MedMO: Grounding and Understanding Multimodal Large Language Model for Medical Images
作者: Ankan Deria, Komal Kumar, Adinath Madhavrao Dukre, Eran Segal, Salman Khan, Imran Razzak
分类: cs.CV
发布日期: 2026-02-06
备注: 21 pages, 6 figures and 4 tables
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
MedMO:用于医学图像的具身和理解多模态大型语言模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 医学图像 大型语言模型 指令调优 强化学习
📋 核心要点
- 医学领域缺乏领域知识和模态对齐的MLLM,限制了其在医学图像理解和推理方面的应用。
- MedMO通过多阶段训练,包括跨模态预训练、指令调优和强化学习,提升模型在医学领域的性能。
- 实验结果表明,MedMO在VQA、文本QA和医学报告生成等任务上显著优于现有模型,并具有强大的空间推理能力。
📝 摘要(中文)
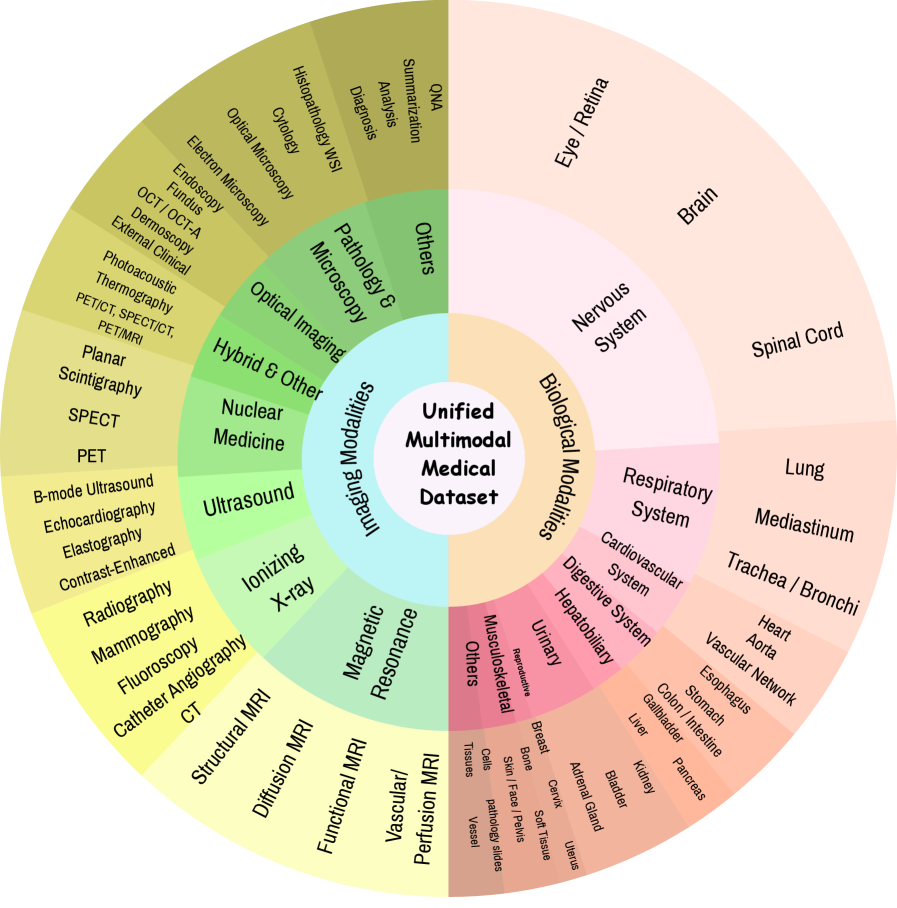
多模态大型语言模型(MLLM)发展迅速,但由于领域覆盖范围、模态对齐和具身推理方面的差距,其在医学领域的应用仍然有限。本文介绍了MedMO,一个建立在通用MLLM架构之上,并专门在大型领域特定数据上训练的医学基础模型。MedMO遵循多阶段训练方案:(i)跨模态预训练,将异构视觉编码器与医学语言骨干对齐;(ii)在多任务监督下进行指令调优,涵盖字幕生成、VQA、报告生成、检索以及带有边界框的具身疾病定位;(iii)使用可验证奖励的强化学习,将事实性检查与框级GIoU奖励相结合,以加强复杂临床场景中的空间具身和逐步推理。MedMO在多个模态和任务上始终优于强大的开源医学MLLM。在VQA基准测试中,MedMO的平均准确率比基线提高了+13.7%,并且性能与SOTA Fleming-VL相差1.9%。对于基于文本的QA,它比基线提高了+6.9%,比Fleming-VL提高了+14.5%。在医学报告生成方面,MedMO在语义和临床准确性方面都取得了显著提高。此外,它还表现出强大的具身能力,IoU比基线提高了+40.4%,比Fleming-VL提高了+37.0%,突显了其强大的空间推理和定位性能。在放射学、眼科和病理学-显微镜检查方面的评估证实了MedMO广泛的跨模态泛化能力。我们发布了两个版本的MedMO:4B和8B。项目地址:https://genmilab.github.io/MedMO-Page
🔬 方法详解
问题定义:现有MLLM在医学图像理解方面存在不足,主要体现在领域知识的缺乏、不同模态信息对齐困难以及空间推理能力不足。这些问题限制了MLLM在医学图像分析、诊断和报告生成等方面的应用。现有方法难以有效利用医学图像中的空间信息,无法进行精确的疾病定位和诊断。
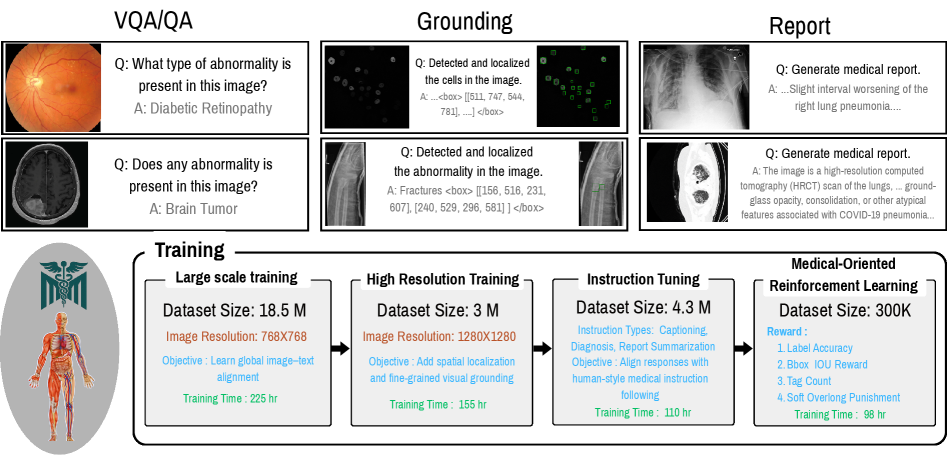
