Predicting Camera Pose from Perspective Descriptions for Spatial Reasoning
作者: Xuejun Zhang, Aditi Tiwari, Zhenhailong Wang, Heng Ji
分类: cs.CV
发布日期: 2026-02-05
💡 一句话要点
提出CAMCUE框架,利用相机位姿进行多视角空间推理和视角预测。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多视角空间推理 相机位姿估计 视角转换 多模态融合 自然语言理解
📋 核心要点
- 多模态大语言模型在多视角空间推理中面临挑战,缺乏有效的跨视角信息融合机制。
- CAMCUE框架通过将相机位姿作为几何锚点,显式地融合多视角信息,实现更准确的空间推理。
- 实验表明,CAMCUE在视角预测和问题回答方面均有显著提升,推理速度大幅加快。
📝 摘要(中文)
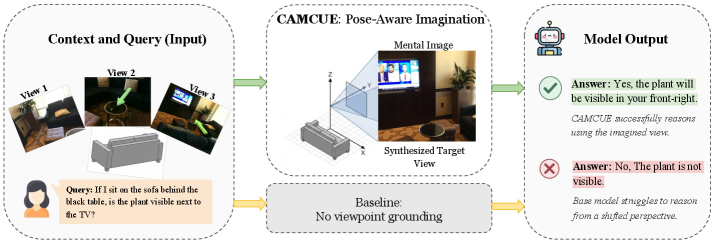
多图像空间推理对当前多模态大型语言模型(MLLM)仍然具有挑战性。单视图感知本质上是2D的,而对多个视图进行推理需要构建跨视点的连贯场景理解。本文研究了视角转换,即模型必须从多视图观察中构建连贯的3D理解,并使用它从新的、语言指定的视点进行推理。我们引入了CAMCUE,这是一个位姿感知的多图像框架,它使用相机位姿作为跨视图融合和新视角推理的显式几何锚点。CAMCUE将每个视图的位姿注入到视觉token中,将自然语言视点描述与目标相机位姿对齐,并合成位姿条件下的假想目标视图以支持回答。为了支持这种设置,我们整理了CAMCUE-DATA,其中包含27,668个训练实例和508个测试实例,将多视图图像和位姿与不同的目标视点描述和视角转换问题配对。我们还在测试集中包含了人工标注的视点描述,以评估对人类语言的泛化能力。CAMCUE将整体准确率提高了9.06%,并从自然语言视点描述中预测目标位姿,旋转精度在20°以内超过90%,平移精度在0.5误差阈值内。这种直接对齐避免了昂贵的测试时搜索和匹配,将每个示例的推理时间从256.6秒减少到1.45秒,从而可以在实际场景中实现快速、交互式的使用。
🔬 方法详解
问题定义:现有的多模态大语言模型在处理多视角空间推理任务时,难以建立不同视角之间的连贯场景理解。它们通常缺乏有效的几何信息融合机制,导致在视角转换和新视角推理方面表现不佳。现有方法推理速度慢,难以应用于实时场景。
核心思路:本文的核心思路是将相机位姿作为显式的几何锚点,用于跨视图的信息融合。通过将每个视图的相机位姿信息注入到视觉特征中,模型可以更好地理解不同视角之间的空间关系,从而实现更准确的视角预测和空间推理。这种方法避免了昂贵的测试时搜索和匹配。
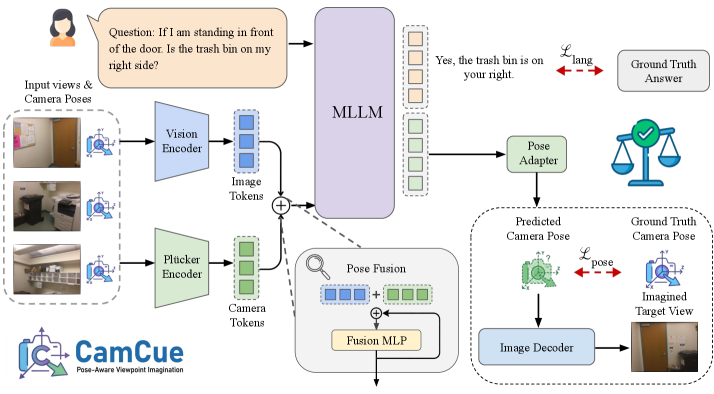
技术框架:CAMCUE框架包含以下主要模块:1) 位姿注入模块:将每个视图的相机位姿信息编码到视觉token中。2) 视点描述对齐模块:将自然语言视点描述与目标相机位姿对齐。3) 目标视图合成模块:根据目标相机位姿,合成假想的目标视图。4) 问题回答模块:利用融合的多视角信息和合成的目标视图,回答空间推理问题。
关键创新:CAMCUE最重要的技术创新点在于将相机位姿作为显式的几何锚点,用于跨视图的信息融合。与现有方法相比,CAMCUE能够更有效地利用几何信息,从而实现更准确的视角预测和空间推理。此外,CAMCUE通过直接对齐自然语言描述和相机位姿,避免了耗时的搜索匹配过程,显著提高了推理速度。
关键设计:CAMCUE的关键设计包括:1) 使用Transformer架构进行视觉特征编码和跨视图信息融合。2) 设计了特定的损失函数,用于优化相机位姿预测和目标视图合成。3) 构建了包含多视图图像、相机位姿和自然语言描述的数据集CAMCUE-DATA,用于训练和评估模型。
🖼️ 关键图片

📊 实验亮点
CAMCUE在CAMCUE-DATA数据集上取得了显著的性能提升,整体准确率提高了9.06%。在自然语言视点描述中预测目标位姿,旋转精度在20°以内超过90%,平移精度在0.5误差阈值内。此外,CAMCUE显著降低了推理时间,从256.6秒减少到1.45秒,实现了快速、交互式的使用。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、增强现实等领域。通过理解不同视角的空间关系,机器人可以更好地进行环境感知和路径规划。在自动驾驶中,该技术可以帮助车辆理解周围环境,提高驾驶安全性。在增强现实中,该技术可以实现更自然的虚拟物体放置和交互。
📄 摘要(原文)
Multi-image spatial reasoning remains challenging for current multimodal large language models (MLLMs). While single-view perception is inherently 2D, reasoning over multiple views requires building a coherent scene understanding across viewpoints. In particular, we study perspective taking, where a model must build a coherent 3D understanding from multi-view observations and use it to reason from a new, language-specified viewpoint. We introduce CAMCUE, a pose-aware multi-image framework that uses camera pose as an explicit geometric anchor for cross-view fusion and novel-view reasoning. CAMCUE injects per-view pose into visual tokens, grounds natural-language viewpoint descriptions to a target camera pose, and synthesizes a pose-conditioned imagined target view to support answering. To support this setting, we curate CAMCUE-DATA with 27,668 training and 508 test instances pairing multi-view images and poses with diverse target-viewpoint descriptions and perspective-shift questions. We also include human-annotated viewpoint descriptions in the test split to evaluate generalization to human language. CAMCUE improves overall accuracy by 9.06% and predicts target poses from natural-language viewpoint descriptions with over 90% rotation accuracy within 20° and translation accuracy within a 0.5 error threshold. This direct grounding avoids expensive test-time search-and-match, reducing inference time from 256.6s to 1.45s per example and enabling fast, interactive use in real-world scenarios.