Revisiting Salient Object Detection from an Observer-Centric Perspective
作者: Fuxi Zhang, Yifan Wang, Hengrun Zhao, Zhuohan Sun, Changxing Xia, Lijun Wang, Huchuan Lu, Yangrui Shao, Chen Yang, Long Teng
分类: cs.CV, cs.AI
发布日期: 2026-02-06
🔗 代码/项目: GITHUB
💡 一句话要点
提出观察者中心显著性目标检测(OC-SOD),解决传统方法主观性不足问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 显著性目标检测 观察者中心 主观感知 多模态学习 大型语言模型
📋 核心要点
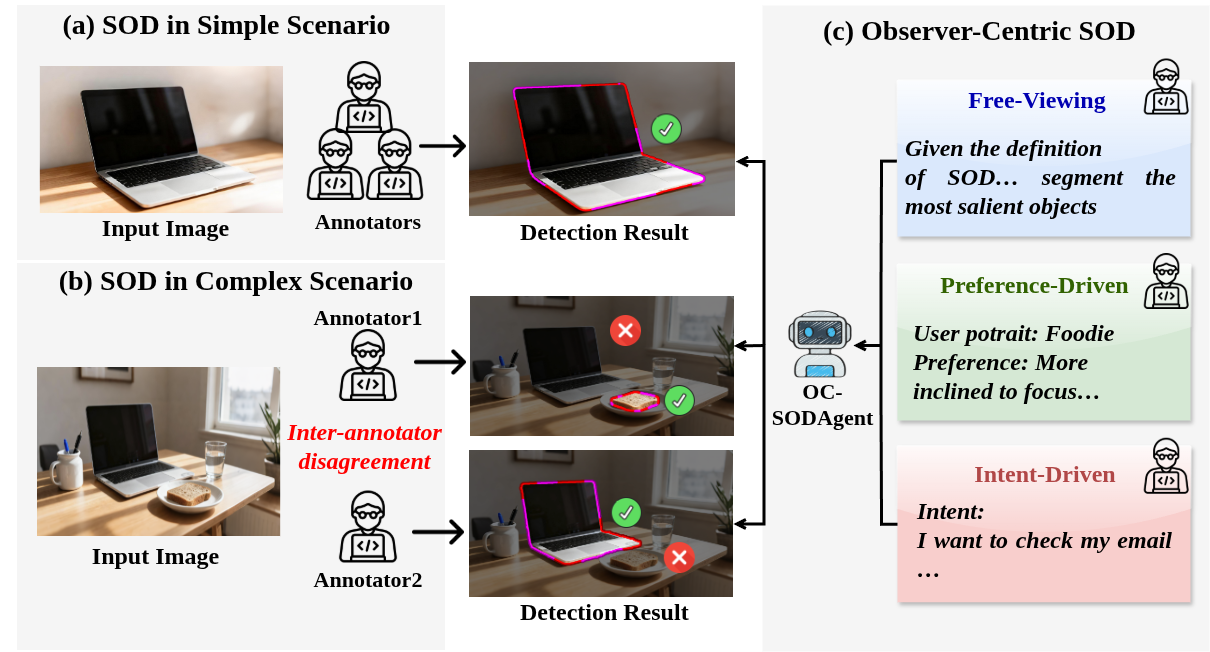
- 现有显著性目标检测方法忽略了人类感知的主观性,使用单一标准答案导致模型泛化性不足。
- 提出观察者中心显著性目标检测(OC-SOD),通过考虑观察者的偏好和意图来预测显著区域。
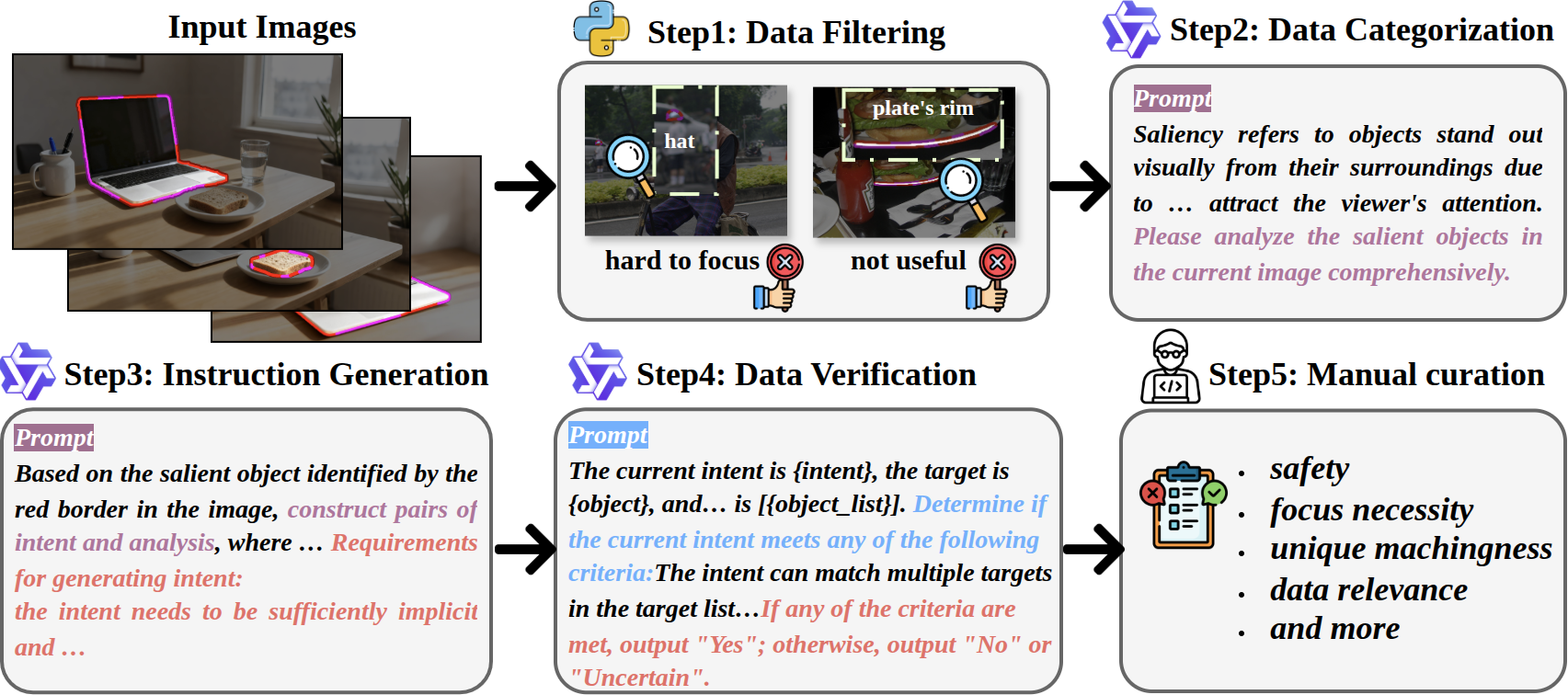
- 构建了包含33k图像和152k文本提示的OC-SODBench数据集,并设计了OC-SODAgent作为基线模型,实验验证了有效性。
📝 摘要(中文)
本文重新审视了显著性目标检测问题,认为其本质上是主观的,因为具有不同先验知识的观察者可能将不同的对象感知为显著的。然而,现有方法主要将其表述为客观预测任务,对每张图像使用单一的groundtruth分割图,这使得问题变得不确定且从根本上是不适定的。为了解决这个问题,我们提出了观察者中心显著性目标检测(OC-SOD),其中显著区域的预测不仅考虑视觉线索,还考虑观察者特定的因素,如他们的偏好或意图。因此,这种公式捕捉了人类感知的内在模糊性和多样性,从而实现个性化和上下文感知的显著性预测。通过利用多模态大型语言模型,我们开发了一个高效的数据标注流程,并构建了第一个OC-SOD数据集,名为OC-SODBench,包含33k训练、验证和测试图像,以及152k文本提示和对象对。基于这个新数据集,我们进一步设计了OC-SODAgent,一个类人“感知-反思-调整”过程的agentic基线,用于执行OC-SOD。在我们提出的OC-SODBench上进行的大量实验证明了我们贡献的有效性。通过这种以观察者为中心的视角,我们旨在弥合人类感知和计算建模之间的差距,从而提供对什么使对象真正“显著”的更现实和灵活的理解。
🔬 方法详解
问题定义:现有显著性目标检测方法将问题视为客观预测任务,使用单一的groundtruth分割图,忽略了人类感知的主观性和多样性。不同观察者可能因为不同的先验知识、偏好或意图而对同一图像中的不同对象产生不同的显著性感知。这种客观化的处理方式使得问题本身变得不适定,限制了模型的泛化能力和实际应用。
