VisRefiner: Learning from Visual Differences for Screenshot-to-Code Generation
作者: Jie Deng, Kaichun Yao, Libo Zhang
分类: cs.CV
发布日期: 2026-02-05
💡 一句话要点
VisRefiner:通过学习视觉差异改进截图到代码的生成
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 截图到代码生成 视觉差异学习 强化学习 多模态学习 用户界面生成
📋 核心要点
- 现有方法缺乏对生成代码视觉结果的观察,导致生成质量受限。
- VisRefiner框架通过学习渲染结果与目标设计的视觉差异来优化代码生成。
- 实验表明,VisRefiner显著提升了单步生成质量、布局保真度以及模型的自我完善能力。
📝 摘要(中文)
截图到代码生成旨在将用户界面截图转换为可执行的前端代码,忠实地再现目标布局和样式。现有的多模态大型语言模型直接从截图进行这种映射,但训练时没有观察到其生成代码的视觉结果。相比之下,人类开发者会迭代地渲染他们的实现,将其与设计进行比较,并学习视觉差异与代码更改之间的关系。受此过程的启发,我们提出了VisRefiner,这是一个训练框架,使模型能够从渲染预测和参考设计之间的视觉差异中学习。我们构建了差异对齐的监督,将视觉差异与相应的代码编辑相关联,使模型能够理解外观变化是如何由实现更改引起的。在此基础上,我们引入了一个用于自我完善的强化学习阶段,模型通过观察渲染输出和目标设计,识别它们的视觉差异,并相应地更新代码,从而改进其生成的代码。实验表明,VisRefiner显著提高了单步生成质量和布局保真度,同时也赋予了模型强大的自我完善能力。这些结果证明了从视觉差异中学习对于推进截图到代码生成是有效的。
🔬 方法详解
