Towards Understanding Multimodal Fine-Tuning: Spatial Features
作者: Lachin Naghashyar, Hunar Batra, Ashkan Khakzar, Philip Torr, Ronald Clark, Christian Schroeder de Witt, Constantin Venhoff
分类: cs.CV, cs.LG
发布日期: 2026-02-06
💡 一句话要点
提出阶段式模型差异分析方法,揭示视觉-语言模型微调过程中空间特征的涌现。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 多模态微调 模型可解释性 空间关系 阶段式模型差异分析
📋 核心要点
- 现有视觉-语言模型缺乏对多模态微调过程中语言模型表征适应性的深入理解,阻碍了模型优化。
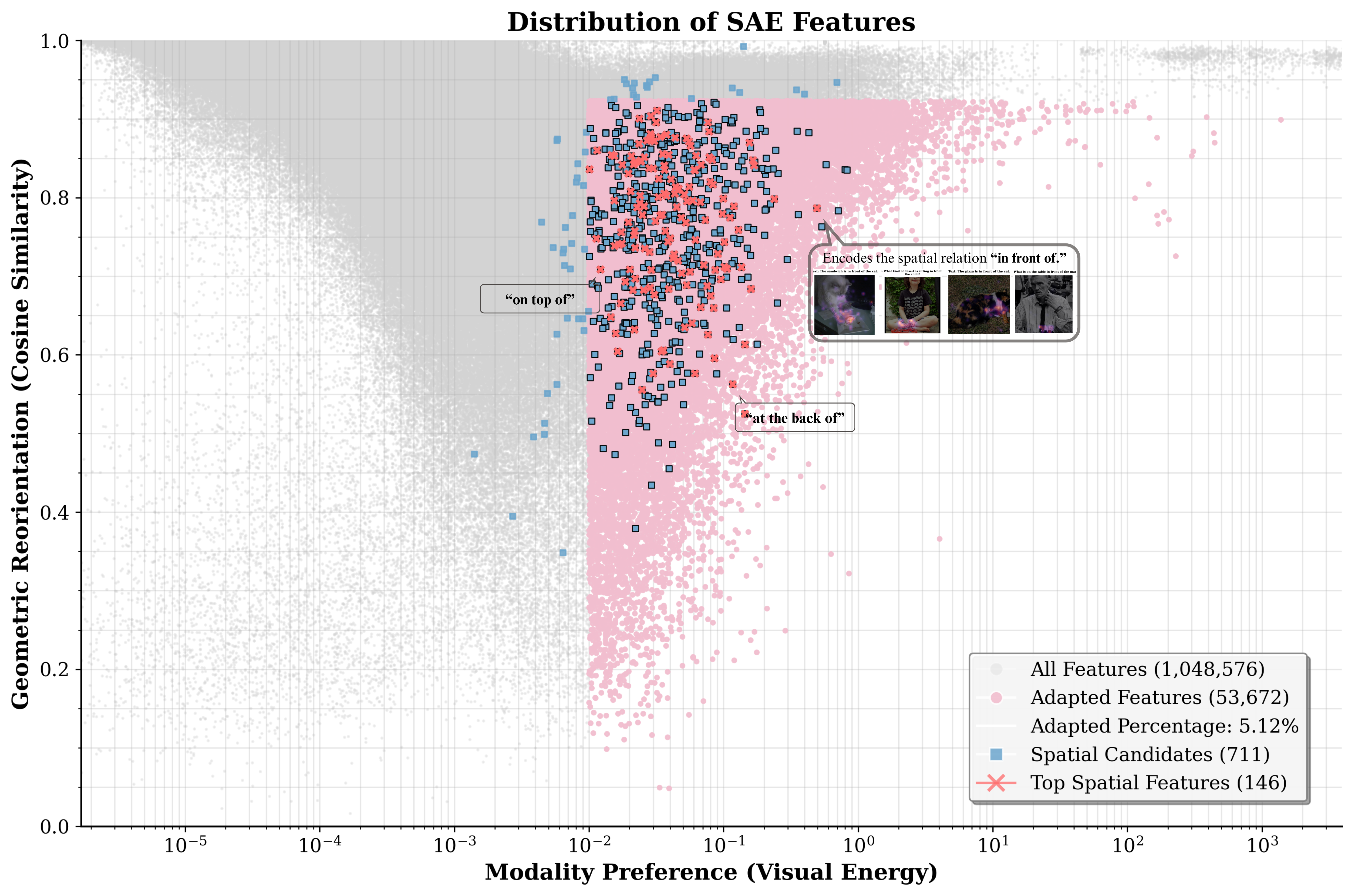
- 论文提出阶段式模型差异分析方法,通过隔离表征变化,揭示语言模型学习“视觉”的过程,关注空间关系编码。
- 研究发现特定特征子集可靠编码空间关系,并能追踪到特定注意力头,为理解模态融合提供了新视角。
📝 摘要(中文)
本文针对视觉-语言模型(VLMs)在视觉-文本输入上进行微调后,语言模型表征如何适应以及视觉特定能力何时出现的问题,提出了首个VLM适应性的机制分析。通过阶段式模型差异分析,一种用于隔离多模态微调期间引入的表征变化的技术,揭示了语言模型如何“看到”。首先,识别出在微调期间出现或重新定向的视觉偏好特征。然后,证明这些特征的选择性子集可靠地编码空间关系,这通过对空间提示的受控移动来揭示。最后,追踪这些特征的因果激活到一小群注意力头。研究结果表明,阶段式模型差异分析揭示了空间相关的多模态特征何时何地产生。它还通过展示视觉基础如何重塑以前仅限文本的特征,从而更清晰地了解模态融合。该方法增强了多模态训练的可解释性,并为理解和改进预训练语言模型如何获得视觉基础能力奠定了基础。
🔬 方法详解
问题定义:现有的视觉-语言模型(VLMs)在各种任务上表现出色,但对于多模态微调过程中,语言模型内部的表征如何适应视觉信息,以及视觉相关的能力何时涌现,缺乏深入的理解。这使得我们难以优化模型的结构和训练过程,以获得更好的性能。现有方法难以解释视觉信息如何融入语言模型,以及哪些特定的神经元或模块负责处理视觉信息。
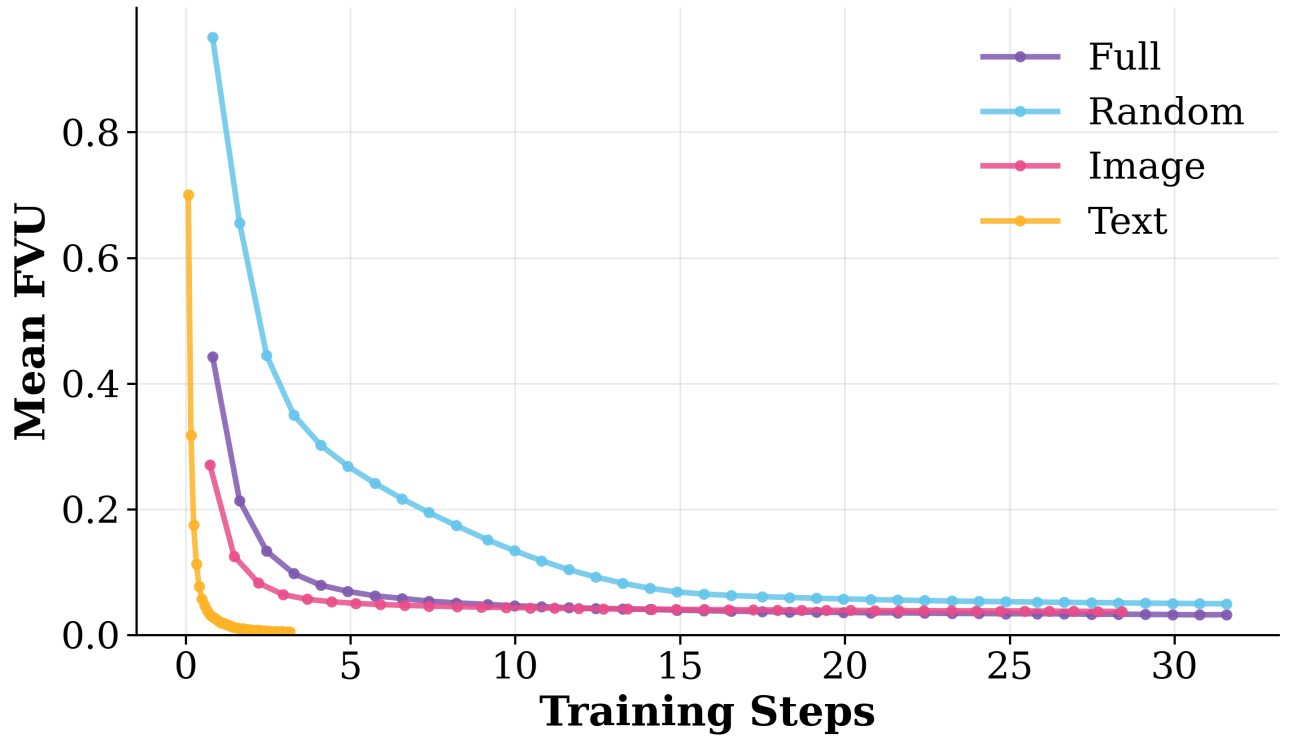
核心思路:本文的核心思路是利用“阶段式模型差异分析”(stage-wise model diffing)来隔离和分析多模态微调过程中引入的表征变化。通过比较微调前后模型的状态,可以识别出哪些特征发生了显著变化,从而揭示语言模型如何学习“看到”。特别关注空间关系,因为空间理解是视觉智能的重要组成部分。
