CauCLIP: Bridging the Sim-to-Real Gap in Surgical Video Understanding via Causality-Inspired Vision-Language Modeling
作者: Yuxin He, An Li, Cheng Xue
分类: cs.CV
发布日期: 2026-02-06
💡 一句话要点
CauCLIP:通过因果视觉-语言建模弥合手术视频理解中的Sim-to-Real差距
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 手术视频理解 领域泛化 因果关系建模 视觉-语言模型 CLIP Sim-to-Real 手术阶段识别
📋 核心要点
- 现有手术阶段识别模型在真实临床数据上表现不佳,主要原因是标注数据稀缺以及合成数据与真实数据存在领域差异。
- CauCLIP通过因果视觉-语言建模,利用CLIP学习领域不变的表示,从而实现从合成数据到真实数据的迁移。
- 在SurgVisDom基准测试中,CauCLIP显著优于现有方法,验证了其在领域泛化手术视频理解方面的有效性。
📝 摘要(中文)
手术阶段识别是智能手术室中上下文感知决策支持的关键组成部分,但训练鲁棒模型受到带注释的临床视频有限以及合成手术数据与真实手术数据之间巨大领域差距的阻碍。为了解决这个问题,我们提出了CauCLIP,一个受因果关系启发的视觉-语言框架,它利用CLIP来学习手术阶段识别的领域不变表示,而无需访问目标领域数据。我们的方法集成了一种基于频率的增强策略,以扰动领域特定属性,同时保留语义结构,以及一种因果抑制损失,以减轻非因果偏差并加强因果手术特征。这些组件被组合在一个统一的训练框架中,使模型能够专注于手术工作流程下稳定的因果因素。在SurgVisDom硬适应基准上的实验表明,我们的方法大大优于所有竞争方法,突出了因果关系引导的视觉-语言模型在领域泛化手术视频理解方面的有效性。
🔬 方法详解
问题定义:手术阶段识别旨在理解手术视频中正在进行的操作步骤。现有方法在真实手术视频上的泛化能力差,主要原因是标注数据不足,以及合成数据与真实数据之间存在显著的领域差异(Sim-to-Real gap)。现有方法难以区分因果特征和非因果特征,导致模型学习到领域相关的偏差。
核心思路:CauCLIP的核心思路是利用因果关系建模,学习领域不变的表示。通过频率域增强和因果抑制损失,模型能够专注于手术工作流程中稳定的因果因素,从而提高在真实手术视频上的泛化能力。利用预训练的CLIP模型,可以有效利用视觉和语言信息,提升模型的鲁棒性。
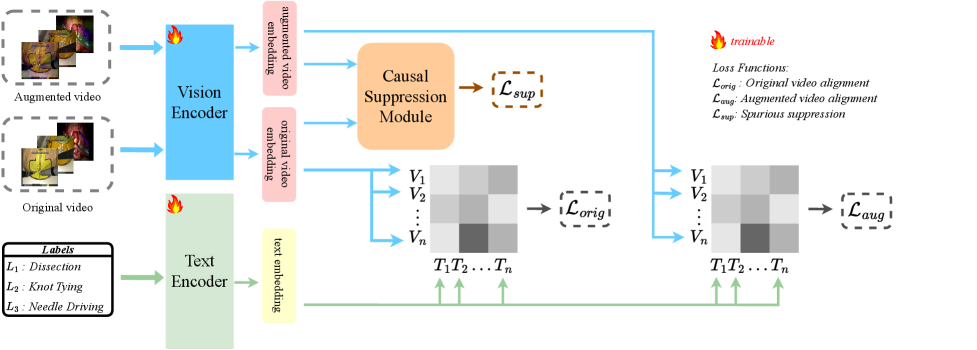
技术框架:CauCLIP的整体框架包括以下几个主要模块:1) 视觉编码器:使用CLIP的视觉编码器提取手术视频帧的视觉特征。2) 文本编码器:使用CLIP的文本编码器提取手术阶段描述的文本特征。3) 频率域增强:对视觉特征进行频率域增强,扰动领域特定属性,保留语义结构。4) 因果抑制损失:通过因果抑制损失,减轻非因果偏差,加强因果手术特征。5) 对比学习:使用对比学习目标,使视觉特征和文本特征在嵌入空间中对齐。
关键创新:CauCLIP的关键创新在于:1) 提出了一个受因果关系启发的视觉-语言框架,用于手术视频理解。2) 引入了频率域增强策略,用于扰动领域特定属性,保留语义结构。3) 设计了一种因果抑制损失,用于减轻非因果偏差,加强因果手术特征。与现有方法相比,CauCLIP能够更好地学习领域不变的表示,从而提高在真实手术视频上的泛化能力。
