Unsupervised MR-US Multimodal Image Registration with Multilevel Correlation Pyramidal Optimization
作者: Jiazheng Wang, Zeyu Liu, Min Liu, Xiang Chen, Xinyao Yu, Yaonan Wang, Hang Zhang
分类: cs.CV
发布日期: 2026-02-06 (更新: 2026-02-16)
备注: first-place method of ReMIND2Reg Learn2Reg MICCAI 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于多层相关金字塔优化的无监督MR-US多模态图像配准方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态图像配准 无监督学习 医学图像处理 手术导航 相关金字塔
📋 核心要点
- 多模态医学图像配准面临模态差异和术中形变的挑战,传统方法难以有效应对。
- 提出多层相关金字塔优化(MCPO)方法,通过特征提取和多尺度融合优化位移场。
- 在ReMIND2Reg和Resect数据集上验证,ReMIND2Reg取得第一,Resect数据集平均TRE为1.798mm。
📝 摘要(中文)
基于多模态图像配准的手术导航在术中为外科医生提供目标区域与关键解剖结构相对位置的引导方面发挥着重要作用。然而,由于多模态图像之间的差异以及术中组织移位和切除引起的图像形变,术前和术中多模态图像的有效配准面临着重大挑战。为了解决Learn2Reg 2025中的多模态图像配准挑战,本文设计了一种基于多层相关金字塔优化(MCPO)的无监督多模态医学图像配准方法。首先,基于模态独立的邻域描述符提取每种模态的特征,并将多模态图像映射到特征空间。其次,设计了一种多层金字塔融合优化机制,通过密集相关性分析和权重平衡的耦合凸优化,实现不同尺度输入特征的位移场的全局优化和局部细节补充。我们的方法专注于Learn2Reg 2025中的ReMIND2Reg任务。结果表明,我们的方法在ReMIND2Reg的验证阶段和测试阶段均取得了第一名。MCPO还在Resect数据集上进行了验证,实现了1.798 mm的平均TRE。这证明了我们的方法在术前到术中图像配准中的广泛适用性。
🔬 方法详解
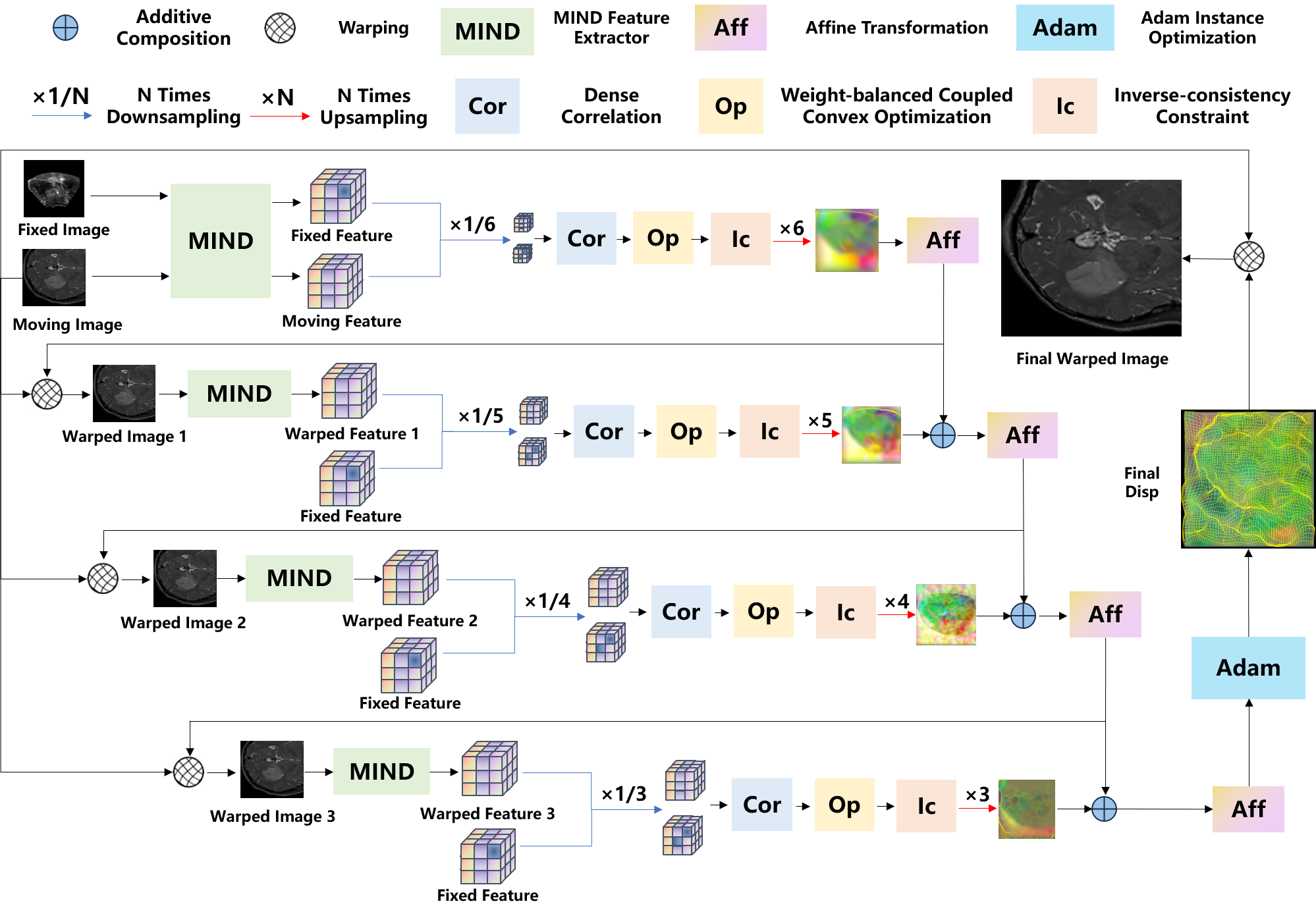
问题定义:论文旨在解决术前MR图像与术中US图像配准问题,该问题由于模态差异大、术中组织形变严重而极具挑战。现有方法难以同时兼顾全局配准精度和局部细节的准确性,容易陷入局部最优解。
核心思路:论文的核心思路是利用多层金字塔结构,在不同尺度上进行特征提取和相关性分析,从而实现全局和局部的优化平衡。通过模态独立的特征描述符,将不同模态的图像映射到统一的特征空间,减少模态差异的影响。
技术框架:整体框架包含特征提取、多层金字塔构建、相关性分析和位移场优化四个主要阶段。首先,使用模态独立的邻域描述符提取MR和US图像的特征。然后,构建多层金字塔,将图像和特征分解为不同尺度。接着,在每一层金字塔上进行密集相关性分析,计算不同模态特征之间的相似度。最后,通过权重平衡的耦合凸优化方法,融合不同尺度的相关性信息,优化位移场。
关键创新:最重要的技术创新点在于多层相关金字塔优化机制。该机制通过在不同尺度上进行相关性分析和优化,能够有效地捕捉全局结构和局部细节,避免陷入局部最优解。与传统方法相比,该方法能够更好地处理模态差异和术中形变,提高配准精度。
关键设计:论文采用模态独立的邻域描述符作为特征提取器,以减少模态差异的影响。多层金字塔的层数和尺度因子需要根据具体数据集进行调整。权重平衡的耦合凸优化方法通过调整不同尺度相关性信息的权重,实现全局和局部的平衡。损失函数的设计也至关重要,需要综合考虑配准精度和位移场的平滑性。
🖼️ 关键图片


📊 实验亮点
该方法在Learn2Reg 2025 ReMIND2Reg挑战赛的验证阶段和测试阶段均取得了第一名,证明了其优越的性能。在Resect数据集上的实验结果表明,该方法实现了1.798 mm的平均TRE,显著优于其他现有方法,验证了其在术前到术中图像配准中的广泛适用性。