核心思路:本文的核心思路是将显著性目标检测问题从客观预测转变为主观预测,即考虑观察者的个性化因素。通过引入观察者的偏好或意图,模型可以预测出更符合特定观察者感知的显著区域。这种以观察者为中心的视角能够更好地捕捉人类感知的内在模糊性和多样性,从而提高显著性目标检测的准确性和实用性。
技术框架:OC-SOD的整体框架包含数据收集与标注、数据集构建和Agent模型设计三个主要部分。首先,利用多模态大型语言模型辅助数据标注,构建包含图像、文本提示和对象对的OC-SODBench数据集。然后,设计OC-SODAgent,该Agent模拟人类的“感知-反思-调整”过程,通过分析视觉线索和观察者提供的文本提示,逐步调整对显著区域的预测。整个框架旨在实现个性化和上下文感知的显著性预测。
关键创新:最重要的技术创新点在于将观察者因素纳入显著性目标检测的考量范围。传统方法只关注图像本身的视觉特征,而OC-SOD则进一步考虑了观察者的主观偏好和意图。这种转变使得模型能够更好地理解人类的感知过程,从而做出更符合人类直觉的预测。此外,OC-SODAgent的“感知-反思-调整”过程也模拟了人类认知过程,提高了模型的可解释性和鲁棒性。
关键设计:OC-SODAgent的关键设计在于如何有效地融合视觉信息和文本提示。具体来说,模型首先通过视觉编码器提取图像的视觉特征,然后通过文本编码器提取文本提示的语义特征。接下来,模型使用注意力机制将视觉特征和语义特征进行融合,从而得到上下文感知的特征表示。最后,模型使用解码器将特征表示转换为显著性分割图。损失函数的设计也至关重要,需要同时考虑分割的准确性和与观察者意图的一致性。具体的网络结构和参数设置在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
论文构建了首个观察者中心显著性目标检测数据集OC-SODBench,包含33k图像和152k文本提示。提出的OC-SODAgent在OC-SODBench上取得了显著效果,验证了以观察者为中心的显著性目标检测的有效性。实验结果表明,OC-SODAgent能够更好地捕捉人类感知的内在模糊性和多样性,从而提高显著性目标检测的准确性和实用性。
🎯 应用场景
OC-SOD在个性化推荐、图像编辑、人机交互等领域具有广泛的应用前景。例如,在个性化推荐中,可以根据用户的兴趣偏好推荐更符合其需求的商品或内容。在图像编辑中,可以根据用户的编辑意图自动选择需要编辑的区域。在人机交互中,可以根据用户的视线焦点和交互指令,更准确地理解用户的意图。
📄 摘要(原文)
Salient object detection is inherently a subjective problem, as observers with different priors may perceive different objects as salient. However, existing methods predominantly formulate it as an objective prediction task with a single groundtruth segmentation map for each image, which renders the problem under-determined and fundamentally ill-posed. To address this issue, we propose Observer-Centric Salient Object Detection (OC-SOD), where salient regions are predicted by considering not only the visual cues but also the observer-specific factors such as their preferences or intents. As a result, this formulation captures the intrinsic ambiguity and diversity of human perception, enabling personalized and context-aware saliency prediction. By leveraging multi-modal large language models, we develop an efficient data annotation pipeline and construct the first OC-SOD dataset named OC-SODBench, comprising 33k training, validation and test images with 152k textual prompts and object pairs. Built upon this new dataset, we further design OC-SODAgent, an agentic baseline which performs OC-SOD via a human-like "Perceive-Reflect-Adjust" process. Extensive experiments on our proposed OC-SODBench have justified the effectiveness of our contribution. Through this observer-centric perspective, we aim to bridge the gap between human perception and computational modeling, offering a more realistic and flexible understanding of what makes an object truly "salient." Code and dataset are publicly available at: https://github.com/Dustzx/OC_SOD