NanoFLUX: Distillation-Driven Compression of Large Text-to-Image Generation Models for Mobile Devices
作者: Ruchika Chavhan, Malcolm Chadwick, Alberto Gil Couto Pimentel Ramos, Luca Morreale, Mehdi Noroozi, Abhinav Mehrotra
分类: cs.CV, cs.AI
发布日期: 2026-02-06
💡 一句话要点
NanoFLUX:提出一种基于蒸馏的文本到图像生成模型压缩方法,用于移动设备。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 文本到图像生成 模型压缩 知识蒸馏 移动设备 扩散模型
📋 核心要点
- 大规模文本到图像扩散模型视觉质量不断提高,但模型规模的增长拉大了先进模型与设备端解决方案之间的差距。
- NanoFLUX的核心思想是通过蒸馏和模型压缩,在保证生成质量的前提下,显著降低模型大小,使其能够在移动设备上运行。
- 实验结果表明,NanoFLUX能够在移动设备上以约2.5秒的速度生成512x512的图像,验证了该方法在设备端部署的可行性。
📝 摘要(中文)
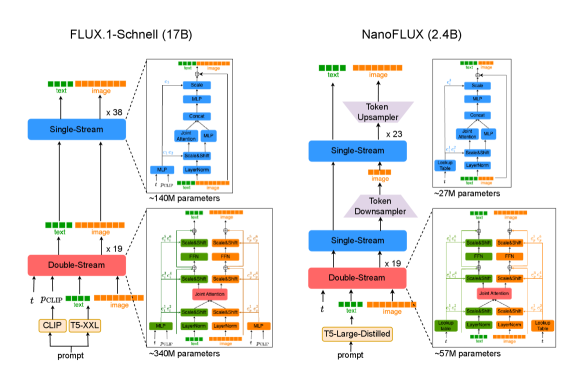
本文提出NanoFLUX,一个24亿参数的文本到图像Flow-Matching模型,通过从170亿参数的FLUX.1-Schnell模型中蒸馏得到,采用渐进式压缩流程以保持生成质量。主要贡献包括:(1) 一种模型压缩策略,通过剪枝扩散Transformer中的冗余组件,将其大小从120亿减少到20亿;(2) 一种基于ResNet的token下采样机制,允许中间块在较低分辨率的token上操作,从而降低延迟,同时在其他地方保持高分辨率处理;(3) 一种新颖的文本编码器蒸馏方法,利用采样过程中去噪器早期层的视觉信号。实验表明,NanoFLUX在移动设备上大约2.5秒内生成512x512的图像,证明了高质量的设备端文本到图像生成的可行性。
🔬 方法详解
问题定义:论文旨在解决大规模文本到图像生成模型难以在移动设备上部署的问题。现有方法计算量大,推理速度慢,无法满足移动设备对低延迟和低功耗的需求。
核心思路:论文的核心思路是通过模型压缩和知识蒸馏,将一个大型的文本到图像生成模型压缩成一个更小的模型,同时尽可能地保持其生成质量。通过剪枝冗余组件、token下采样和文本编码器蒸馏等技术,降低模型的计算复杂度和内存占用。
技术框架:NanoFLUX的整体框架包括以下几个主要阶段:1) 从大型FLUX.1-Schnell模型开始;2) 使用剪枝策略压缩扩散Transformer;3) 引入基于ResNet的token下采样机制;4) 使用视觉信号蒸馏文本编码器;5) 在移动设备上进行部署和推理。
关键创新:论文的关键创新点在于:1) 提出了一种针对扩散Transformer的剪枝策略,能够有效地减少模型大小;2) 引入了一种基于ResNet的token下采样机制,能够在降低计算量的同时保持生成质量;3) 提出了一种新颖的文本编码器蒸馏方法,利用去噪器早期层的视觉信号来指导文本编码器的学习。
关键设计:在模型压缩方面,论文采用了一种迭代剪枝策略,逐步移除扩散Transformer中的冗余连接。在token下采样方面,论文设计了一个基于ResNet的下采样模块,将高分辨率的token转换为低分辨率的token,从而降低后续计算的复杂度。在文本编码器蒸馏方面,论文使用去噪器早期层的特征作为视觉信号,指导文本编码器的学习,使其能够更好地理解文本描述并生成高质量的图像。
🖼️ 关键图片


📊 实验亮点
NanoFLUX在移动设备上实现了高质量的文本到图像生成,能够在约2.5秒内生成512x512的图像。相比于直接在移动设备上运行大型模型,NanoFLUX显著降低了推理时间和内存占用,同时保持了较高的生成质量。该结果证明了通过模型压缩和知识蒸馏,可以在移动设备上部署复杂的AI模型。
🎯 应用场景
NanoFLUX的应用场景包括移动端的图像生成应用、增强现实(AR)和虚拟现实(VR)应用、以及其他需要低延迟和低功耗的设备端应用。该研究的实际价值在于降低了高质量图像生成模型的部署门槛,使得更多用户能够在移动设备上体验到先进的AI技术。未来,该技术有望推动移动端图像生成应用的普及,并促进相关领域的发展。
📄 摘要(原文)
While large-scale text-to-image diffusion models continue to improve in visual quality, their increasing scale has widened the gap between state-of-the-art models and on-device solutions. To address this gap, we introduce NanoFLUX, a 2.4B text-to-image flow-matching model distilled from 17B FLUX.1-Schnell using a progressive compression pipeline designed to preserve generation quality. Our contributions include: (1) A model compression strategy driven by pruning redundant components in the diffusion transformer, reducing its size from 12B to 2B; (2) A ResNet-based token downsampling mechanism that reduces latency by allowing intermediate blocks to operate on lower-resolution tokens while preserving high-resolution processing elsewhere; (3) A novel text encoder distillation approach that leverages visual signals from early layers of the denoiser during sampling. Empirically, NanoFLUX generates 512 x 512 images in approximately 2.5 seconds on mobile devices, demonstrating the feasibility of high-quality on-device text-to-image generation.