DriveWorld-VLA: Unified Latent-Space World Modeling with Vision-Language-Action for Autonomous Driving
作者: Feiyang jia, Lin Liu, Ziying Song, Caiyan Jia, Hangjun Ye, Xiaoshuai Hao, Long Chen
分类: cs.CV, cs.RO
发布日期: 2026-02-06
备注: 20 pages, 7 tables, 12 figures
🔗 代码/项目: GITHUB
💡 一句话要点
DriveWorld-VLA:融合视觉-语言-动作的统一隐空间自动驾驶世界模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 世界模型 视觉-语言-动作 端到端学习 潜在空间 场景理解 动作规划
📋 核心要点
- 现有端到端自动驾驶方法在统一场景演化和动作规划方面存在不足,未能有效共享潜在状态,限制了视觉想象对决策的影响。
- DriveWorld-VLA通过在潜在空间中紧密集成视觉-语言-动作和世界模型,实现了世界建模和规划的统一,提升了决策效果。
- 实验结果表明,DriveWorld-VLA在多个自动驾驶数据集上取得了最先进的性能,显著降低了碰撞率,提升了驾驶安全性。
📝 摘要(中文)
端到端(E2E)自动驾驶最近在统一视觉-语言-动作(VLA)与世界模型方面引起了越来越多的兴趣,以增强决策能力和前瞻性想象力。然而,由于潜在状态共享不足,现有方法未能有效地在单个架构中统一未来场景演化和动作规划,限制了视觉想象对动作决策的影响。为了解决这个限制,我们提出了DriveWorld-VLA,这是一个新颖的框架,通过在表示层紧密集成VLA和世界模型,在潜在空间中统一世界建模和规划,这使得VLA规划器能够直接受益于整体场景演化建模,并减少对密集标注监督的依赖。此外,DriveWorld-VLA将世界模型的潜在状态作为VLA规划器的核心决策状态,从而方便规划器评估候选动作如何影响未来场景演化。通过完全在潜在空间中进行世界建模,DriveWorld-VLA支持可控的、动作条件下的特征级想象,避免了昂贵的像素级展开。广泛的开环和闭环评估证明了DriveWorld-VLA的有效性,在NAVSIMv1上实现了91.3 PDMS,在NAVSIMv2上实现了86.8 EPDMS,在nuScenes上实现了0.16的3秒平均碰撞率,达到了最先进的性能。
🔬 方法详解
问题定义:现有端到端自动驾驶方法难以在统一的架构中整合未来场景的演化和动作规划,主要痛点在于视觉表征和动作规划之间的信息共享不足,导致模型难以有效地利用视觉信息进行决策,并且依赖大量的标注数据。
核心思路:DriveWorld-VLA的核心思路是在一个共享的潜在空间中进行世界建模和动作规划,通过将视觉、语言和动作信息融合到统一的表征中,使得模型能够更好地理解当前场景,预测未来场景的演化,并做出合理的动作决策。这种设计能够减少对密集标注数据的依赖,并提升模型的泛化能力。
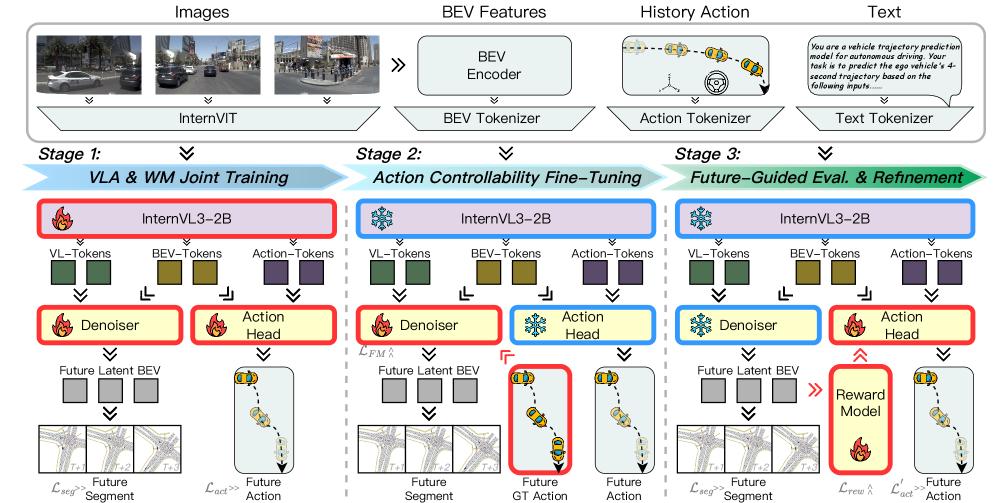
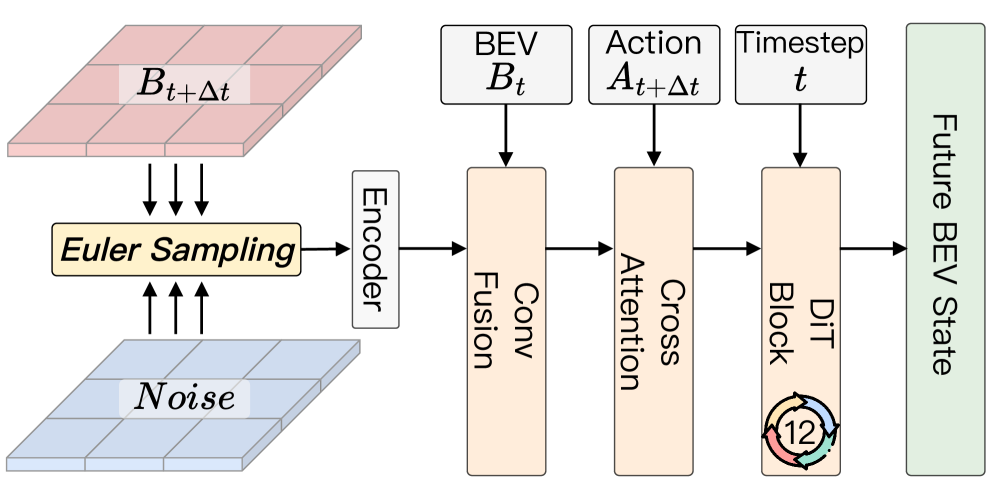
技术框架:DriveWorld-VLA框架主要包含以下几个模块:视觉编码器,用于提取图像特征;语言编码器,用于处理文本指令;世界模型,用于在潜在空间中建模场景演化;VLA规划器,用于根据世界模型的预测结果进行动作规划。整体流程是:首先,视觉编码器和语言编码器将输入信息编码到潜在空间中;然后,世界模型根据当前状态和动作预测未来状态;最后,VLA规划器根据世界模型的预测结果选择最优动作。
关键创新:DriveWorld-VLA的关键创新在于将世界建模和动作规划统一在潜在空间中进行,通过共享潜在状态,实现了视觉信息和动作规划的紧密集成。与现有方法相比,DriveWorld-VLA避免了昂贵的像素级展开,降低了计算复杂度,并提升了模型的泛化能力。此外,将世界模型的潜在状态作为VLA规划器的核心决策状态,使得规划器能够更好地评估候选动作对未来场景的影响。
关键设计:DriveWorld-VLA的关键设计包括:使用变分自编码器(VAE)进行世界建模,学习场景的潜在表示;设计了特定的损失函数,鼓励世界模型学习到具有预测能力的潜在表示;采用Transformer网络作为VLA规划器,学习动作序列的生成策略。具体的参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
