MambaVF: State Space Model for Efficient Video Fusion
作者: Zixiang Zhao, Yukun Cui, Lilun Deng, Haowen Bai, Haotong Qin, Tao Feng, Konrad Schindler
分类: cs.CV
发布日期: 2026-02-05
💡 一句话要点
MambaVF:基于状态空间模型的高效视频融合框架,无需光流估计。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 视频融合 状态空间模型 时间建模 多模态融合 高效计算 深度学习 Mamba 序列建模
📋 核心要点
- 现有视频融合方法依赖光流估计和特征扭曲,导致计算开销大和可扩展性有限。
- MambaVF基于状态空间模型,通过序列状态更新过程捕捉长程时间依赖,无需显式运动估计。
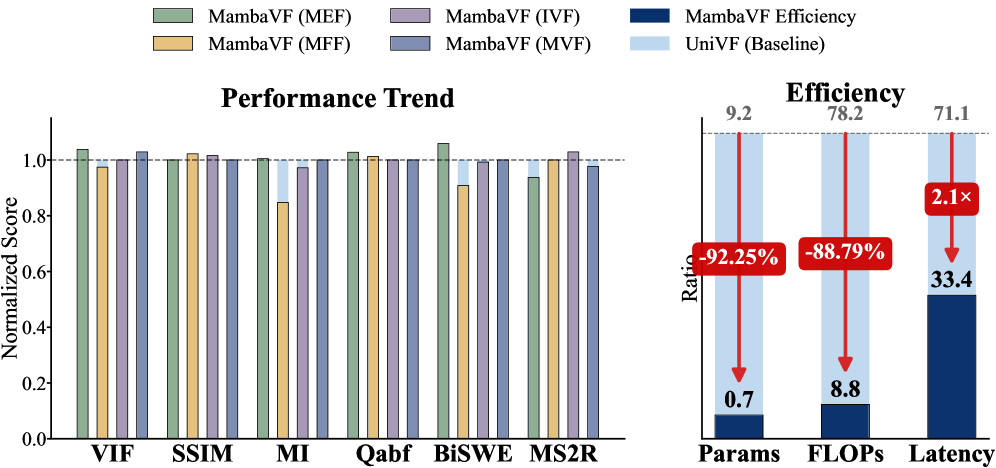
- 实验表明,MambaVF在多个视频融合任务中达到SOTA,并显著降低参数量和计算量。
📝 摘要(中文)
本文提出了一种名为MambaVF的高效视频融合框架,该框架基于状态空间模型(SSM),无需显式的运动估计即可进行时间建模。MambaVF将视频融合重新定义为一个序列状态更新过程,以线性复杂度捕获长程时间依赖关系,同时显著降低计算和内存成本。此外,MambaVF提出了一个轻量级的基于SSM的融合模块,该模块通过时空双向扫描机制取代了传统的基于光流引导的对齐方式,从而能够有效地聚合跨帧信息。在多个基准测试上的大量实验表明,MambaVF在多曝光、多焦点、红外-可见光和医学视频融合任务中实现了最先进的性能。MambaVF具有很高的效率,与现有方法相比,参数减少高达92.25%,计算FLOPs减少高达88.79%,速度提升2.1倍。
🔬 方法详解
问题定义:视频融合旨在将来自不同来源或具有不同属性(如曝光、焦点、模态)的多个视频帧的信息融合在一起,生成一个信息更丰富、质量更高的视频。现有方法通常依赖于光流估计来对齐不同帧之间的运动,然后进行特征融合。然而,光流估计本身计算量大,且容易出错,导致融合结果不准确,并且限制了方法的效率和可扩展性。
核心思路:MambaVF的核心思路是利用状态空间模型(SSM)来建模视频序列的时间依赖关系,从而避免了显式的光流估计。通过将视频融合过程建模为一个序列状态更新过程,MambaVF能够以线性复杂度捕获长程时间依赖,并显著降低计算和内存成本。此外,MambaVF还设计了一个轻量级的基于SSM的融合模块,通过时空双向扫描机制实现跨帧信息的有效聚合。
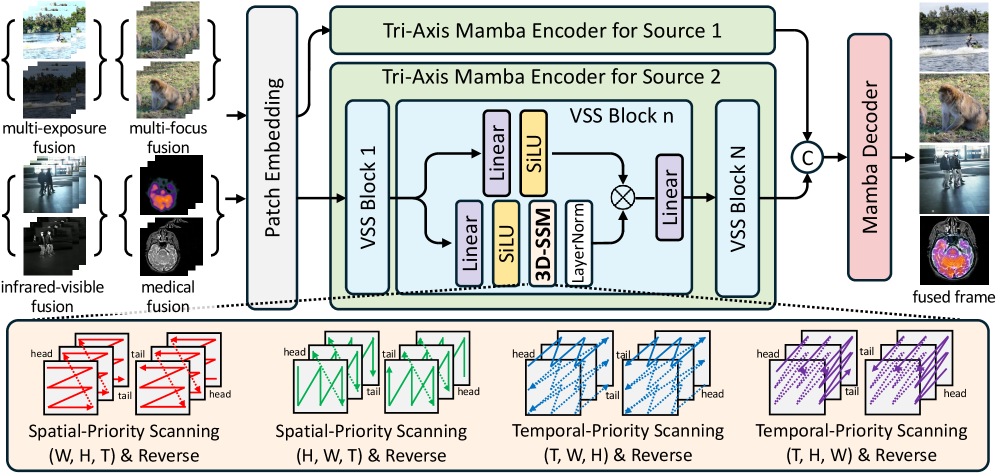
技术框架:MambaVF的整体框架包括以下几个主要步骤:1) 输入多帧视频序列;2) 使用轻量级卷积神经网络提取每帧的特征;3) 将提取的特征输入到基于SSM的融合模块中,该模块通过时空双向扫描机制进行信息聚合;4) 使用解码器将融合后的特征映射回像素空间,生成融合后的视频帧。
关键创新:MambaVF最重要的技术创新点在于使用状态空间模型(SSM)来建模视频序列的时间依赖关系,并设计了一个轻量级的基于SSM的融合模块。与现有方法相比,MambaVF无需进行光流估计,从而显著降低了计算复杂度,提高了效率和可扩展性。此外,MambaVF的时空双向扫描机制能够更有效地聚合跨帧信息,从而提高了融合结果的质量。
关键设计:MambaVF的关键设计包括:1) 使用Mamba架构作为SSM的基础,以实现高效的序列建模;2) 设计了时空双向扫描机制,以实现跨帧信息的有效聚合;3) 使用轻量级卷积神经网络提取特征,以降低计算成本;4) 针对不同的视频融合任务,设计了相应的损失函数,以优化融合结果。
