Allocentric Perceiver: Disentangling Allocentric Reasoning from Egocentric Visual Priors via Frame Instantiation
作者: Hengyi Wang, Ruiqiang Zhang, Chang Liu, Guanjie Wang, Zehua Ma, Han Fang, Weiming Zhang
分类: cs.CV, cs.AI
发布日期: 2026-02-05
💡 一句话要点
Allocentric Perceiver:通过帧实例化解耦以自我为中心的视觉先验知识和以场景为中心的推理
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction)
关键词: 以场景为中心感知 视觉-语言模型 空间推理 几何重建 参考系实例化
📋 核心要点
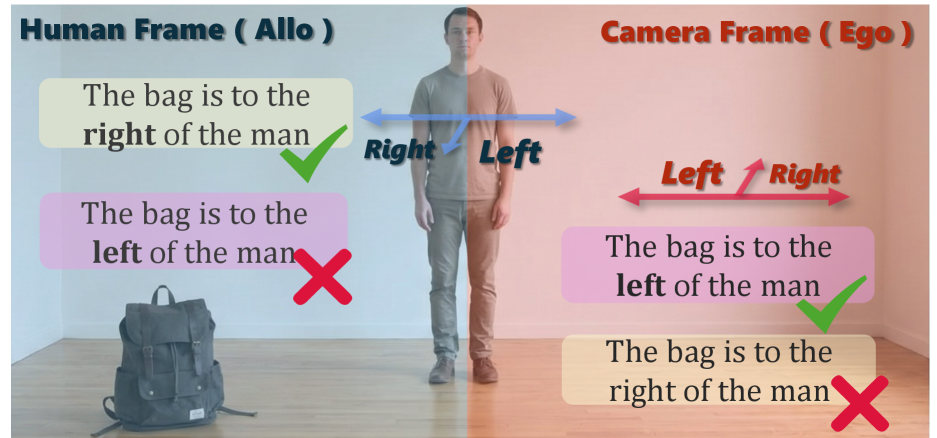
- 现有VLM在处理需要视角转换的以场景为中心的空间推理任务时表现不佳,缺乏明确的坐标系转换能力。
- Allocentric Perceiver通过几何专家重建3D场景,并实例化与指令语义对齐的以场景为中心的参考系,实现显式坐标系转换。
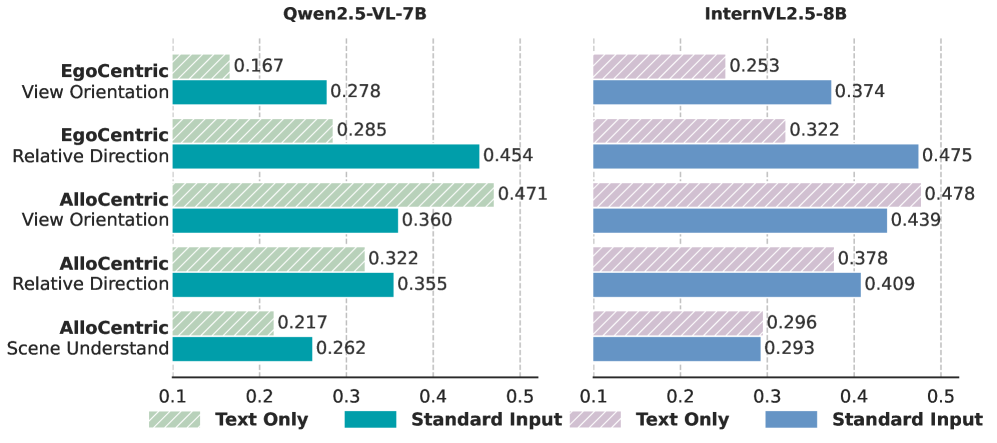
- 实验表明,Allocentric Perceiver在以场景为中心的任务上性能提升约10%,同时保持了良好的以自我为中心的性能。
📝 摘要(中文)
随着视觉-语言模型(VLM)对空间定位任务(如视觉-语言导航/动作)的需求日益增长,以场景为中心的感知能力越来越受到关注。然而,VLM在需要显式视角转换的以场景为中心的空间查询上仍然表现脆弱,因为答案取决于以目标为中心的坐标系中的推理,而不是观察到的相机视角。因此,我们引入了Allocentric Perceiver,这是一种无需训练的策略,它利用现成的几何专家从一个或多个图像中恢复度量3D状态,然后实例化一个以查询为条件的、与指令语义意图对齐的以场景为中心的参考系。通过将重建的几何体确定性地转换到目标坐标系中,并使用结构化的、几何体接地的表示来提示骨干VLM,Allocentric Perceiver将心智旋转从隐式推理转移到显式计算。我们在空间推理基准测试中跨多个骨干网络系列评估了Allocentric Perceiver,观察到在以场景为中心的任务上持续且显著的收益(约10%),同时保持了强大的以自我为中心的性能,并超越了空间感知微调模型以及最先进的开源和专有模型。
🔬 方法详解
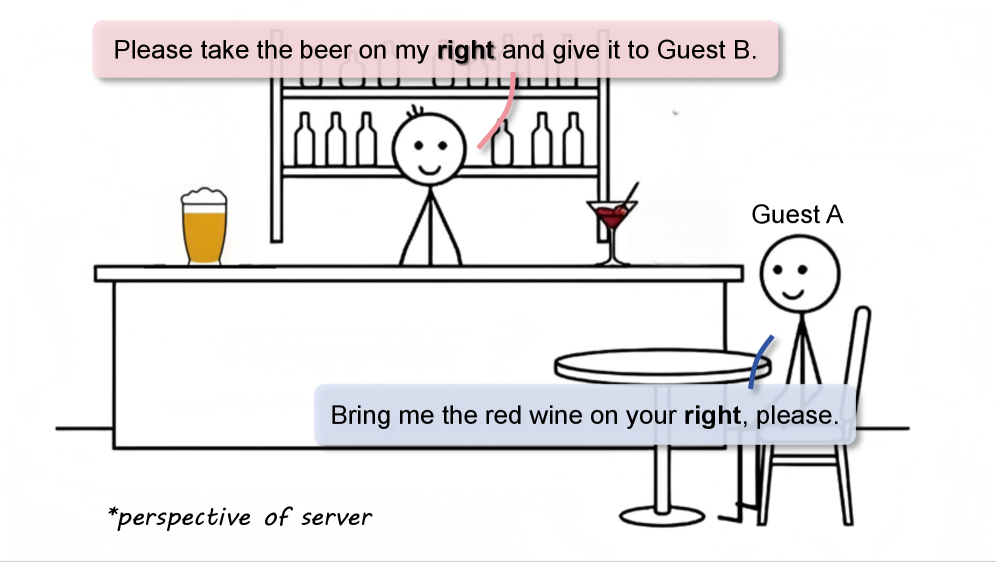