DriveWorld-VLA在NAVSIMv1上实现了91.3 PDMS,在NAVSIMv2上实现了86.8 EPDMS,在nuScenes上实现了0.16的3秒平均碰撞率,达到了最先进的性能。这些结果表明,DriveWorld-VLA能够有效地提升自动驾驶系统的决策能力和安全性,显著降低碰撞率。
🎯 应用场景
DriveWorld-VLA具有广泛的应用前景,可应用于自动驾驶、机器人导航等领域。该研究能够提升自动驾驶系统的决策能力和安全性,减少对人工标注数据的依赖,加速自动驾驶技术的落地。未来,该方法可以进一步扩展到更复杂的场景,例如城市交通、无人配送等。
📄 摘要(原文)
End-to-end (E2E) autonomous driving has recently attracted increasing interest in unifying Vision-Language-Action (VLA) with World Models to enhance decision-making and forward-looking imagination. However, existing methods fail to effectively unify future scene evolution and action planning within a single architecture due to inadequate sharing of latent states, limiting the impact of visual imagination on action decisions. To address this limitation, we propose DriveWorld-VLA, a novel framework that unifies world modeling and planning within a latent space by tightly integrating VLA and world models at the representation level, which enables the VLA planner to benefit directly from holistic scene-evolution modeling and reducing reliance on dense annotated supervision. Additionally, DriveWorld-VLA incorporates the latent states of the world model as core decision-making states for the VLA planner, facilitating the planner to assess how candidate actions impact future scene evolution. By conducting world modeling entirely in the latent space, DriveWorld-VLA supports controllable, action-conditioned imagination at the feature level, avoiding expensive pixel-level rollouts. Extensive open-loop and closed-loop evaluations demonstrate the effectiveness of DriveWorld-VLA, which achieves state-of-the-art performance with 91.3 PDMS on NAVSIMv1, 86.8 EPDMS on NAVSIMv2, and 0.16 3-second average collision rate on nuScenes. Code and models will be released in https://github.com/liulin815/DriveWorld-VLA.git.