Sparse Video Generation Propels Real-World Beyond-the-View Vision-Language Navigation
作者: Hai Zhang, Siqi Liang, Li Chen, Yuxian Li, Yukuan Xu, Yichao Zhong, Fu Zhang, Hongyang Li
分类: cs.CV, cs.RO
发布日期: 2026-02-05
💡 一句话要点
SparseVideoNav:利用稀疏视频生成实现真实场景下超越视野的视觉语言导航
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言导航 超越视野导航 视频生成模型 长程规划 稀疏视频生成
📋 核心要点
- 现有视觉语言导航依赖详细指令,与真实场景需求不符,超越视野导航(BVN)旨在解决仅凭高层意图导航的问题。
- SparseVideoNav利用视频生成模型天然的长程监督优势,生成稀疏未来轨迹,指导智能体进行BVN。
- SparseVideoNav在真实场景零样本实验中,BVN任务成功率达SOTA LLM基线的2.5倍,并在夜间场景取得突破。
📝 摘要(中文)
本文提出了一种新的视觉语言导航任务:超越视野导航(BVN),即智能体仅在高层意图的引导下,在未知环境中定位远处、未见过的目标,无需详细的逐步指令。现有基于大型语言模型(LLM)的方法虽然擅长遵循密集指令,但由于依赖于短视监督,常常表现出短视行为。简单地延长监督范围会破坏LLM的训练稳定性。本文发现视频生成模型天然受益于长程监督,从而与语言指令对齐,使其非常适合BVN任务。因此,首次将视频生成模型引入该领域。为了解决视频生成模型推理延迟过高的问题,提出了SparseVideoNav,通过生成的跨越20秒范围的稀疏未来轨迹,实现了亚秒级的轨迹推理,相比未优化的版本实现了27倍的加速。在真实场景下的零样本实验表明,SparseVideoNav在BVN任务上的成功率是现有最先进LLM基线的2.5倍,并且首次在具有挑战性的夜间场景中实现了这种能力。
🔬 方法详解
问题定义:论文旨在解决超越视野导航(BVN)问题,即智能体在没有详细的逐步指令的情况下,仅根据高级别的意图在未知环境中导航到远处的目标。现有基于LLM的方法虽然擅长处理详细指令,但由于依赖于短视监督,容易出现短视行为,难以完成BVN任务。直接延长监督范围又会 destabilize LLM 的训练。
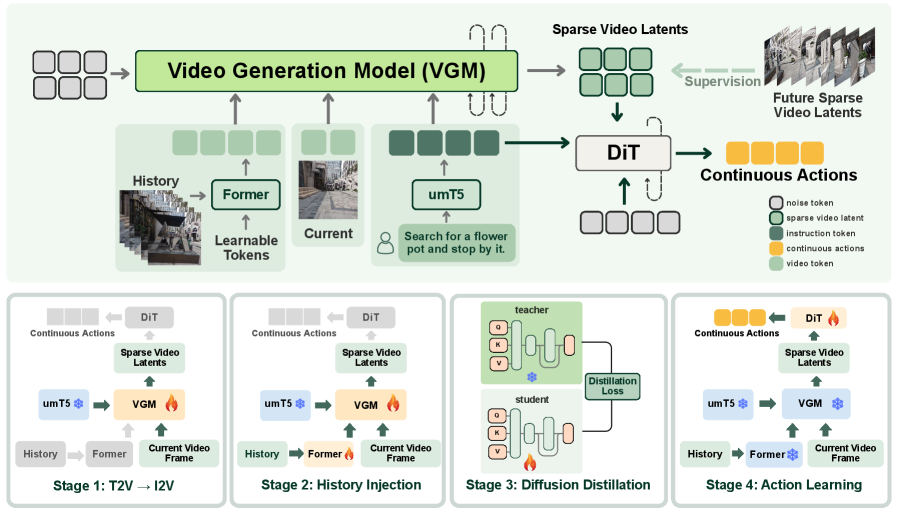
核心思路:论文的核心思路是利用视频生成模型进行长程规划。视频生成模型天然受益于长程监督,能够更好地与语言指令对齐,从而克服LLM的短视问题。通过生成未来一段时间内的稀疏视频帧,引导智能体进行导航。
技术框架:SparseVideoNav 的整体框架包含以下几个主要模块:1) 语言指令编码器:将高层意图的语言指令编码成向量表示。2) 视频生成模型:根据当前状态和语言指令,生成未来一段时间内的稀疏视频帧。3) 轨迹规划器:根据生成的稀疏视频帧,规划出智能体的行动轨迹。4) 运动控制器:控制智能体按照规划的轨迹运动。
关键创新:论文的关键创新在于将视频生成模型引入到视觉语言导航领域,并提出了 SparseVideoNav 框架,通过生成稀疏未来视频帧来实现长程规划。与现有方法相比,SparseVideoNav 不需要详细的逐步指令,能够更好地适应真实场景的需求。此外,通过生成稀疏视频帧,显著降低了计算复杂度,提高了推理速度。
关键设计:SparseVideoNav 的关键设计包括:1) 视频生成模型的选择:论文选择了能够生成高质量、多样性视频帧的生成模型。2) 稀疏视频帧的生成策略:论文设计了一种自适应的稀疏视频帧生成策略,根据场景的复杂程度动态调整视频帧的密度。3) 轨迹规划器的设计:论文设计了一种基于模型预测控制(MPC)的轨迹规划器,能够根据生成的稀疏视频帧,规划出平滑、安全的行动轨迹。
🖼️ 关键图片


📊 实验亮点
SparseVideoNav 在真实场景下的零样本实验中,BVN 任务的成功率达到了现有最先进 LLM 基线的 2.5 倍。此外,SparseVideoNav 首次在具有挑战性的夜间场景中实现了 BVN 能力。通过生成稀疏视频帧,SparseVideoNav 实现了亚秒级的轨迹推理,相比未优化的版本实现了 27 倍的加速。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、智能家居等领域。例如,在智能家居中,用户只需告诉机器人“去客厅”,机器人即可自主规划路线并到达目标地点。在自动驾驶领域,车辆可以根据用户的目的地,自主规划行驶路线,无需人工干预。该研究的突破为实现更智能、更自主的机器人系统奠定了基础。
📄 摘要(原文)
Why must vision-language navigation be bound to detailed and verbose language instructions? While such details ease decision-making, they fundamentally contradict the goal for navigation in the real-world. Ideally, agents should possess the autonomy to navigate in unknown environments guided solely by simple and high-level intents. Realizing this ambition introduces a formidable challenge: Beyond-the-View Navigation (BVN), where agents must locate distant, unseen targets without dense and step-by-step guidance. Existing large language model (LLM)-based methods, though adept at following dense instructions, often suffer from short-sighted behaviors due to their reliance on short-horimzon supervision. Simply extending the supervision horizon, however, destabilizes LLM training. In this work, we identify that video generation models inherently benefit from long-horizon supervision to align with language instructions, rendering them uniquely suitable for BVN tasks. Capitalizing on this insight, we propose introducing the video generation model into this field for the first time. Yet, the prohibitive latency for generating videos spanning tens of seconds makes real-world deployment impractical. To bridge this gap, we propose SparseVideoNav, achieving sub-second trajectory inference guided by a generated sparse future spanning a 20-second horizon. This yields a remarkable 27x speed-up compared to the unoptimized counterpart. Extensive real-world zero-shot experiments demonstrate that SparseVideoNav achieves 2.5x the success rate of state-of-the-art LLM baselines on BVN tasks and marks the first realization of such capability in challenging night scenes.