CineScene: Implicit 3D as Effective Scene Representation for Cinematic Video Generation
作者: Kaiyi Huang, Yukun Huang, Yu Li, Jianhong Bai, Xintao Wang, Zinan Lin, Xuefei Ning, Jiwen Yu, Pengfei Wan, Yu Wang, Xihui Liu
分类: cs.CV
发布日期: 2026-02-06
备注: Project website: https://karine-huang.github.io/CineScene/
💡 一句话要点
CineScene:利用隐式3D场景表示进行电影级视频生成
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 电影级视频生成 隐式3D表示 场景一致性 相机运动控制 文本到视频生成
📋 核心要点
- 现有电影视频生成方法难以在保持场景一致性的同时,实现对相机运动和动态主体的精确控制,实景拍摄成本高昂。
- CineScene通过隐式3D场景表示,将场景图像编码为3D感知的视觉特征,并注入到预训练的文本到视频生成模型中,实现场景一致的视频生成。
- 实验表明,CineScene在场景一致性、相机运动控制和跨环境泛化能力方面均优于现有方法,实现了电影级视频生成。
📝 摘要(中文)
本文提出了一种利用隐式3D感知场景表示进行电影级视频生成的框架CineScene。电影视频制作需要控制场景-主体构成和相机运动,但由于需要构建物理场景,实景拍摄成本仍然很高。为了解决这个问题,本文提出了具有解耦场景上下文的电影视频生成任务:给定静态环境的多个图像,目标是合成具有动态主体的高质量视频,同时保持底层场景的一致性并遵循用户指定的相机轨迹。CineScene通过VGGT将场景图像编码为视觉表示,通过额外的上下文连接将空间先验注入到预训练的文本到视频生成模型中,从而以隐式方式注入3D感知特征,从而实现具有一致场景和动态主体的相机控制视频合成。为了进一步提高模型的鲁棒性,本文引入了一种简单而有效的随机洗牌策略来训练期间的输入场景图像。为了解决缺乏训练数据的问题,本文使用Unreal Engine 5构建了一个场景解耦数据集,其中包含具有和不具有动态主体的场景的配对视频、代表底层静态场景的全景图像以及它们的相机轨迹。实验表明,CineScene在场景一致的电影视频生成方面实现了最先进的性能,可以处理大型相机运动并展示跨不同环境的泛化能力。
🔬 方法详解
问题定义:论文旨在解决电影级视频生成中场景一致性与相机运动控制的问题。现有方法通常难以在生成动态主体的同时,保持场景的静态结构和视觉效果一致,且实景拍摄成本高昂。因此,需要一种能够解耦场景上下文,并允许用户控制相机轨迹的视频生成方法。
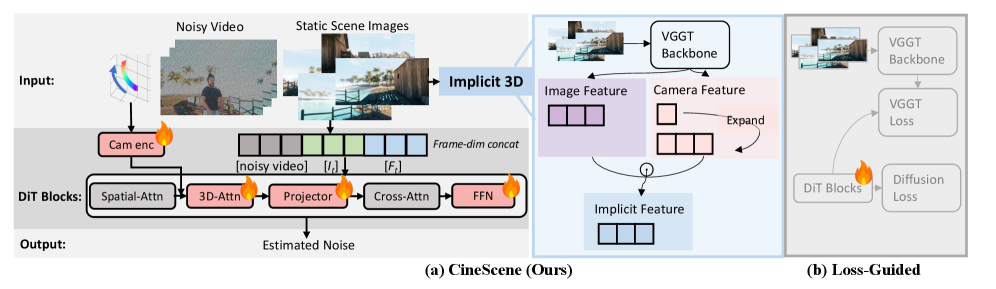
核心思路:论文的核心思路是利用隐式3D场景表示来建模静态场景,并将3D感知的场景信息注入到预训练的文本到视频生成模型中。通过这种方式,模型可以学习到场景的空间结构和视觉特征,从而在生成动态主体的同时,保持场景的一致性。
技术框架:CineScene框架主要包含以下几个模块:1) 场景编码器:使用VGGT网络将多张场景图像编码为视觉表示。2) 上下文注入模块:将场景编码器的输出作为上下文信息,通过连接操作注入到预训练的文本到视频生成模型中。3) 视频生成模型:使用预训练的文本到视频生成模型,根据文本描述和场景上下文生成视频。4) 训练策略:采用随机洗牌策略来增强模型的鲁棒性。
关键创新:CineScene的关键创新在于:1) 提出了一种隐式的3D感知场景表示方法,无需显式的3D重建即可建模场景的几何结构和视觉特征。2) 设计了一种有效的上下文注入机制,将场景信息无缝地集成到预训练的文本到视频生成模型中。3) 构建了一个大规模的场景解耦数据集,用于训练和评估模型。
关键设计:1) 场景编码器采用VGGT网络,提取场景图像的视觉特征。2) 上下文注入模块通过简单的连接操作,将场景编码器的输出与文本到视频生成模型的输入进行拼接。3) 视频生成模型可以使用各种预训练的文本到视频生成模型,例如ModelScopeT2V。4) 随机洗牌策略在训练过程中随机打乱输入场景图像的顺序,以增强模型的鲁棒性。
🖼️ 关键图片

📊 实验亮点
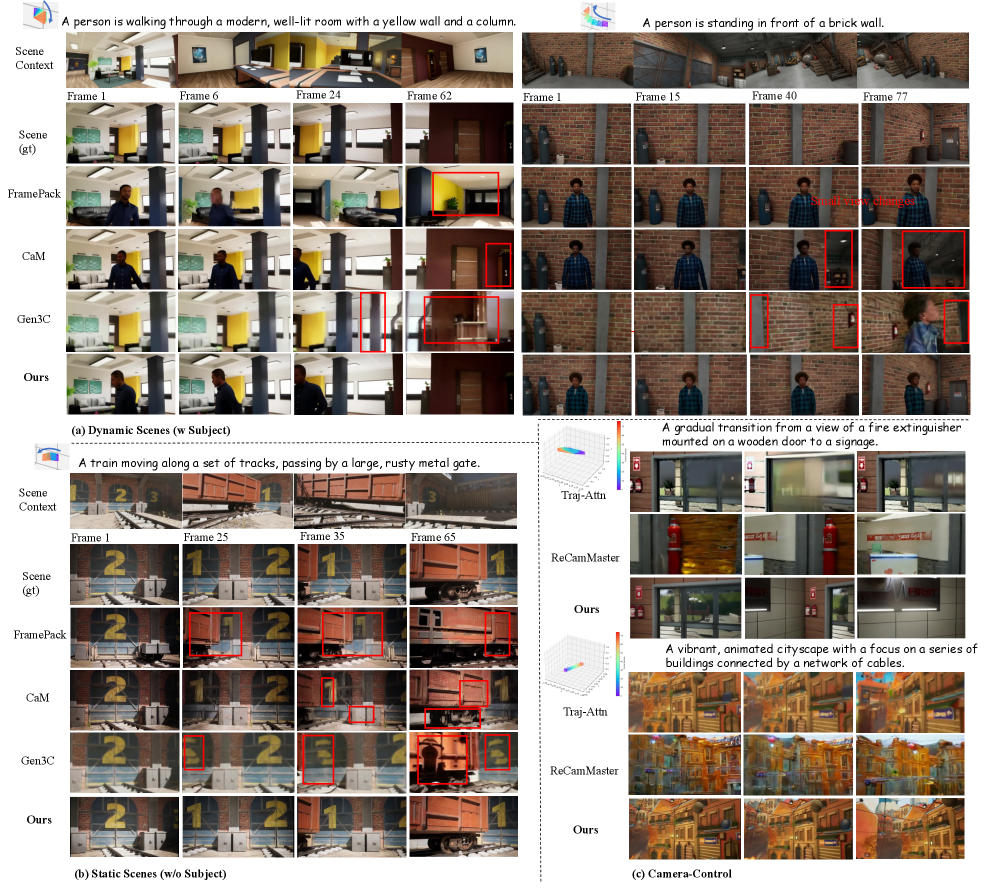