核心思路:MedMO的核心思路是构建一个专门针对医学领域的多模态大型语言模型,通过大规模的领域特定数据进行训练,从而提升模型在医学图像理解和推理方面的能力。该模型采用多阶段训练策略,包括跨模态预训练、指令调优和强化学习,以实现更好的模态对齐、任务泛化和空间推理能力。
技术框架:MedMO的整体架构包括以下几个主要模块:1) 异构视觉编码器,用于提取不同模态医学图像的特征;2) 医学语言骨干,用于处理文本信息并进行语言建模;3) 跨模态对齐模块,用于将视觉特征和语言特征对齐到同一语义空间;4) 多任务学习模块,用于在多个医学任务上进行训练,包括字幕生成、VQA、报告生成、检索和疾病定位;5) 强化学习模块,用于提升模型的空间推理能力和逐步推理能力。
关键创新:MedMO的关键创新在于以下几个方面:1) 专门针对医学领域构建的多模态大型语言模型;2) 多阶段训练策略,包括跨模态预训练、指令调优和强化学习;3) 引入可验证奖励的强化学习,结合事实性检查和框级GIoU奖励,以加强空间具身和逐步推理能力。
关键设计:MedMO的关键设计包括:1) 使用大规模的医学图像和文本数据进行预训练;2) 设计多任务学习目标,涵盖多种医学任务;3) 使用GIoU作为强化学习的奖励函数,以提升疾病定位的准确性;4) 使用可验证奖励,确保生成结果的事实性和临床准确性。
🖼️ 关键图片
📊 实验亮点
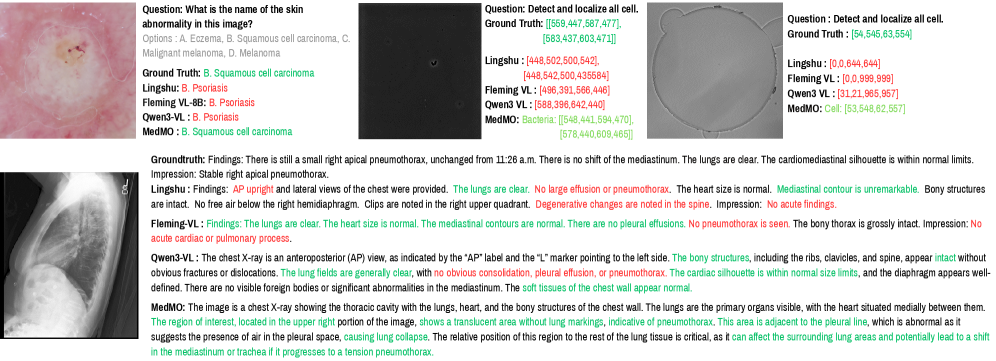
MedMO在多个医学任务上取得了显著的性能提升。在VQA基准测试中,MedMO的平均准确率比基线提高了+13.7%,接近SOTA模型Fleming-VL。在文本QA任务中,MedMO比基线提高了+6.9%,比Fleming-VL提高了+14.5%。在医学报告生成方面,MedMO在语义和临床准确性方面都取得了显著提高。此外,MedMO在疾病定位方面表现出色,IoU比基线提高了+40.4%,比Fleming-VL提高了+37.0%。
🎯 应用场景
MedMO具有广泛的应用前景,包括医学图像分析、辅助诊断、医学报告生成、医学教育和远程医疗等。它可以帮助医生更准确地诊断疾病,提高诊断效率,并为患者提供更好的医疗服务。未来,MedMO有望成为医学领域的重要工具,推动医疗智能化发展。
📄 摘要(原文)
Multimodal large language models (MLLMs) have rapidly advanced, yet their adoption in medicine remains limited by gaps in domain coverage, modality alignment, and grounded reasoning. In this work, we introduce MedMO, a medical foundation model built upon a generalized MLLM architecture and trained exclusively on large-scale, domain-specific data. MedMO follows a multi-stage training recipe: (i) cross-modal pretraining to align heterogeneous visual encoders with a medical language backbone; (ii) instruction tuning on multi-task supervision that spans captioning, VQA, report generation, retrieval, and grounded disease localization with bounding boxes; and (iii) reinforcement learning with verifiable rewards that combine factuality checks with a box-level GIoU reward to strengthen spatial grounding and step-by-step reasoning in complex clinical scenarios. MedMO consistently outperforms strong open-source medical MLLMs across multiple modalities and tasks. On VQA benchmarks, MedMO achieves an average accuracy improvement of +13.7% over the baseline and performs within 1.9% of the SOTA Fleming-VL. For text-based QA, it attains +6.9% over the baseline and +14.5% over Fleming-VL. In medical report generation, MedMO delivers significant gains in both semantic and clinical accuracy. Moreover, it exhibits strong grounding capability, achieving an IoU improvement of +40.4 over the baseline and +37.0% over Fleming-VL, underscoring its robust spatial reasoning and localization performance. Evaluations across radiology, ophthalmology, and pathology-microscopy confirm MedMO's broad cross-modality generalization. We release two versions of MedMO: 4B and 8B. Project is available at https://genmilab.github.io/MedMO-Page