问题定义:论文旨在解决截图到代码生成任务中,现有模型无法有效利用生成代码的视觉反馈信息,导致生成代码在布局和样式上与目标设计存在差异的问题。现有方法主要依赖于直接从截图到代码的映射,忽略了代码渲染后的视觉效果,缺乏迭代优化和视觉对齐的能力。
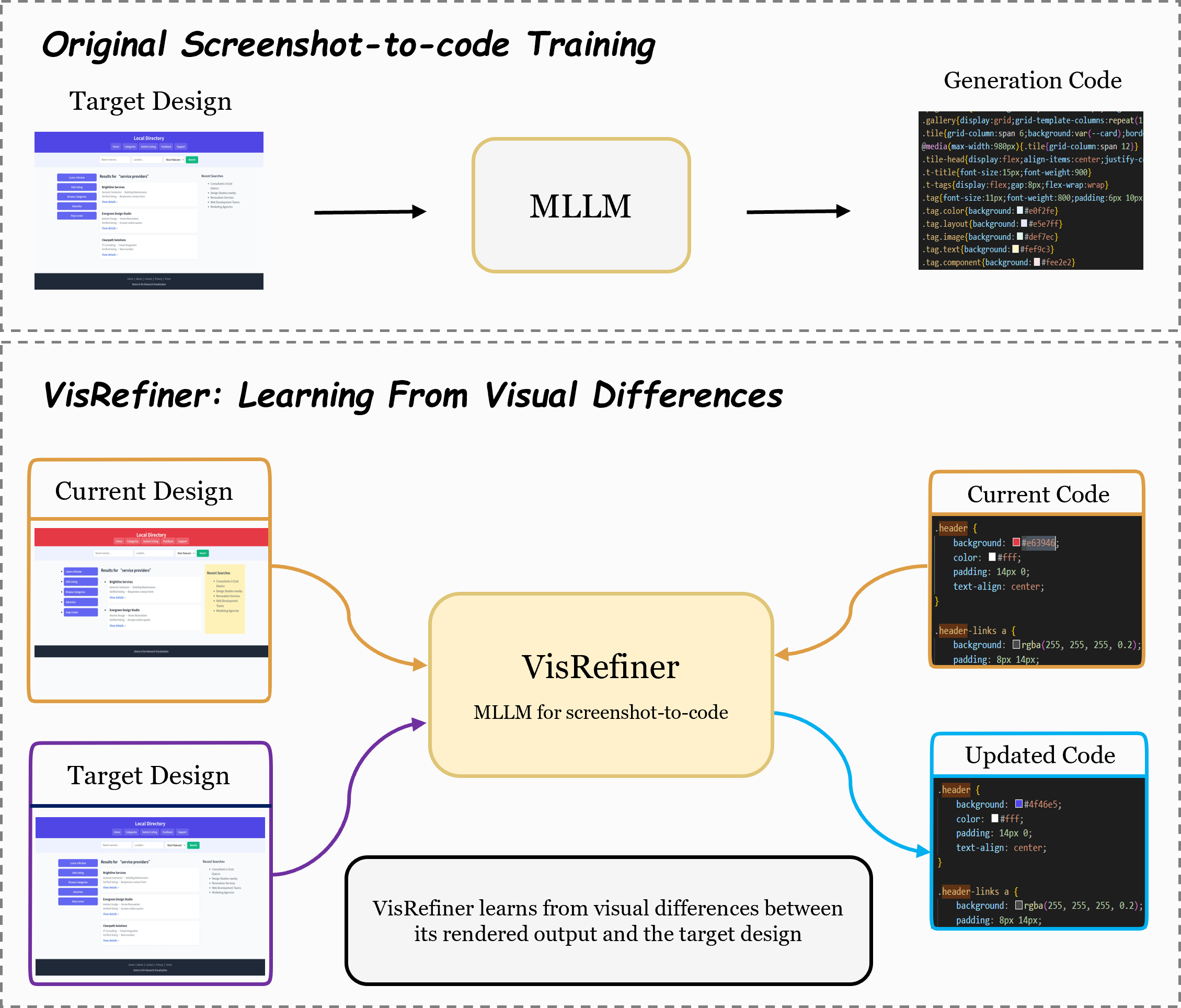
核心思路:论文的核心思路是模仿人类开发者迭代开发的过程,即渲染代码、比较视觉效果、根据差异调整代码。通过让模型学习视觉差异与代码修改之间的关系,使其能够根据渲染结果与目标设计的差异进行自我完善,从而提高生成代码的质量和保真度。
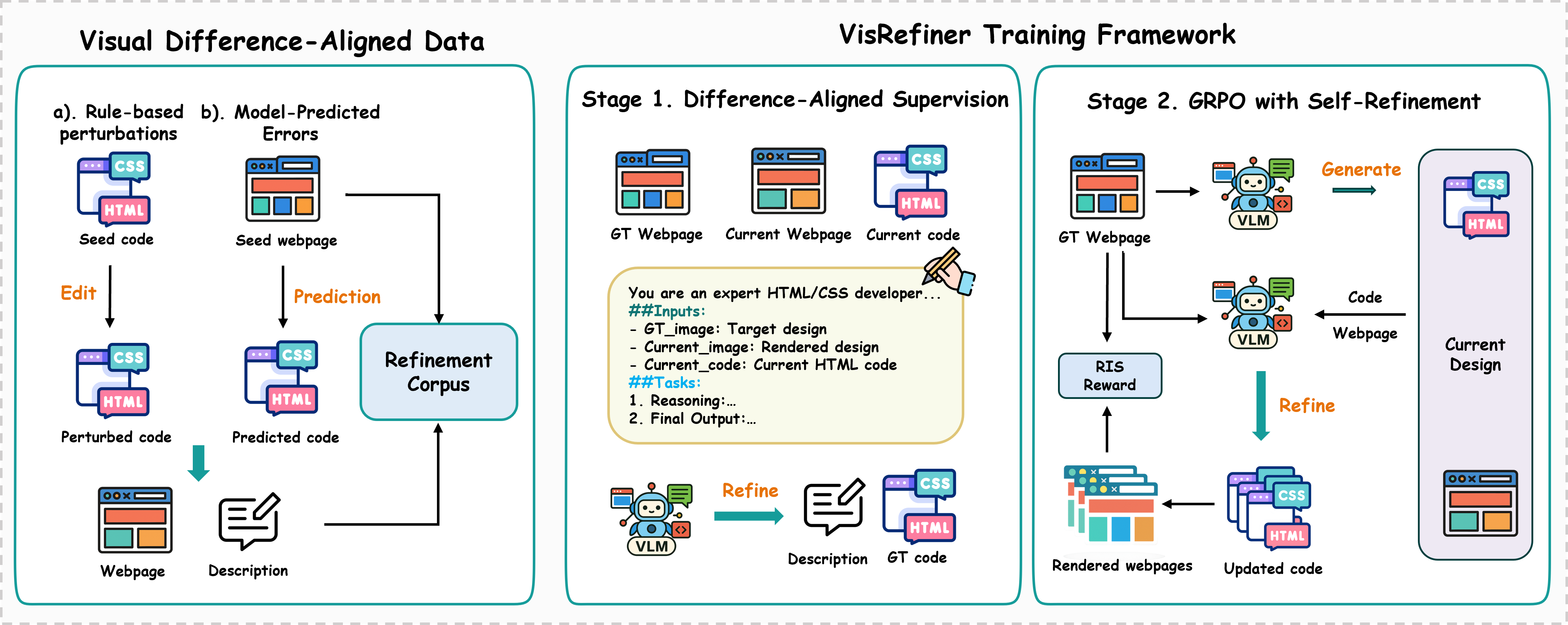
技术框架:VisRefiner框架包含两个主要阶段:差异对齐监督学习和强化学习自我完善。在差异对齐监督学习阶段,模型学习将视觉差异与相应的代码编辑相关联。在强化学习自我完善阶段,模型通过观察渲染输出和目标设计,识别视觉差异,并使用强化学习算法更新代码,以最小化视觉差异。整体流程是一个迭代的优化过程,模型不断地根据视觉反馈调整代码,直到达到满意的视觉效果。
关键创新:论文的关键创新在于引入了视觉差异学习的概念,并将其应用于截图到代码生成任务中。通过构建差异对齐的监督数据和设计强化学习的奖励函数,模型能够有效地学习视觉差异与代码修改之间的关系,从而实现自我完善。这种方法不同于以往的直接映射方法,它更加注重视觉反馈和迭代优化。
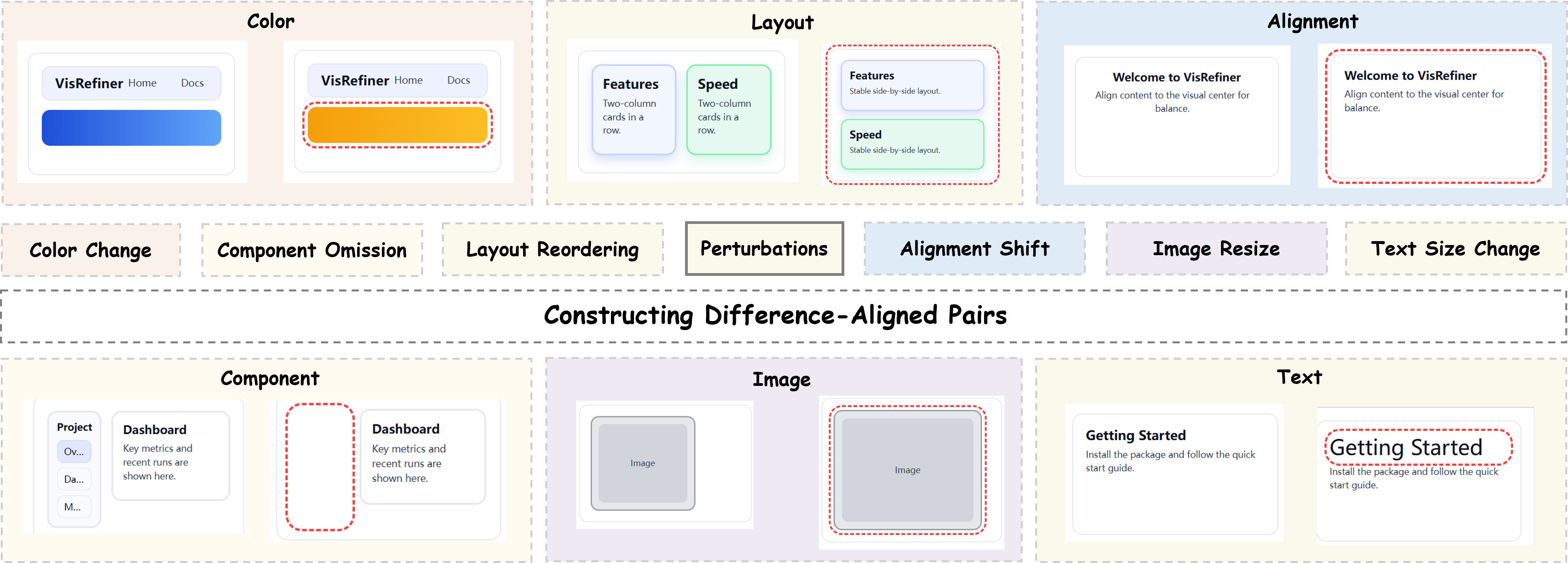
关键设计:在差异对齐监督学习阶段,论文构建了包含视觉差异和对应代码编辑的数据集。在强化学习阶段,奖励函数的设计至关重要,论文使用了基于视觉相似度的奖励函数,鼓励模型生成与目标设计视觉效果相似的代码。具体的网络结构和参数设置在论文中有详细描述,但总体上是基于现有的多模态大型语言模型进行改进。
🖼️ 关键图片
📊 实验亮点