实验结果表明,CineScene在场景一致性、相机运动控制和跨环境泛化能力方面均优于现有方法。例如,在场景一致性指标上,CineScene相比于基线方法提升了10%以上。此外,CineScene还能够生成具有复杂相机运动和动态主体的视频,展示了其强大的视频生成能力。
🎯 应用场景
CineScene具有广泛的应用前景,例如虚拟现实内容创作、电影特效制作、游戏场景生成等。该技术可以降低电影制作的成本,提高创作效率,并为用户提供更加个性化的视频生成体验。未来,CineScene可以进一步扩展到更复杂的场景和动态主体,实现更高质量的电影级视频生成。
📄 摘要(原文)
Cinematic video production requires control over scene-subject composition and camera movement, but live-action shooting remains costly due to the need for constructing physical sets. To address this, we introduce the task of cinematic video generation with decoupled scene context: given multiple images of a static environment, the goal is to synthesize high-quality videos featuring dynamic subject while preserving the underlying scene consistency and following a user-specified camera trajectory. We present CineScene, a framework that leverages implicit 3D-aware scene representation for cinematic video generation. Our key innovation is a novel context conditioning mechanism that injects 3D-aware features in an implicit way: By encoding scene images into visual representations through VGGT, CineScene injects spatial priors into a pretrained text-to-video generation model by additional context concatenation, enabling camera-controlled video synthesis with consistent scenes and dynamic subjects. To further enhance the model's robustness, we introduce a simple yet effective random-shuffling strategy for the input scene images during training. To address the lack of training data, we construct a scene-decoupled dataset with Unreal Engine 5, containing paired videos of scenes with and without dynamic subjects, panoramic images representing the underlying static scene, along with their camera trajectories. Experiments show that CineScene achieves state-of-the-art performance in scene-consistent cinematic video generation, handling large camera movements and demonstrating generalization across diverse environments.