SPARC: Separating Perception And Reasoning Circuits for Test-time Scaling of VLMs
作者: Niccolo Avogaro, Nayanika Debnath, Li Mi, Thomas Frick, Junling Wang, Zexue He, Hang Hua, Konrad Schindler, Mattia Rigotti
分类: cs.CV, cs.AI, cs.CL
发布日期: 2026-02-06 (更新: 2026-02-10)
💡 一句话要点
SPARC:分离视觉语言模型的感知与推理电路,实现测试时动态扩展。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 感知推理分离 测试时扩展 视觉问答 模块化框架
📋 核心要点
- 现有视觉语言模型在测试时动态扩展token预算时,感知和推理相互纠缠,导致性能不稳定。
- SPARC通过显式分离视觉感知和推理,构建模块化框架,实现更高效的测试时扩展和优化。
- 实验表明,SPARC在多个视觉推理基准上超越了现有方法,尤其是在token预算受限的情况下。
📝 摘要(中文)
尽管视觉语言模型(VLMs)取得了显著进展,但测试时动态扩展(即在推理过程中根据需要动态增加token预算)仍然存在问题。这是因为关于图像的非结构化思维链将感知和推理纠缠在一起,导致冗长且无序的上下文,微小的感知错误可能导致完全错误的答案。此外,为了获得良好的性能,需要昂贵的强化学习和手工设计的奖励。本文提出了SPARC(分离感知和推理电路),这是一个模块化框架,显式地将视觉感知与推理分离。受到大脑中顺序感觉-认知处理的启发,SPARC实现了一个两阶段流程,模型首先执行显式的视觉搜索以定位与问题相关的区域,然后基于这些区域进行推理以产生最终答案。这种分离支持独立的测试时扩展和非对称计算分配(例如,在分布偏移下优先考虑感知处理),支持选择性优化(例如,当感知阶段是端到端性能的瓶颈时,单独改进感知阶段),并通过以较低的图像分辨率运行全局搜索并将高分辨率处理仅分配给选定的区域来适应压缩的上下文,从而减少总的视觉token数量和计算量。在具有挑战性的视觉推理基准测试中,SPARC优于单体基线和强大的视觉 grounding 方法。例如,SPARC将Qwen3VL-4B在$V^*$ VQA基准测试上的准确率提高了6.7个百分点,并且在具有挑战性的OOD任务上超过了“thinking with images” 4.6个百分点,尽管所需的token预算降低了200倍。
🔬 方法详解
问题定义:现有视觉语言模型在测试时动态扩展token预算时,由于感知和推理过程的紧密耦合,容易受到感知错误的影响,导致推理结果偏差。同时,为了提升性能,通常需要耗费大量资源进行强化学习和奖励函数设计,效率较低。
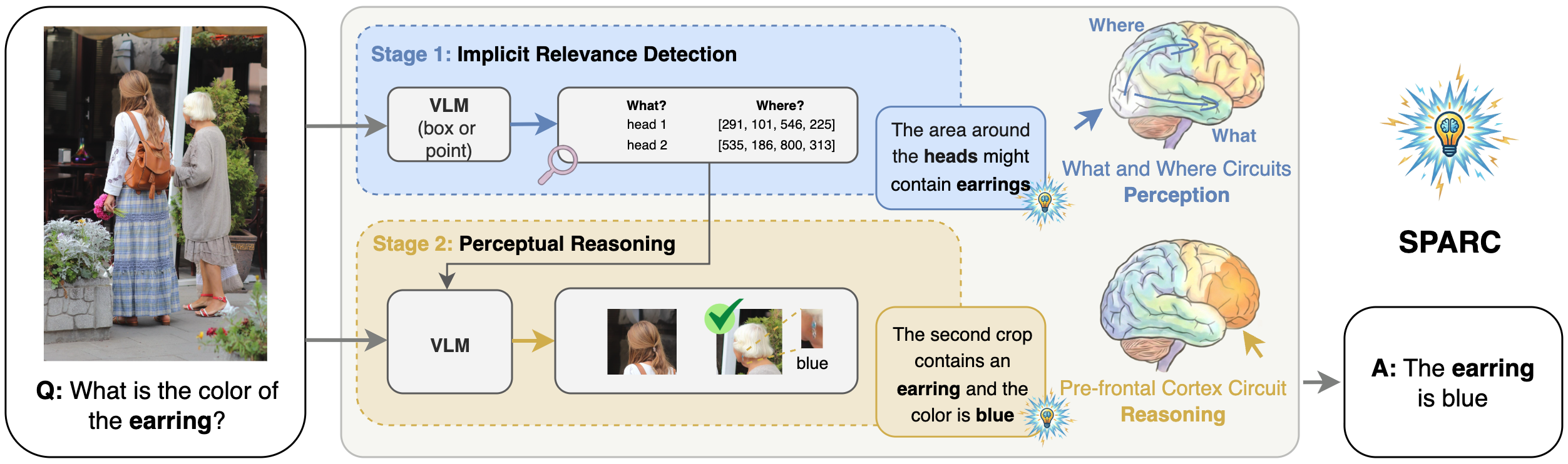