🎯 应用场景
该研究成果可应用于基于MR-US融合的手术导航系统,为外科医生提供术中实时的解剖结构引导,提高手术精度和安全性。该方法还可扩展到其他多模态医学图像配准任务,例如CT-MRI配准、PET-CT配准等,具有广泛的应用前景。未来,该技术有望与机器人手术系统结合,实现更精确的自动化手术。
📄 摘要(原文)
Surgical navigation based on multimodal image registration has played a significant role in providing intraoperative guidance to surgeons by showing the relative position of the target area to critical anatomical structures during surgery. However, due to the differences between multimodal images and intraoperative image deformation caused by tissue displacement and removal during the surgery, effective registration of preoperative and intraoperative multimodal images faces significant challenges. To address the multimodal image registration challenges in Learn2Reg 2025, an unsupervised multimodal medical image registration method based on Multilevel Correlation Pyramidal Optimization (MCPO) is designed to solve these problems. First, the features of each modality are extracted based on the modality independent neighborhood descriptor, and the multimodal images is mapped to the feature space. Second, a multilevel pyramidal fusion optimization mechanism is designed to achieve global optimization and local detail complementation of the displacement field through dense correlation analysis and weight-balanced coupled convex optimization for input features at different scales. Our method focuses on the ReMIND2Reg task in Learn2Reg 2025. Based on the results, our method achieved the first place in the validation phase and test phase of ReMIND2Reg. The MCPO is also validated on the Resect dataset, achieving an average TRE of 1.798 mm. This demonstrates the broad applicability of our method in preoperative-to-intraoperative image registration. The code is available at https://github.com/wjiazheng/MCPO.