🖼️ 关键图片

📊 实验亮点
MambaVF在多曝光、多焦点、红外-可见光和医学视频融合等多个基准测试中取得了state-of-the-art的性能。与现有方法相比,MambaVF的参数量减少高达92.25%,计算FLOPs减少高达88.79%,速度提升2.1倍。这些实验结果充分证明了MambaVF的效率和有效性。
🎯 应用场景
MambaVF在多个视频处理领域具有广泛的应用前景,包括但不限于:多曝光视频融合(HDR视频生成)、多焦点视频融合(景深扩展)、红外-可见光视频融合(夜视增强)、医学视频融合(图像引导手术)等。该研究成果有助于提高视频处理系统的效率和性能,为相关领域的实际应用提供更强大的技术支持。
📄 摘要(原文)
Video fusion is a fundamental technique in various video processing tasks. However, existing video fusion methods heavily rely on optical flow estimation and feature warping, resulting in severe computational overhead and limited scalability. This paper presents MambaVF, an efficient video fusion framework based on state space models (SSMs) that performs temporal modeling without explicit motion estimation. First, by reformulating video fusion as a sequential state update process, MambaVF captures long-range temporal dependencies with linear complexity while significantly reducing computation and memory costs. Second, MambaVF proposes a lightweight SSM-based fusion module that replaces conventional flow-guided alignment via a spatio-temporal bidirectional scanning mechanism. This module enables efficient information aggregation across frames. Extensive experiments across multiple benchmarks demonstrate that our MambaVF achieves state-of-the-art performance in multi-exposure, multi-focus, infrared-visible, and medical video fusion tasks. We highlight that MambaVF enjoys high efficiency, reducing up to 92.25% of parameters and 88.79% of computational FLOPs and a 2.1x speedup compared to existing methods. Project page: https://mambavf.github.io