Bridging the Indoor-Outdoor Gap: Vision-Centric Instruction-Guided Embodied Navigation for the Last Meters
作者: Yuxiang Zhao, Yirong Yang, Yanqing Zhu, Yanfen Shen, Chiyu Wang, Zhining Gu, Pei Shi, Wei Guo, Mu Xu
分类: cs.CV, cs.RO
发布日期: 2026-02-06
💡 一句话要点
提出视觉中心指令引导的室内外无先验知识具身导航方法
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction)
关键词: 具身导航 视觉导航 指令引导 室内外导航 无先验知识
📋 核心要点
- 现有具身导航方法依赖精确坐标,且难以实现室内外环境的无缝过渡,限制了实际应用。
- 提出一种视觉中心的具身导航框架,利用图像提示驱动决策,无需精确的外部先验知识。
- 构建了首个开源数据集,包含轨迹条件视频合成,实验表明该方法优于现有基线。
📝 摘要(中文)
具身导航在末端配送等现实应用中具有巨大潜力。然而,现有方法大多局限于室内或室外环境,并严重依赖精确坐标系等强假设。虽然目前的室外方法可以将智能体引导至目标附近,但无法实现通过特定建筑物入口的精细化进入,这严重限制了其在需要无缝室内外过渡的实际部署场景中的效用。为了弥合这一差距,我们引入了一项新任务:无先验知识的室外到室内指令驱动具身导航。该任务明确消除了对精确外部先验的依赖,要求智能体仅根据以自我为中心的视觉观察,并在指令的引导下进行导航。为了解决这个任务,我们提出了一个视觉中心的具身导航框架,该框架利用基于图像的提示来驱动决策。此外,我们还提出了该任务的第一个开源数据集,该数据集具有将轨迹条件视频合成集成到数据生成过程中的流水线。通过大量的实验,我们证明了我们提出的方法在成功率和路径效率等关键指标上始终优于最先进的基线。
🔬 方法详解
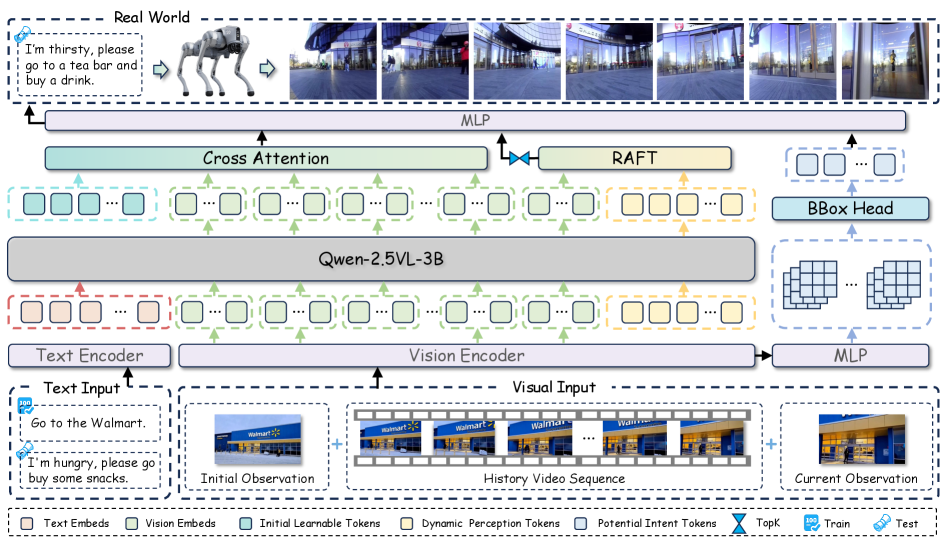
问题定义:现有具身导航方法通常依赖于精确的坐标系统或地图信息,这在实际部署中往往难以满足。尤其是在室内外过渡的场景下,室外导航只能将智能体引导到目标建筑附近,而无法精确地引导其进入特定的入口,这限制了其在末端配送等场景中的应用。因此,需要一种无需先验知识,仅依靠视觉信息和指令即可完成室内外导航的方法。
核心思路:论文的核心思路是利用视觉信息作为主要的导航依据,通过图像提示来引导智能体的决策。这种方法避免了对精确坐标和地图的依赖,更符合实际应用场景的需求。同时,结合指令信息,可以实现更精确和高效的导航。
技术框架:该框架主要包含以下几个模块:1) 视觉感知模块:负责从智能体的视觉输入中提取特征。2) 指令理解模块:负责解析导航指令,并将其转化为可供智能体理解的形式。3) 决策模块:根据视觉特征和指令信息,生成智能体的动作指令。4) 运动控制模块:负责执行智能体的动作指令,使其在环境中移动。此外,论文还提出了一个轨迹条件视频合成的数据生成流程,用于生成训练数据。
关键创新:该论文的关键创新在于提出了一个视觉中心的具身导航框架,该框架完全依赖于视觉信息和指令进行导航,无需任何先验知识。此外,论文还提出了一个轨迹条件视频合成的数据生成流程,可以有效地生成训练数据。
关键设计:论文中使用了图像提示来驱动决策,具体实现方式未知。数据集的构建使用了轨迹条件视频合成,具体合成方法未知。损失函数和网络结构等技术细节在论文中没有详细描述,属于未知信息。
🖼️ 关键图片


📊 实验亮点
论文提出的方法在室内外导航任务中取得了显著的性能提升,成功率和路径效率均优于现有基线方法。具体性能数据和对比基线在摘要中提及,但未给出具体数值,属于未知信息。该方法无需先验知识,更具实用性。
🎯 应用场景
该研究成果可应用于末端配送、机器人引导、安防巡逻等领域。例如,在末端配送中,机器人可以根据视觉信息和指令,自主地从室外导航到室内,并将包裹送到指定地点。在安防巡逻中,机器人可以根据视觉信息和指令,自主地在室内外环境中巡逻,并及时发现异常情况。该研究有望推动具身智能在现实世界中的广泛应用。
📄 摘要(原文)
Embodied navigation holds significant promise for real-world applications such as last-mile delivery. However, most existing approaches are confined to either indoor or outdoor environments and rely heavily on strong assumptions, such as access to precise coordinate systems. While current outdoor methods can guide agents to the vicinity of a target using coarse-grained localization, they fail to enable fine-grained entry through specific building entrances, critically limiting their utility in practical deployment scenarios that require seamless outdoor-to-indoor transitions. To bridge this gap, we introduce a novel task: out-to-in prior-free instruction-driven embodied navigation. This formulation explicitly eliminates reliance on accurate external priors, requiring agents to navigate solely based on egocentric visual observations guided by instructions. To tackle this task, we propose a vision-centric embodied navigation framework that leverages image-based prompts to drive decision-making. Additionally, we present the first open-source dataset for this task, featuring a pipeline that integrates trajectory-conditioned video synthesis into the data generation process. Through extensive experiments, we demonstrate that our proposed method consistently outperforms state-of-the-art baselines across key metrics including success rate and path efficiency.