SwimBird: Eliciting Switchable Reasoning Mode in Hybrid Autoregressive MLLMs
作者: Jintao Tong, Shilin Yan, Hongwei Xue, Xiaojun Tang, Kunyu Shi, Guannan Zhang, Ruixuan Li, Yixiong Zou
分类: cs.CV
发布日期: 2026-02-05
备注: Project Page: https://accio-lab.github.io/SwimBird
💡 一句话要点
SwimBird:提出一种混合自回归MLLM,实现可切换的推理模式以提升视觉密集任务性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 推理模式切换 混合自回归 视觉推理 文本推理 视觉问答 图像描述
📋 核心要点
- 现有MLLM在视觉密集任务中表现受限,主要原因是其推理模式僵化,无法根据任务自适应调整。
- SwimBird提出一种混合自回归MLLM,通过动态切换文本、视觉和交错三种推理模式来解决该问题。
- 实验表明,SwimBird在文本推理能力不下降的同时,显著提升了视觉密集任务的性能,达到SOTA。
📝 摘要(中文)
多模态大型语言模型(MLLMs)通过桥接视觉和语言,在多模态感知和推理方面取得了显著进展。然而,现有的大多数MLLMs主要使用文本CoT进行推理,这限制了它们在视觉密集型任务上的有效性。最近的方法将固定数量的连续隐藏状态作为“视觉思考”注入到推理过程中,提高了视觉性能,但通常以降低基于文本的逻辑推理能力为代价。我们认为,核心限制在于一种僵化的、预定义的推理模式,它无法自适应地为不同的用户查询选择最合适的思考模式。我们引入了SwimBird,这是一种推理可切换的MLLM,它可以根据输入在三种推理模式之间动态切换:(1)仅文本推理,(2)仅视觉推理(连续隐藏状态作为视觉思考),以及(3)交错的视觉-文本推理。为了实现这种能力,我们采用了一种混合自回归公式,它统一了文本思考的下一个token预测和视觉思考的下一个embedding预测,并设计了一种系统的推理模式管理策略,以构建SwimBird-SFT-92K,这是一个涵盖所有三种推理模式的多样化监督微调数据集。通过启用灵活的、查询自适应的模式选择,SwimBird保留了强大的文本逻辑,同时显著提高了视觉密集型任务的性能。涵盖文本推理和具有挑战性的视觉理解的各种基准测试的实验表明,SwimBird实现了最先进的结果,并且相对于先前的固定模式多模态推理方法获得了强大的收益。
🔬 方法详解
问题定义:现有MLLM在处理视觉密集型任务时,主要依赖文本链式推理(CoT),无法充分利用视觉信息。虽然一些方法尝试注入“视觉思考”,但往往以牺牲文本推理能力为代价。核心问题在于缺乏一种能够根据输入自适应选择推理模式的机制。
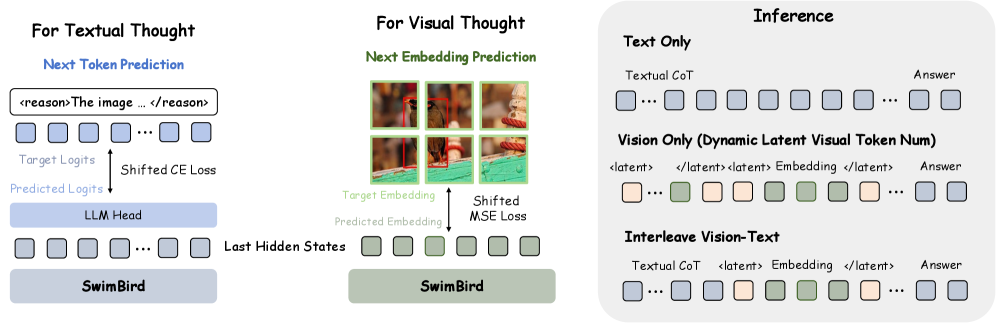
核心思路:SwimBird的核心思路是构建一个能够动态切换推理模式的MLLM。它允许模型根据输入选择最合适的推理方式,包括仅文本推理、仅视觉推理和交错的视觉-文本推理。这种自适应性使得模型既能保持强大的文本逻辑推理能力,又能有效处理视觉密集型任务。
技术框架:SwimBird采用混合自回归框架,统一处理文本和视觉“思考”。该框架包含以下主要模块:1) 输入编码器:将文本和图像输入编码为统一的表示。2) 推理模式选择器:根据输入动态选择推理模式。3) 混合自回归解码器:根据选择的推理模式,生成文本token或视觉embedding。4) 输出解码器:将视觉embedding解码为最终的输出。
关键创新:SwimBird的关键创新在于其推理模式的动态切换机制和混合自回归框架。传统的MLLM采用固定的推理模式,而SwimBird能够根据输入自适应地选择最合适的模式。混合自回归框架则允许模型同时生成文本和视觉“思考”,从而实现更灵活的推理过程。
关键设计:SwimBird的关键设计包括:1) 推理模式选择器的设计,需要能够准确判断输入的特点,并选择合适的推理模式。2) 混合自回归解码器的设计,需要能够有效地融合文本和视觉信息,并生成高质量的输出。3) SwimBird-SFT-92K数据集的构建,该数据集包含各种推理模式的样本,用于训练模型的推理模式切换能力。
🖼️ 关键图片


📊 实验亮点
SwimBird在多个基准测试中取得了显著的性能提升。在视觉问答任务中,SwimBird的准确率超过了现有SOTA模型。在图像描述任务中,SwimBird生成的描述更加准确和丰富。此外,SwimBird在保持文本推理能力的同时,显著提升了视觉密集型任务的性能,证明了其推理模式切换机制的有效性。
🎯 应用场景
SwimBird具有广泛的应用前景,包括视觉问答、图像描述、机器人导航、智能监控等领域。通过自适应地选择推理模式,SwimBird能够更有效地处理各种多模态任务,提高系统的智能化水平。未来,该研究可以进一步扩展到其他模态,例如音频和视频,从而构建更强大的多模态智能系统。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have made remarkable progress in multimodal perception and reasoning by bridging vision and language. However, most existing MLLMs perform reasoning primarily with textual CoT, which limits their effectiveness on vision-intensive tasks. Recent approaches inject a fixed number of continuous hidden states as "visual thoughts" into the reasoning process and improve visual performance, but often at the cost of degraded text-based logical reasoning. We argue that the core limitation lies in a rigid, pre-defined reasoning pattern that cannot adaptively choose the most suitable thinking modality for different user queries. We introduce SwimBird, a reasoning-switchable MLLM that dynamically switches among three reasoning modes conditioned on the input: (1) text-only reasoning, (2) vision-only reasoning (continuous hidden states as visual thoughts), and (3) interleaved vision-text reasoning. To enable this capability, we adopt a hybrid autoregressive formulation that unifies next-token prediction for textual thoughts with next-embedding prediction for visual thoughts, and design a systematic reasoning-mode curation strategy to construct SwimBird-SFT-92K, a diverse supervised fine-tuning dataset covering all three reasoning patterns. By enabling flexible, query-adaptive mode selection, SwimBird preserves strong textual logic while substantially improving performance on vision-dense tasks. Experiments across diverse benchmarks covering textual reasoning and challenging visual understanding demonstrate that SwimBird achieves state-of-the-art results and robust gains over prior fixed-pattern multimodal reasoning methods.