Seeing Beyond Redundancy: Task Complexity's Role in Vision Token Specialization in VLLMs
作者: Darryl Hannan, John Cooper, Dylan White, Yijing Watkins
分类: cs.CV
发布日期: 2026-02-06
备注: 25 pages
💡 一句话要点
研究视觉语言模型中任务复杂度对视觉token特化的影响
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 任务复杂度 视觉冗余 视觉token特化 合成数据集
📋 核心要点
- VLLM在处理精细视觉信息和空间推理任务时表现不佳,现有研究对原因的理解尚不充分。
- 该研究通过构建合成数据集和设计指标,深入分析了任务复杂度与视觉信息处理之间的关系。
- 实验表明,增加训练数据中高复杂度视觉信息的比例,可以改善VLLM在复杂视觉任务上的性能。
📝 摘要(中文)
视觉语言模型(VLLM)的视觉能力一直落后于其语言能力。尤其是在需要精细视觉信息或空间推理时,VLLM表现不佳。本文深入研究了视觉冗余问题,旨在更好地理解模型如何处理各种类型的视觉信息以及丢弃哪些类型的视觉信息。为此,作者构建了一个简单的合成基准数据集,专门用于探测各种视觉特征,并设计了一组用于测量视觉冗余的指标,从而更好地理解它们之间的关系。通过在多个复杂视觉任务上微调VLLM,研究了冗余和压缩如何根据训练数据的复杂性而变化。研究发现任务复杂性与视觉压缩之间存在联系,这意味着拥有足够比例的高复杂度视觉数据对于改变VLLM分配视觉表示的方式,从而提高其在复杂视觉任务上的性能至关重要。这项工作为训练下一代VLLM提供了有价值的见解。
🔬 方法详解
问题定义:VLLM在处理需要精细视觉信息或空间推理的任务时表现不佳,现有方法难以有效利用视觉信息,存在视觉冗余问题,即高层视觉信息分散在多个token中,而精细视觉信息被丢弃。论文旨在探究任务复杂度如何影响VLLM对视觉信息的处理和压缩,从而提升其在复杂视觉任务上的性能。
核心思路:论文的核心思路是任务的复杂度会影响视觉信息的压缩程度。通过构建不同复杂度的视觉任务,观察VLLM在处理这些任务时视觉token的特化程度和信息冗余度,从而揭示任务复杂度与视觉表征之间的关系。如果模型在复杂任务上训练,它将学会更有效地压缩和利用视觉信息。
技术框架:论文主要包含以下几个阶段:1) 构建合成数据集:设计包含不同视觉特征(如颜色、形状、位置等)的合成图像,并控制其复杂度。2) 定义视觉冗余指标:设计指标来量化视觉信息在不同token中的分布情况,以及信息的冗余程度。3) 微调VLLM:在不同复杂度的合成数据集上微调VLLM。4) 分析实验结果:分析微调后VLLM的视觉token特化程度、信息冗余度以及在复杂视觉任务上的性能。
关键创新:论文的关键创新在于:1) 提出了任务复杂度影响视觉表征的观点,并提供了实验证据。2) 设计了合成数据集和视觉冗余指标,用于定量分析VLLM对视觉信息的处理方式。3) 揭示了通过增加训练数据中高复杂度视觉信息的比例,可以改善VLLM在复杂视觉任务上的性能。
关键设计:论文的关键设计包括:1) 合成数据集的设计:需要精心设计视觉特征和复杂度,以确保能够有效探测VLLM对不同类型视觉信息的处理能力。2) 视觉冗余指标的设计:需要能够准确量化视觉信息在不同token中的分布情况,以及信息的冗余程度。3) 微调策略的设计:需要选择合适的VLLM架构和微调参数,以确保能够有效训练模型。
🖼️ 关键图片
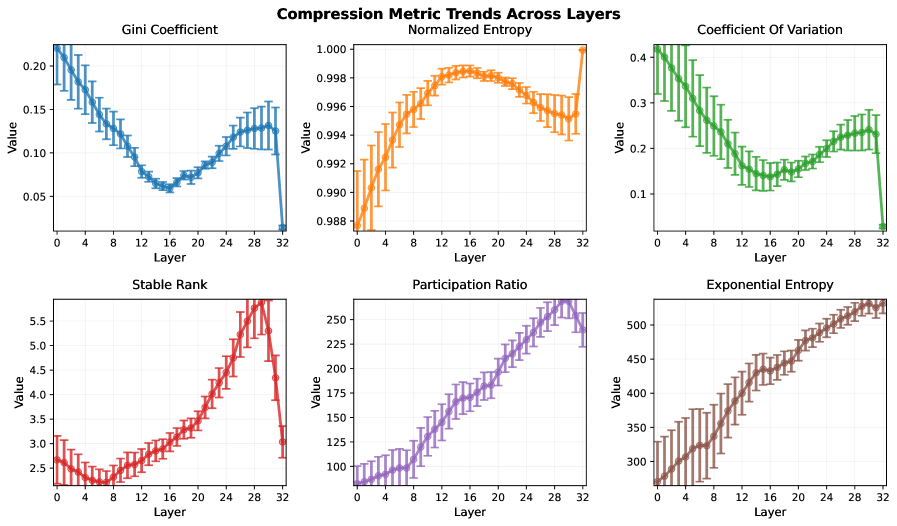
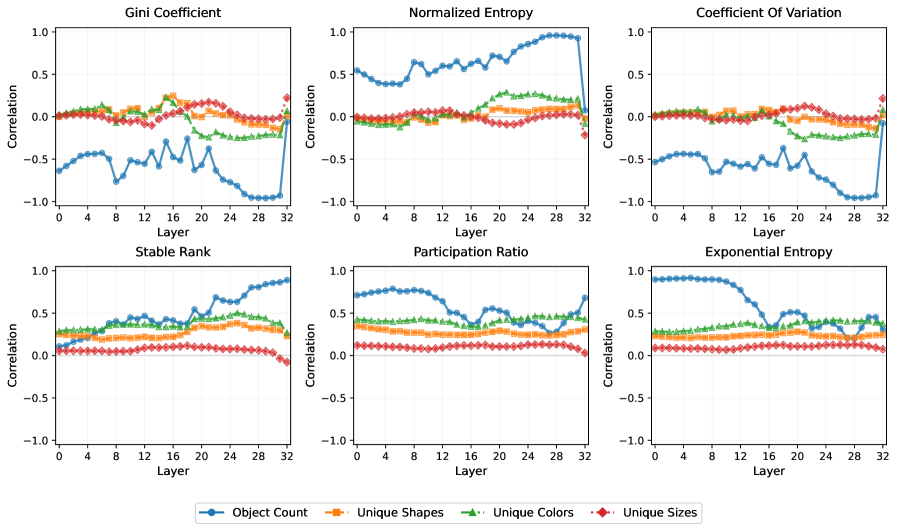
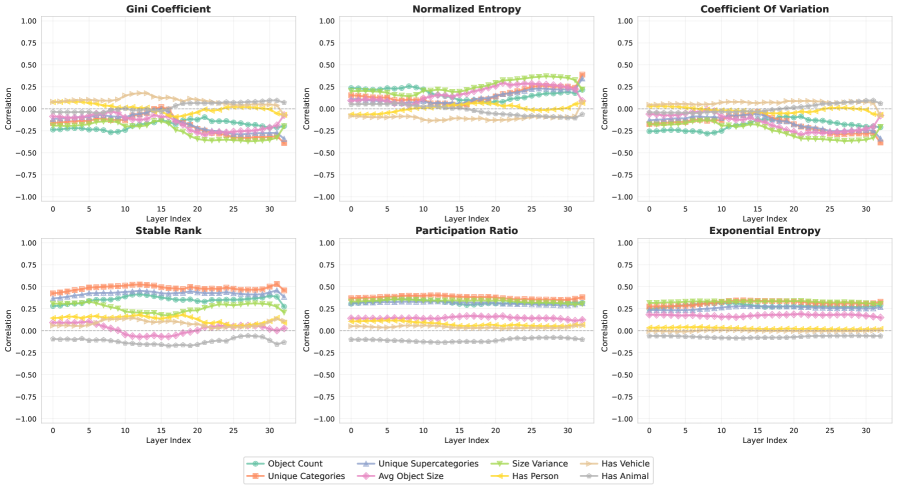
📊 实验亮点
研究发现,通过在包含高复杂度视觉信息的合成数据集上微调VLLM,可以显著降低视觉信息的冗余度,并提升模型在复杂视觉任务上的性能。实验结果表明,任务复杂度与视觉压缩之间存在正相关关系,为VLLM的训练提供了新的思路。