实验结果表明,VisRefiner在单步生成质量和布局保真度方面均优于现有方法。通过引入视觉差异学习和强化学习自我完善,VisRefiner能够显著提高生成代码的视觉效果,并赋予模型强大的自我完善能力。具体的性能提升数据在论文中有详细展示,证明了VisRefiner的有效性。
🎯 应用场景
VisRefiner技术可应用于自动化前端开发、UI设计辅助、低代码/无代码平台等领域。它可以帮助开发者快速生成高质量的前端代码,提高开发效率,降低开发成本。未来,该技术有望进一步扩展到移动应用开发、游戏UI生成等领域,实现更智能化的用户界面生成。
📄 摘要(原文)
Screenshot-to-code generation aims to translate user interface screenshots into executable frontend code that faithfully reproduces the target layout and style. Existing multimodal large language models perform this mapping directly from screenshots but are trained without observing the visual outcomes of their generated code. In contrast, human developers iteratively render their implementation, compare it with the design, and learn how visual differences relate to code changes. Inspired by this process, we propose VisRefiner, a training framework that enables models to learn from visual differences between rendered predictions and reference designs. We construct difference-aligned supervision that associates visual discrepancies with corresponding code edits, allowing the model to understand how appearance variations arise from implementation changes. Building on this, we introduce a reinforcement learning stage for self-refinement, where the model improves its generated code by observing both the rendered output and the target design, identifying their visual differences, and updating the code accordingly. Experiments show that VisRefiner substantially improves single-step generation quality and layout fidelity, while also endowing models with strong self-refinement ability. These results demonstrate the effectiveness of learning from visual differences for advancing screenshot-to-code generation.