Splat and Distill: Augmenting Teachers with Feed-Forward 3D Reconstruction For 3D-Aware Distillation
作者: David Shavin, Sagie Benaim
分类: cs.CV
发布日期: 2026-02-05
备注: Accepted to ICLR 2026
期刊: ICLR 2026
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出Splat and Distill框架,通过前馈3D重建增强教师模型,提升2D视觉模型的3D感知能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D感知 知识蒸馏 视觉基础模型 前馈网络 3D重建
📋 核心要点
- 现有的视觉基础模型在2D任务上表现出色,但普遍缺乏3D感知能力,限制了其应用。
- Splat and Distill框架通过前馈3D重建增强教师模型,将2D特征提升到3D空间,并蒸馏到学生模型,提升3D感知。
- 实验表明,该方法在单目深度估计、表面法线估计等多项任务上显著优于现有方法,提升了3D感知和语义丰富性。
📝 摘要(中文)
本文提出Splat and Distill框架,旨在通过快速前馈3D重建流水线增强教师模型,从而为2D视觉基础模型(VFMs)注入强大的3D感知能力。该方法首先将教师模型产生的2D特征以feed-forward的方式提升到显式的3D高斯表示。然后,将这些3D特征“splatting”到新的视角,生成一组新的2D特征图,用于监督学生模型,从而“蒸馏”出具有几何基础的知识。通过用前馈提升方法取代先前工作中缓慢的逐场景优化,我们的框架避免了特征平均伪影,创建了一个动态的学习过程,其中教师的一致性与学生的一致性一起提高。我们在包括单目深度估计、表面法线估计、多视图对应和语义分割在内的一系列下游任务上进行了全面评估。我们的方法显著优于先前的工作,不仅在3D感知方面取得了显著的提升,而且还增强了底层2D特征的语义丰富性。
🔬 方法详解
问题定义:现有视觉基础模型在处理2D任务时表现出色,但缺乏对3D场景的理解能力。以往的3D感知方法通常需要耗时的逐场景优化,或者引入特征平均伪影,限制了模型的泛化能力和效率。
核心思路:Splat and Distill的核心在于利用一个快速的前馈3D重建流水线来增强教师模型,从而将3D几何知识传递给学生模型。通过将2D特征提升到3D高斯表示,并从新的视角进行splatting,可以生成具有几何一致性的监督信号,避免了传统方法的优化瓶颈和伪影问题。
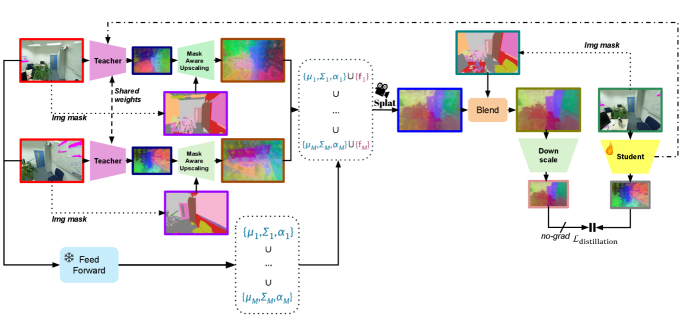
技术框架:该框架包含以下主要模块:1) 2D特征提取:使用预训练的2D视觉基础模型提取图像的2D特征。2) 3D提升:将2D特征通过前馈网络提升到3D高斯表示,得到每个像素在3D空间中的位置、方差和特征向量。3) Splatting:将3D高斯表示splatting到新的视角,生成新的2D特征图。4) 知识蒸馏:使用新的2D特征图作为监督信号,训练学生模型,使其学习到3D几何知识。
关键创新:该方法最重要的创新在于使用前馈网络进行3D重建,避免了以往方法中耗时的逐场景优化。这种方法不仅提高了效率,还避免了特征平均伪影,使得教师模型和学生模型能够在一个动态的学习过程中共同进步。
关键设计:3D提升模块使用一个多层感知机(MLP)将2D特征映射到3D高斯参数。Splatting过程使用可微分的渲染技术,将3D高斯投影到新的视角,并生成2D特征图。知识蒸馏使用L1损失或L2损失来衡量学生模型和教师模型之间的特征差异。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Splat and Distill框架在单目深度估计、表面法线估计、多视图对应和语义分割等任务上均取得了显著的提升。例如,在单目深度估计任务上,该方法相比现有方法取得了超过10%的性能提升,证明了其在提升3D感知能力方面的有效性。
🎯 应用场景
该研究成果可广泛应用于机器人导航、自动驾驶、增强现实等领域。通过提升视觉模型的3D感知能力,可以提高机器人对环境的理解和交互能力,增强自动驾驶系统的安全性和可靠性,并为AR应用提供更逼真的3D场景重建。
📄 摘要(原文)
Vision Foundation Models (VFMs) have achieved remarkable success when applied to various downstream 2D tasks. Despite their effectiveness, they often exhibit a critical lack of 3D awareness. To this end, we introduce Splat and Distill, a framework that instills robust 3D awareness into 2D VFMs by augmenting the teacher model with a fast, feed-forward 3D reconstruction pipeline. Given 2D features produced by a teacher model, our method first lifts these features into an explicit 3D Gaussian representation, in a feedforward manner. These 3D features are then
splatted" onto novel viewpoints, producing a set of novel 2D feature maps used to supervise the student model,distilling" geometrically grounded knowledge. By replacing slow per-scene optimization of prior work with our feed-forward lifting approach, our framework avoids feature-averaging artifacts, creating a dynamic learning process where the teacher's consistency improves alongside that of the student. We conduct a comprehensive evaluation on a suite of downstream tasks, including monocular depth estimation, surface normal estimation, multi-view correspondence, and semantic segmentation. Our method significantly outperforms prior works, not only achieving substantial gains in 3D awareness but also enhancing the underlying semantic richness of 2D features. Project page is available at https://davidshavin4.github.io/Splat-and-Distill/