🎯 应用场景
该研究成果可应用于提升VLLM在需要精细视觉理解的任务中的性能,例如图像编辑、视觉问答、机器人导航等。通过优化训练数据和模型结构,可以使VLLM更好地理解和利用视觉信息,从而实现更智能的人机交互。
📄 摘要(原文)
Vision capabilities in vision large language models (VLLMs) have consistently lagged behind their linguistic capabilities. In particular, numerous benchmark studies have demonstrated that VLLMs struggle when fine-grained visual information or spatial reasoning is required. However, we do not yet understand exactly why VLLMs struggle so much with these tasks relative to others. Some works have focused on visual redundancy as an explanation, where high-level visual information is uniformly spread across numerous tokens and specific, fine-grained visual information is discarded. In this work, we investigate this premise in greater detail, seeking to better understand exactly how various types of visual information are processed by the model and what types of visual information are discarded. To do so, we introduce a simple synthetic benchmark dataset that is specifically constructed to probe various visual features, along with a set of metrics for measuring visual redundancy, allowing us to better understand the nuances of their relationship. Then, we explore fine-tuning VLLMs on a number of complex visual tasks to better understand how redundancy and compression change based upon the complexity of the data that a model is trained on. We find that there is a connection between task complexity and visual compression, implying that having a sufficient ratio of high complexity visual data is crucial for altering the way that VLLMs distribute their visual representation and consequently improving their performance on complex visual tasks. We hope that this work will provide valuable insights for training the next generation of VLLMs.