NVS-HO: A Benchmark for Novel View Synthesis of Handheld Objects
作者: Musawar Ali, Manuel Carranza-García, Nicola Fioraio, Samuele Salti, Luigi Di Stefano
分类: cs.CV
发布日期: 2026-02-05
💡 一句话要点
NVS-HO:首个手持物体新视角合成的RGB基准数据集
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 新视角合成 手持物体 基准数据集 RGB图像 NeRF Gaussian Splatting 姿态估计 三维重建
📋 核心要点
- 现有新视角合成方法在处理真实场景下手持物体时,由于姿态估计不准确等问题,性能表现不佳。
- NVS-HO数据集通过手持序列学习物体外观,并利用ChArUco板序列提供精确的相机姿态作为ground truth,用于评估。
- 论文基于NeRF和Gaussian Splatting等方法建立了基线,实验结果揭示了现有方法在手持物体新视角合成方面的局限性。
📝 摘要(中文)
本文提出了NVS-HO,这是首个专门用于手持物体在真实环境中新视角合成的基准数据集,仅使用RGB输入。每个物体都记录在两个互补的RGB序列中:(1)手持序列,其中物体在静态相机前被操作;(2)板序列,其中物体固定在ChArUco板上,通过标记检测提供精确的相机姿态。NVS-HO的目标是从(1)中学习一个能够捕捉物体完整外观的NVS模型,而(2)提供用于评估的ground-truth图像。为了建立基线,我们考虑了经典的SfM流程和最先进的预训练前馈神经网络(VGGT)作为姿态估计器,并训练了基于NeRF和Gaussian Splatting的NVS模型。实验表明,当前方法在不受约束的手持条件下存在显著的性能差距,突出了对更鲁棒方法的需求。因此,NVS-HO提供了一个具有挑战性的真实世界基准,以推动基于RGB的手持物体新视角合成的进展。
🔬 方法详解
问题定义:论文旨在解决手持物体新视角合成问题,现有方法在处理真实场景下手持物体时,由于缺乏精确的相机姿态信息,导致合成效果不佳。现有的方法难以应对手持物体姿态变化大、光照条件复杂等挑战。
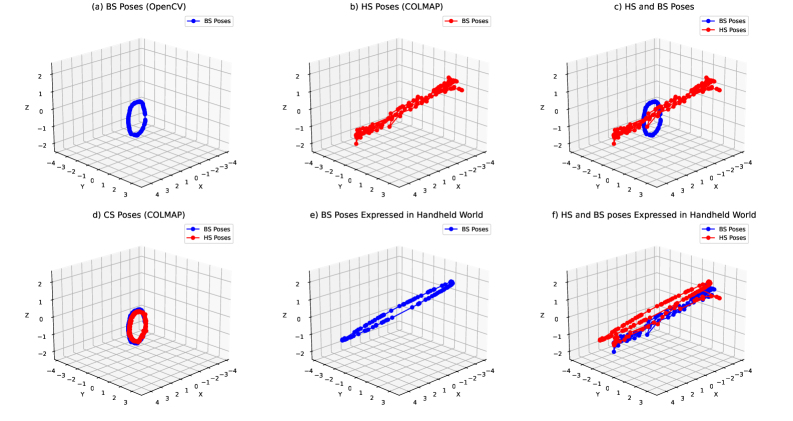
核心思路:论文的核心思路是构建一个包含手持序列和板序列的基准数据集。手持序列用于训练新视角合成模型,板序列提供精确的相机姿态作为ground truth,用于评估模型的性能。通过这种方式,可以更准确地评估和比较不同方法在手持物体新视角合成方面的表现。
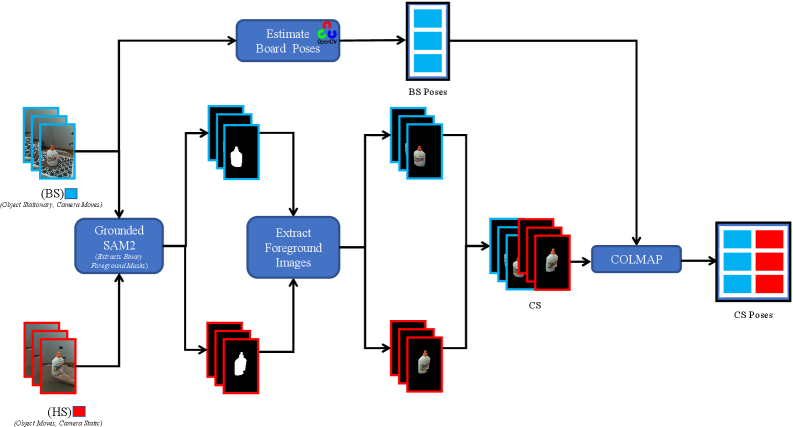
技术框架:NVS-HO数据集的构建流程包括:1)使用RGB相机记录手持物体在真实场景中的手持序列;2)将物体固定在ChArUco板上,记录板序列,并通过标记检测获取精确的相机姿态;3)使用手持序列训练新视角合成模型;4)使用板序列生成的图像作为ground truth,评估模型的性能。论文使用了经典的SfM流程和预训练的VGGT网络作为姿态估计器,并训练了基于NeRF和Gaussian Splatting的NVS模型。
关键创新:该论文的关键创新在于构建了首个专门针对手持物体新视角合成的RGB基准数据集NVS-HO。该数据集提供了真实场景下的手持序列和精确的相机姿态信息,为研究人员提供了一个评估和比较不同方法的平台。与现有数据集相比,NVS-HO更具挑战性,更贴近实际应用场景。
关键设计:NVS-HO数据集的关键设计包括:1)使用两个互补的RGB序列,即手持序列和板序列,分别用于训练和评估新视角合成模型;2)使用ChArUco板提供精确的相机姿态信息;3)考虑了真实场景下的光照变化和物体姿态变化等因素。论文还选择了NeRF和Gaussian Splatting作为基线方法,并对它们的性能进行了评估。
🖼️ 关键图片

📊 实验亮点
实验结果表明,现有的新视角合成方法在NVS-HO数据集上表现不佳,尤其是在处理不受约束的手持序列时,性能下降明显。这表明需要开发更鲁棒的新视角合成方法,以应对真实场景下的挑战。论文提供的基线结果可以作为未来研究的参考。
🎯 应用场景
该研究成果可应用于机器人抓取、增强现实、虚拟现实、三维重建等领域。例如,在机器人抓取中,可以利用新视角合成技术生成不同视角的物体图像,帮助机器人更好地识别和抓取物体。在增强现实和虚拟现实中,可以利用新视角合成技术生成更逼真的虚拟物体,提升用户体验。
📄 摘要(原文)
We propose NVS-HO, the first benchmark designed for novel view synthesis of handheld objects in real-world environments using only RGB inputs. Each object is recorded in two complementary RGB sequences: (1) a handheld sequence, where the object is manipulated in front of a static camera, and (2) a board sequence, where the object is fixed on a ChArUco board to provide accurate camera poses via marker detection. The goal of NVS-HO is to learn a NVS model that captures the full appearance of an object from (1), whereas (2) provides the ground-truth images used for evaluation. To establish baselines, we consider both a classical SfM pipeline and a state-of-the-art pre-trained feed-forward neural network (VGGT) as pose estimators, and train NVS models based on NeRF and Gaussian Splatting. Our experiments reveal significant performance gaps in current methods under unconstrained handheld conditions, highlighting the need for more robust approaches. NVS-HO thus offers a challenging real-world benchmark to drive progress in RGB-based novel view synthesis of handheld objects.