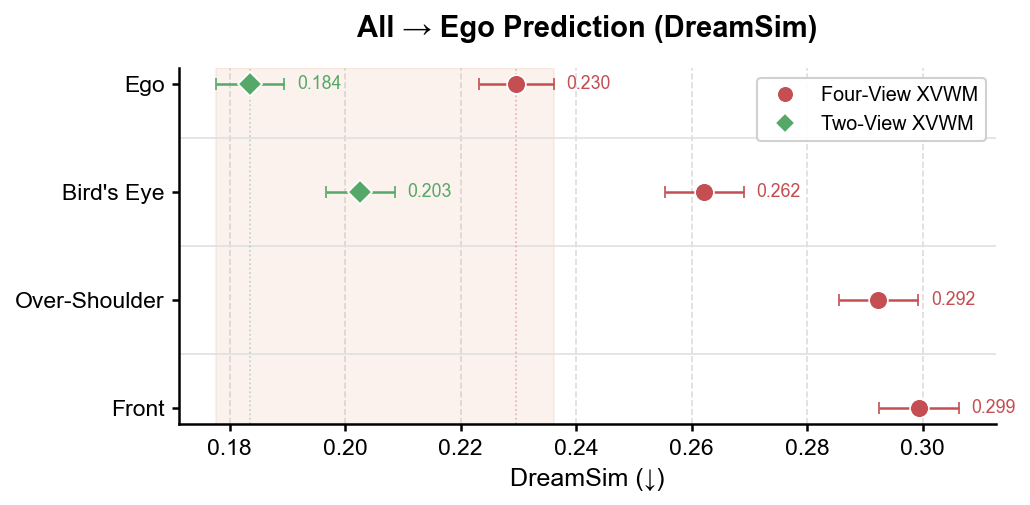
📊 实验亮点
论文在Aimlabs数据集上进行了实验,结果表明XVWM能够有效学习环境的3D表征,并提升智能体的规划能力。具体来说,通过跨视角预测训练,XVWM能够生成更准确的未来状态预测,从而使智能体能够更好地理解环境并制定更有效的策略。此外,实验还表明,多视角一致性能够提供强大的学习信号,从而使模型能够学习到更鲁棒和泛化的环境表示。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、游戏AI等领域。例如,机器人可以利用多个摄像头获取不同视角的图像,并通过XVWM学习环境的3D表征,从而实现更鲁棒的导航和避障。在自动驾驶领域,XVWM可以帮助车辆理解周围环境,并预测其他车辆或行人的行为,从而提高驾驶安全性。在游戏AI领域,XVWM可以使AI角色更好地理解游戏世界,并制定更合理的策略。
📄 摘要(原文)
World models enable agents to plan by imagining future states, but existing approaches operate from a single viewpoint, typically egocentric, even when other perspectives would make planning easier; navigation, for instance, benefits from a bird's-eye view. We introduce Cross-View World Models (XVWM), trained with a cross-view prediction objective: given a sequence of frames from one viewpoint, predict the future state from the same or a different viewpoint after an action is taken. Enforcing cross-view consistency acts as geometric regularization: because the input and output views may share little or no visual overlap, to predict across viewpoints, the model must learn view-invariant representations of the environment's 3D structure. We train on synchronized multi-view gameplay data from Aimlabs, an aim-training platform providing precisely aligned multi-camera recordings with high-frequency action labels. The resulting model gives agents parallel imagination streams across viewpoints, enabling planning in whichever frame of reference best suits the task while executing from the egocentric view. Our results show that multi-view consistency provides a strong learning signal for spatially grounded representations. Finally, predicting the consequences of one's actions from another viewpoint may offer a foundation for perspective-taking in multi-agent settings.