InterPrior: Scaling Generative Control for Physics-Based Human-Object Interactions
作者: Sirui Xu, Samuel Schulter, Morteza Ziyadi, Xialin He, Xiaohan Fei, Yu-Xiong Wang, Liangyan Gui
分类: cs.CV, cs.GR, cs.RO
发布日期: 2026-02-05
备注: Webpage: https://sirui-xu.github.io/InterPrior/
💡 一句话要点
InterPrior:通过模仿学习和强化学习扩展物理交互生成控制
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱五:交互与反应 (Interaction & Reaction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人机交互 机器人控制 模仿学习 强化学习 运动生成
📋 核心要点
- 现有方法难以在复杂的人与物体交互中泛化,尤其是在保持物理一致性的前提下。
- InterPrior通过模仿学习预训练和强化学习微调,学习统一的生成控制器,提升泛化能力。
- 实验表明,InterPrior在用户交互控制和真实机器人部署方面具有潜力,能够处理未见物体交互。
📝 摘要(中文)
本文提出InterPrior,一个可扩展的框架,通过大规模模仿预训练和强化学习后训练学习统一的生成控制器,用于基于物理的人与物体交互。InterPrior首先将一个全参考模仿专家提炼成一个通用的、目标条件变分策略,该策略从多模态观察和高层意图重建运动。虽然提炼后的策略可以重建训练行为,但由于大规模人与物体交互的巨大配置空间,它不能可靠地泛化。为了解决这个问题,我们应用了带有物理扰动的数据增强,然后进行强化学习微调,以提高对未见目标和初始化的能力。这些步骤共同将重建的潜在技能整合到一个有效的流形中,产生一个超越训练数据的运动先验,例如,它可以整合新的行为,如与未见物体的交互。我们进一步证明了它在用户交互控制方面的有效性以及在真实机器人部署方面的潜力。
🔬 方法详解
问题定义:论文旨在解决人形机器人在复杂环境中与物体进行交互时,难以生成自然、协调且物理上可行的全身运动的问题。现有方法通常难以在不同场景和物体之间泛化,并且难以保证运动的物理合理性,例如平衡、接触和操作等。
核心思路:论文的核心思路是通过模仿学习从专家数据中学习运动先验,然后利用强化学习对该先验进行微调,使其能够更好地泛化到未见过的场景和物体。这种方法结合了模仿学习的效率和强化学习的泛化能力,从而能够生成更加鲁棒和自然的交互运动。
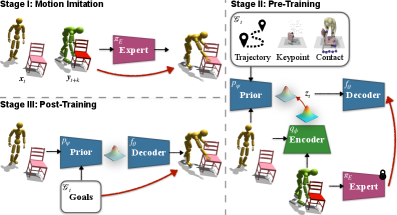
技术框架:InterPrior框架包含两个主要阶段:模仿学习预训练和强化学习微调。在模仿学习阶段,一个全参考模仿专家被提炼成一个目标条件变分策略,该策略能够从多模态观察和高层意图重建运动。在强化学习阶段,利用物理扰动进行数据增强,并使用强化学习算法对策略进行微调,以提高其在未见目标和初始化条件下的性能。
关键创新:InterPrior的关键创新在于其统一的生成控制框架,该框架能够有效地结合模仿学习和强化学习的优点,从而实现对复杂人与物体交互的生成控制。此外,该框架还采用了数据增强技术,以提高策略的泛化能力。
关键设计:在模仿学习阶段,使用了变分自编码器(VAE)来学习运动的潜在表示。在强化学习阶段,使用了近端策略优化(PPO)算法进行策略微调。此外,还设计了特定的奖励函数,以鼓励机器人生成物理上合理的运动,例如保持平衡和避免碰撞。
🖼️ 关键图片

📊 实验亮点
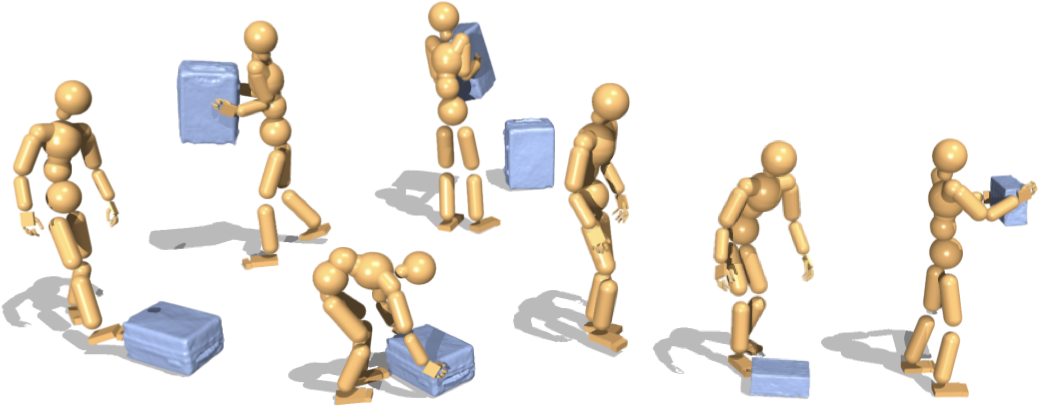
论文通过实验验证了InterPrior的有效性。实验结果表明,InterPrior能够生成自然、协调且物理上可行的全身运动,并且能够泛化到未见过的场景和物体。此外,InterPrior还在用户交互控制和真实机器人部署方面展现出潜力,能够处理与未见物体的交互。
🎯 应用场景
InterPrior可应用于机器人辅助、虚拟现实、游戏等领域。例如,可以用于训练机器人执行复杂的装配任务,或者为虚拟角色生成逼真的人与物体交互动画。该研究的潜在价值在于提高人机交互的自然性和效率,并为机器人自主操作提供更强大的工具。
📄 摘要(原文)
Humans rarely plan whole-body interactions with objects at the level of explicit whole-body movements. High-level intentions, such as affordance, define the goal, while coordinated balance, contact, and manipulation can emerge naturally from underlying physical and motor priors. Scaling such priors is key to enabling humanoids to compose and generalize loco-manipulation skills across diverse contexts while maintaining physically coherent whole-body coordination. To this end, we introduce InterPrior, a scalable framework that learns a unified generative controller through large-scale imitation pretraining and post-training by reinforcement learning. InterPrior first distills a full-reference imitation expert into a versatile, goal-conditioned variational policy that reconstructs motion from multimodal observations and high-level intent. While the distilled policy reconstructs training behaviors, it does not generalize reliably due to the vast configuration space of large-scale human-object interactions. To address this, we apply data augmentation with physical perturbations, and then perform reinforcement learning finetuning to improve competence on unseen goals and initializations. Together, these steps consolidate the reconstructed latent skills into a valid manifold, yielding a motion prior that generalizes beyond the training data, e.g., it can incorporate new behaviors such as interactions with unseen objects. We further demonstrate its effectiveness for user-interactive control and its potential for real robot deployment.