核心思路:SPARC的核心思想是将视觉感知和推理过程解耦,模仿大脑中感觉-认知处理的顺序性。通过显式地视觉搜索定位关键区域,再基于这些区域进行推理,从而降低感知错误对推理的影响,并支持更灵活的计算资源分配。
技术框架:SPARC采用两阶段流程:首先,视觉感知模块执行显式视觉搜索,定位与问题相关的图像区域。然后,推理模块基于这些区域进行推理,生成最终答案。这种分离允许独立地扩展感知和推理模块的计算资源,并支持选择性优化。
关键创新:SPARC的关键创新在于显式地将视觉感知和推理过程分离,构建模块化框架。这种分离使得模型能够更有效地利用计算资源,并降低感知错误对推理的影响。此外,SPARC还支持选择性优化,可以针对性地改进感知或推理模块。
关键设计:SPARC通过两阶段流程实现感知和推理的分离。在视觉感知阶段,模型以较低分辨率进行全局搜索,然后仅对选定的区域进行高分辨率处理,从而减少总的视觉token数量和计算量。具体的网络结构和损失函数细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
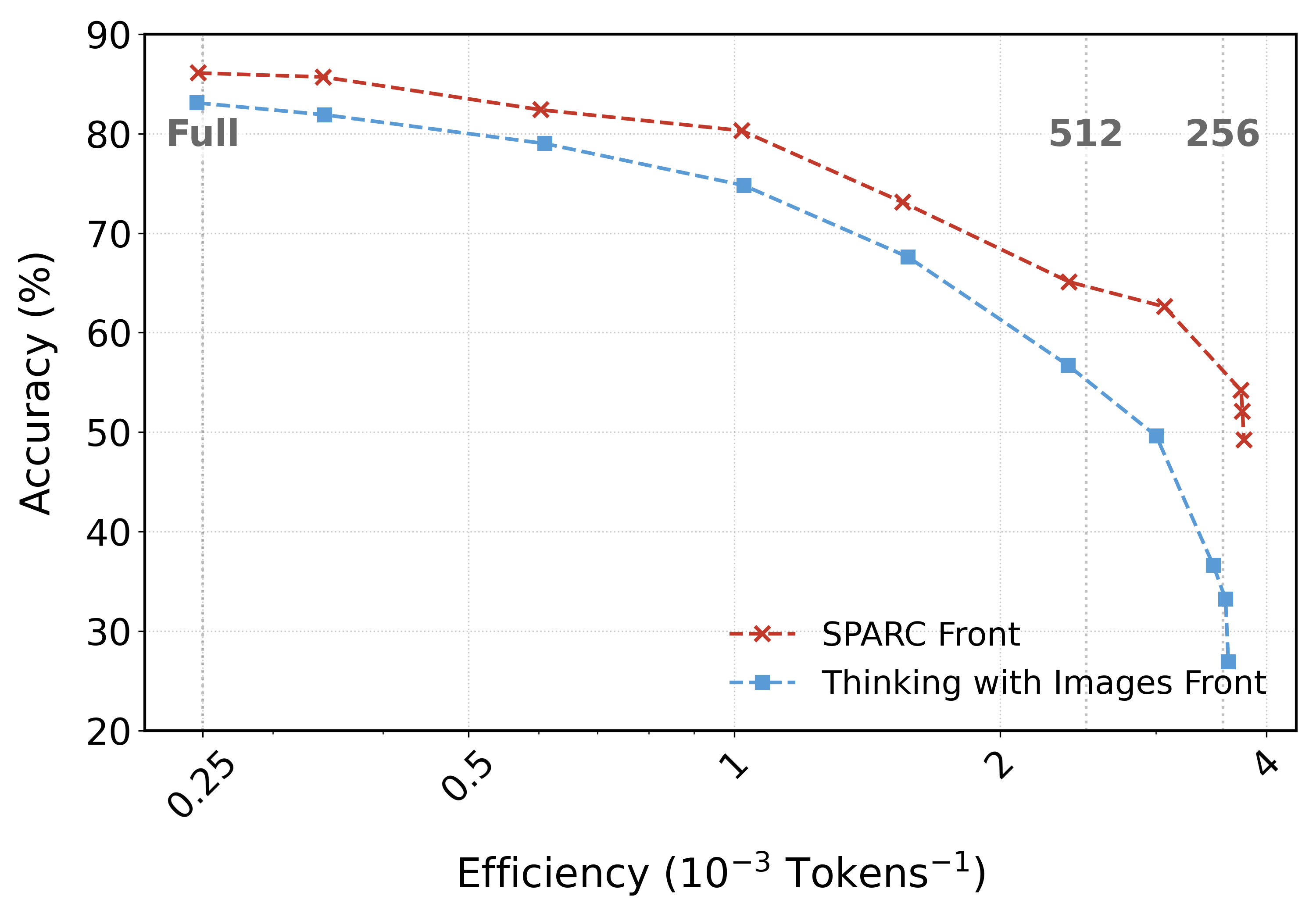
SPARC在$V^*$ VQA基准测试中,相较于Qwen3VL-4B,准确率提升了6.7个百分点。在具有挑战性的OOD任务上,SPARC超越了“thinking with images” 4.6个百分点,同时token预算降低了200倍。这些结果表明SPARC在视觉推理任务中具有显著的优势。
🎯 应用场景
SPARC框架可应用于各种视觉问答、图像理解和机器人导航等领域。通过分离感知和推理,可以提升模型在资源受限环境下的性能,并支持更灵活的计算资源分配。该研究对于开发更高效、更鲁棒的视觉语言模型具有重要意义。
📄 摘要(原文)
Despite recent successes, test-time scaling - i.e., dynamically expanding the token budget during inference as needed - remains brittle for vision-language models (VLMs): unstructured chains-of-thought about images entangle perception and reasoning, leading to long, disorganized contexts where small perceptual mistakes may cascade into completely wrong answers. Moreover, expensive reinforcement learning with hand-crafted rewards is required to achieve good performance. Here, we introduce SPARC (Separating Perception And Reasoning Circuits), a modular framework that explicitly decouples visual perception from reasoning. Inspired by sequential sensory-to-cognitive processing in the brain, SPARC implements a two-stage pipeline where the model first performs explicit visual search to localize question-relevant regions, then conditions its reasoning on those regions to produce the final answer. This separation enables independent test-time scaling with asymmetric compute allocation (e.g., prioritizing perceptual processing under distribution shift), supports selective optimization (e.g., improving the perceptual stage alone when it is the bottleneck for end-to-end performance), and accommodates compressed contexts by running global search at lower image resolutions and allocating high-resolution processing only to selected regions, thereby reducing total visual tokens count and compute. Across challenging visual reasoning benchmarks, SPARC outperforms monolithic baselines and strong visual-grounding approaches. For instance, SPARC improves the accuracy of Qwen3VL-4B on the $V^*$ VQA benchmark by 6.7 percentage points, and it surpasses "thinking with images" by 4.6 points on a challenging OOD task despite requiring a 200$\times$ lower token budget.