Ex-Omni: Enabling 3D Facial Animation Generation for Omni-modal Large Language Models
作者: Haoyu Zhang, Zhipeng Li, Yiwen Guo, Tianshu Yu
分类: cs.CV, cs.AI, cs.CL
发布日期: 2026-02-06
💡 一句话要点
Ex-Omni:为全模态大语言模型实现语音驱动的3D面部动画生成
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 全模态大语言模型 3D面部动画 语音驱动 语义推理 时间生成 解耦学习 门控融合
📋 核心要点
- 现有全模态大语言模型在结合语音和3D面部动画方面存在不足,难以实现自然交互。
- Ex-Omni通过解耦语义推理和时间生成,并使用语音单元作为时间支架来简化学习过程。
- 实验表明,Ex-Omni在生成对齐的语音和面部动画方面表现出色,并与现有OLLM具有竞争力。
📝 摘要(中文)
全模态大语言模型(OLLMs)旨在统一多模态理解和生成,但将语音与3D面部动画结合仍然是一个未被充分探索的领域,尽管它对于自然交互至关重要。一个关键挑战来自于LLM中离散的、token级别的语义推理与3D面部运动所需的密集、细粒度的时间动态之间的表示不匹配,这使得在有限数据下直接建模难以优化。我们提出了Expressive Omni (Ex-Omni),一个开源的全模态框架,它用语音伴随的3D面部动画来增强OLLM。Ex-Omni通过将语义推理与时间生成解耦来降低学习难度,利用语音单元作为时间支架,并采用统一的token-as-query门控融合(TQGF)机制进行受控的语义注入。我们进一步引入了InstructEx数据集,旨在促进用语音伴随的3D面部动画来增强OLLM。大量实验表明,Ex-Omni在实现稳定对齐的语音和面部动画生成的同时,其性能与现有的开源OLLM相比具有竞争力。
🔬 方法详解
问题定义:现有方法难以将语音与3D面部动画有效结合,主要痛点在于LLM的离散token表示与3D面部动画的连续时序动态之间存在鸿沟,导致直接建模优化困难,尤其是在数据有限的情况下。
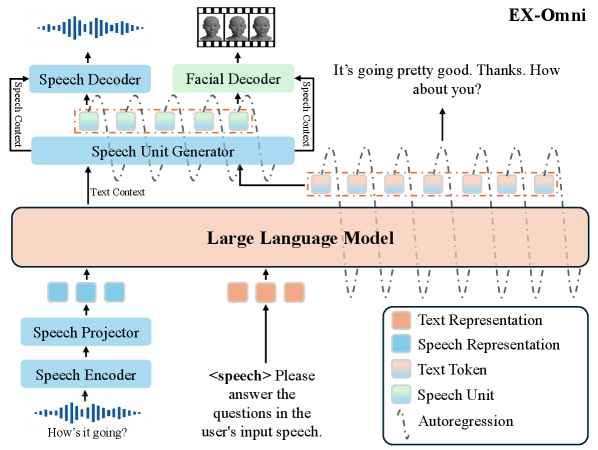
核心思路:Ex-Omni的核心思路是将语义推理与时间生成解耦。具体来说,利用语音单元(如音素或词素)作为时间轴上的锚点,将连续的面部动画生成问题转化为在这些锚点上进行控制的生成问题,从而降低学习难度。同时,通过可控的语义注入,保证面部动画与语音内容的一致性。
技术框架:Ex-Omni框架主要包含以下几个模块:1) 语音特征提取模块,用于提取语音的声学特征和语义信息;2) 语音单元提取模块,用于将语音分割成离散的单元序列;3) Token-as-Query门控融合(TQGF)模块,用于将LLM的语义信息与语音单元进行融合,生成控制信号;4) 3D面部动画生成模块,根据控制信号生成连续的3D面部动画。整个流程是:语音输入 -> 特征提取 -> 单元分割 -> 语义融合 -> 动画生成。
关键创新:Ex-Omni的关键创新在于:1) 将语义推理与时间生成解耦,降低了学习难度;2) 提出了Token-as-Query门控融合(TQGF)机制,实现了对语义信息的精确控制和注入;3) 构建了InstructEx数据集,为训练和评估语音驱动的3D面部动画生成模型提供了数据支持。
关键设计:TQGF模块的设计是关键。它将LLM的token表示作为query,去查询语音单元的特征,然后通过一个门控机制来控制语义信息的注入量。损失函数方面,可能采用了L1或L2损失来约束生成的3D面部动画与目标动画之间的差异,同时可能加入了对抗损失来提高生成动画的真实感。具体的网络结构细节(如Transformer的层数、隐藏层维度等)未知,需要参考论文的具体实现。
🖼️ 关键图片

📊 实验亮点
Ex-Omni在实验中表现出与现有开源OLLM相当的性能,同时实现了稳定对齐的语音和面部动画生成。具体的性能指标(如动画质量、对齐精度等)和对比基线未知,但摘要强调了其竞争力和稳定性。
🎯 应用场景
Ex-Omni具有广泛的应用前景,例如虚拟助手、游戏角色动画、在线教育、电影制作等。它可以用于创建更具表现力和互动性的虚拟角色,提升用户体验。未来,该技术有望应用于更复杂的场景,例如实时语音驱动的3D面部动画生成,以及个性化的虚拟形象定制。
📄 摘要(原文)
Omni-modal large language models (OLLMs) aim to unify multimodal understanding and generation, yet incorporating speech with 3D facial animation remains largely unexplored despite its importance for natural interaction. A key challenge arises from the representation mismatch between discrete, token-level semantic reasoning in LLMs and the dense, fine-grained temporal dynamics required for 3D facial motion, which makes direct modeling difficult to optimize under limited data. We propose Expressive Omni (Ex-Omni), an open-source omni-modal framework that augments OLLMs with speech-accompanied 3D facial animation. Ex-Omni reduces learning difficulty by decoupling semantic reasoning from temporal generation, leveraging speech units as temporal scaffolding and a unified token-as-query gated fusion (TQGF) mechanism for controlled semantic injection. We further introduce InstructEx, a dataset aims to facilitate augment OLLMs with speech-accompanied 3D facial animation. Extensive experiments demonstrate that Ex-Omni performs competitively against existing open-source OLLMs while enabling stable aligned speech and facial animation generation.