技术框架:该方法主要包含以下几个阶段: 1. 模型微调:首先,在一个预训练的语言模型上,使用视觉-文本数据进行微调,得到一个多模态模型。 2. 阶段式模型差异分析:比较微调前后模型的表征,找出发生显著变化的特征。这可以通过计算不同层或神经元的激活差异来实现。 3. 视觉偏好特征识别:识别出在微调后对视觉信息更加敏感的特征,即“视觉偏好特征”。 4. 空间关系编码分析:分析这些视觉偏好特征是否编码了空间关系。通过控制空间提示的变化,观察特征的激活情况。 5. 因果关系追踪:追踪这些特征的激活到特定的注意力头,从而确定哪些注意力头负责处理空间相关的视觉信息。
关键创新:最重要的技术创新点在于“阶段式模型差异分析”方法,它提供了一种系统性的方式来理解多模态微调过程中模型内部的变化。与传统的黑盒方法不同,该方法能够揭示哪些特征和模块负责处理视觉信息,以及它们是如何相互作用的。此外,关注空间关系编码也是一个重要的创新点,因为它将研究重点放在了视觉智能的一个关键方面。
关键设计:论文中可能包含以下关键设计细节(由于摘要信息有限,部分内容未知): * 差异计算方法:如何量化微调前后特征的差异?可能使用了某种距离度量或相似度指标。 * 视觉偏好特征的定义:如何定义一个特征是“视觉偏好”的?可能使用了某种激活阈值或信息增益指标。 * 空间提示的设计:如何设计空间提示,以便能够有效地测试特征是否编码了空间关系? * 注意力头追踪方法:如何追踪特征的激活到特定的注意力头?可能使用了某种梯度分析或因果推断方法。
🖼️ 关键图片

📊 实验亮点
该研究通过阶段式模型差异分析,成功识别出视觉-语言模型微调过程中涌现的空间关系编码特征,并追踪到负责激活这些特征的特定注意力头。实验结果表明,该方法能够有效地揭示语言模型如何学习“看到”,为理解多模态融合提供了新的视角。具体性能数据和对比基线在摘要中未提及,属于未知信息。
🎯 应用场景
该研究成果可应用于提升视觉-语言模型的性能和可解释性。例如,可以利用该方法优化模型结构,提高其空间推理能力,从而改善图像描述、视觉问答等任务的性能。此外,该方法还可以用于诊断模型的缺陷,例如识别模型在哪些情况下无法正确理解空间关系,从而有针对性地进行改进。该研究为开发更智能、更可靠的多模态人工智能系统奠定了基础。
📄 摘要(原文)
Contemporary Vision-Language Models (VLMs) achieve strong performance on a wide range of tasks by pairing a vision encoder with a pre-trained language model, fine-tuned for visual-text inputs. Yet despite these gains, it remains unclear how language backbone representations adapt during multimodal training and when vision-specific capabilities emerge. In this work, we present the first mechanistic analysis of VLM adaptation. Using stage-wise model diffing, a technique that isolates representational changes introduced during multimodal fine-tuning, we reveal how a language model learns to "see". We first identify vision-preferring features that emerge or reorient during fine-tuning. We then show that a selective subset of these features reliably encodes spatial relations, revealed through controlled shifts to spatial prompts. Finally, we trace the causal activation of these features to a small group of attention heads. Our findings show that stage-wise model diffing reveals when and where spatially grounded multimodal features arise. It also provides a clearer view of modality fusion by showing how visual grounding reshapes features that were previously text-only. This methodology enhances the interpretability of multimodal training and provides a foundation for understanding and refining how pretrained language models acquire vision-grounded capabilities.