V-Retrver: Evidence-Driven Agentic Reasoning for Universal Multimodal Retrieval
作者: Dongyang Chen, Chaoyang Wang, Dezhao SU, Xi Xiao, Zeyu Zhang, Jing Xiong, Qing Li, Yuzhang Shang, Shichao Ka
分类: cs.CV
发布日期: 2026-02-05
💡 一句话要点
V-Retrver:提出证据驱动的Agentic推理框架,用于通用多模态检索。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态检索 Agentic推理 视觉证据 课程学习 大型语言模型
📋 核心要点
- 现有通用多模态检索方法依赖语言驱动和静态视觉编码,缺乏主动验证视觉证据的能力,导致视觉模糊时推理易出错。
- V-Retrver将多模态检索建模为Agentic推理,通过外部视觉工具选择性获取证据,交错进行假设生成和视觉验证。
- 采用课程学习策略训练Agent,结合监督学习、拒绝细化和强化学习,实验表明检索精度平均提升23.0%。
📝 摘要(中文)
本文提出V-Retrver,一个证据驱动的检索框架,将多模态检索重新定义为基于视觉检查的Agentic推理过程。现有方法主要依赖于语言驱动,使用静态视觉编码,缺乏主动验证细粒度视觉证据的能力,导致在视觉模糊情况下出现推测性推理。V-Retrver使MLLM能够通过外部视觉工具在推理过程中选择性地获取视觉证据,执行多模态交错推理过程,在假设生成和有针对性的视觉验证之间交替进行。为了训练这种证据收集检索Agent,采用基于课程的学习策略,结合监督推理激活、基于拒绝的细化和具有证据对齐目标的强化学习。在多个多模态检索基准上的实验表明,检索准确率得到持续提高(平均提高23.0%),感知驱动的推理可靠性和泛化能力也得到提升。
🔬 方法详解
问题定义:论文旨在解决通用多模态检索中,现有方法过度依赖语言信息和静态视觉编码,缺乏主动获取和验证细粒度视觉证据能力的问题。这导致在视觉信息模糊或复杂的情况下,检索结果的准确性和可靠性下降,容易产生推测性的错误推理。
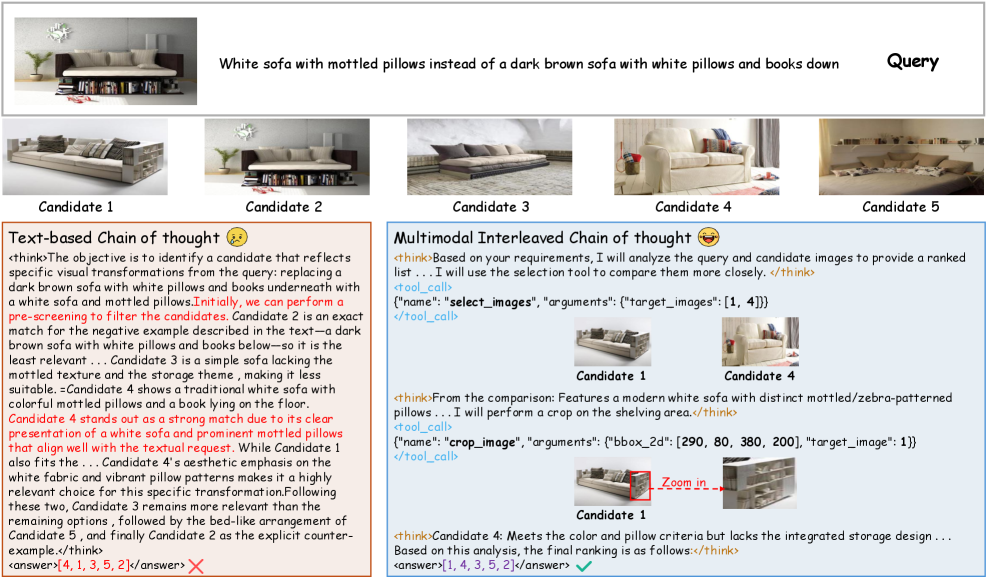
核心思路:论文的核心思路是将多模态检索过程建模为一个Agentic推理过程,Agent能够主动地与外部视觉工具交互,选择性地获取视觉证据,并根据这些证据进行推理和决策。通过这种方式,Agent可以更加准确地理解图像内容,并提高检索的准确性和可靠性。
技术框架:V-Retrver框架包含以下几个主要模块:1) 查询编码器:将文本查询编码为向量表示。2) 候选生成器:根据查询向量生成候选检索结果。3) Agentic推理模块:这是V-Retrver的核心模块,包含一个MLLM Agent,它能够:a) 根据查询和候选结果生成假设;b) 使用外部视觉工具(如目标检测器、图像分割器等)获取视觉证据;c) 根据视觉证据验证假设,并更新推理状态;d) 最终输出检索结果的排序。4) 视觉工具:提供视觉证据获取能力,例如目标检测、图像分割等。
关键创新:V-Retrver的关键创新在于:1) 将多模态检索建模为Agentic推理过程,使模型能够主动获取和验证视觉证据。2) 提出了一个多模态交错推理过程,在假设生成和视觉验证之间交替进行,从而提高推理的准确性和可靠性。3) 采用课程学习策略训练Agent,结合监督学习、拒绝细化和强化学习,提高了Agent的性能和泛化能力。
关键设计:1) 课程学习策略:包括三个阶段:a) 监督推理激活:使用人工标注的推理路径训练Agent,使其初步具备推理能力。b) 基于拒绝的细化:通过拒绝错误的推理路径,提高Agent的推理准确性。c) 强化学习:使用证据对齐的奖励函数,鼓励Agent获取有用的视觉证据。2) 证据对齐的奖励函数:奖励Agent获取与查询相关的视觉证据,惩罚Agent获取无关的证据。3) 视觉工具的选择:根据不同的检索任务选择合适的视觉工具,例如,对于需要识别特定物体的任务,可以使用目标检测器;对于需要理解图像结构的任務,可以使用图像分割器。