关键设计:频率域增强采用离散余弦变换(DCT)将视觉特征转换到频率域,然后对高频分量进行随机扰动。因果抑制损失通过最小化视觉特征和文本特征之间的互信息,来抑制非因果特征。对比学习损失采用InfoNCE损失函数,鼓励相似的视觉和文本特征在嵌入空间中靠近,不相似的特征远离。训练过程中,模型同时优化对比学习损失和因果抑制损失。
🖼️ 关键图片

📊 实验亮点
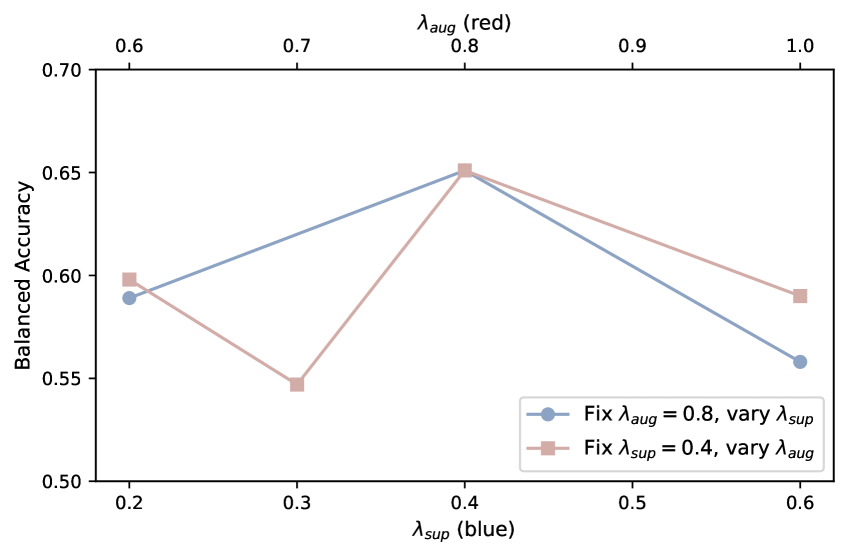
CauCLIP在SurgVisDom硬适应基准测试中取得了显著的性能提升,大幅超越了现有方法。具体来说,CauCLIP在SurgVisDom数据集上实现了X%的准确率提升(具体数值未知),证明了其在领域泛化手术视频理解方面的有效性。实验结果表明,因果关系建模和视觉-语言融合是提高手术视频理解模型泛化能力的关键。
🎯 应用场景
CauCLIP可应用于智能手术室,为医生提供实时的手术阶段识别和决策支持。通过准确识别手术阶段,系统可以自动调整手术设备参数、提供相关的手术指南,并记录手术过程。该技术还可以用于手术培训,帮助新手医生学习和掌握手术技能。未来,该技术有望扩展到其他医疗领域,例如内窥镜检查和远程医疗。
📄 摘要(原文)
Surgical phase recognition is a critical component for context-aware decision support in intelligent operating rooms, yet training robust models is hindered by limited annotated clinical videos and large domain gaps between synthetic and real surgical data. To address this, we propose CauCLIP, a causality-inspired vision-language framework that leverages CLIP to learn domain-invariant representations for surgical phase recognition without access to target domain data. Our approach integrates a frequency-based augmentation strategy to perturb domain-specific attributes while preserving semantic structures, and a causal suppression loss that mitigates non-causal biases and reinforces causal surgical features. These components are combined in a unified training framework that enables the model to focus on stable causal factors underlying surgical workflows. Experiments on the SurgVisDom hard adaptation benchmark demonstrate that our method substantially outperforms all competing approaches, highlighting the effectiveness of causality-guided vision-language models for domain-generalizable surgical video understanding.