🖼️ 关键图片


📊 实验亮点
实验结果表明,V-Retrver在多个多模态检索基准上取得了显著的性能提升,平均检索准确率提高了23.0%。与现有方法相比,V-Retrver能够更准确地理解图像内容,并做出更可靠的推理。此外,V-Retrver还具有较好的泛化能力,能够在不同的数据集和任务上取得良好的性能。
🎯 应用场景
V-Retrver具有广泛的应用前景,例如:电商领域的商品检索、医学影像诊断、安防监控等。通过主动获取和验证视觉证据,V-Retrver可以提高检索的准确性和可靠性,从而提升用户体验和工作效率。未来,该研究可以进一步扩展到其他多模态任务,例如视觉问答、图像描述等。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have recently been applied to universal multimodal retrieval, where Chain-of-Thought (CoT) reasoning improves candidate reranking. However, existing approaches remain largely language-driven, relying on static visual encodings and lacking the ability to actively verify fine-grained visual evidence, which often leads to speculative reasoning in visually ambiguous cases. We propose V-Retrver, an evidence-driven retrieval framework that reformulates multimodal retrieval as an agentic reasoning process grounded in visual inspection. V-Retrver enables an MLLM to selectively acquire visual evidence during reasoning via external visual tools, performing a multimodal interleaved reasoning process that alternates between hypothesis generation and targeted visual verification.To train such an evidence-gathering retrieval agent, we adopt a curriculum-based learning strategy combining supervised reasoning activation, rejection-based refinement, and reinforcement learning with an evidence-aligned objective. Experiments across multiple multimodal retrieval benchmarks demonstrate consistent improvements in retrieval accuracy (with 23.0% improvements on average), perception-driven reasoning reliability, and generalization.