问题定义:现有的视觉-语言模型(VLMs)在处理需要进行视角转换的以场景为中心的空间推理任务时表现出明显的局限性。这些任务要求模型理解并推理相对于场景中特定目标的位置关系,而不仅仅是从观察者的角度进行感知。现有的VLM通常依赖于隐式的视觉先验知识,缺乏明确的坐标系转换能力,导致在需要进行“心智旋转”的任务中表现不佳。
核心思路:Allocentric Perceiver的核心思路是将隐式的空间推理过程显式化。它通过引入几何专家来重建场景的3D结构,并根据指令的语义意图,实例化一个以目标为中心的参考系。这样,模型就可以将重建的几何信息转换到目标参考系中,从而避免了直接从图像中进行复杂的空间推理。这种方法将“心智旋转”从隐式推理转移到显式计算,提高了模型的准确性和可解释性。
技术框架:Allocentric Perceiver的整体框架包括以下几个主要阶段:1) 3D场景重建:利用现成的几何专家(如Structure-from-Motion或SLAM)从一个或多个图像中恢复场景的度量3D状态。2) 参考系实例化:根据指令的语义意图,确定目标对象,并实例化一个以该目标为中心的参考系。3) 几何体转换:将重建的3D几何信息转换到目标参考系中。4) VLM提示:使用结构化的、几何体接地的表示(例如,点云、体素)来提示骨干VLM,使其能够基于显式的几何信息进行推理。
关键创新:Allocentric Perceiver最重要的技术创新点在于它将以场景为中心的推理过程显式化。与以往依赖于隐式视觉先验知识的方法不同,Allocentric Perceiver通过几何重建和参考系实例化,将空间推理问题转化为一个明确的几何变换问题。这种方法不仅提高了模型的准确性,还使其更具可解释性和鲁棒性。
关键设计:Allocentric Perceiver的关键设计包括:1) 几何专家的选择:论文使用了现成的几何专家,这意味着该方法可以灵活地选择不同的几何重建算法,以适应不同的场景和数据。2) 参考系实例化策略:论文根据指令的语义意图来确定目标对象,并实例化参考系。这种策略确保了参考系与任务相关,从而提高了推理的效率。3) VLM提示方式:论文使用了结构化的、几何体接地的表示来提示VLM。这种表示方式能够有效地将几何信息传递给VLM,使其能够更好地进行推理。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Allocentric Perceiver在以场景为中心的空间推理任务上取得了显著的性能提升,平均提升约10%。与经过空间感知微调的模型以及最先进的开源和专有模型相比,Allocentric Perceiver表现出更强的竞争力。此外,Allocentric Perceiver在保持强大的以自我为中心的性能的同时,显著提高了以场景为中心的性能,证明了其有效性和通用性。
🎯 应用场景
Allocentric Perceiver具有广泛的应用前景,例如在机器人导航、自动驾驶、增强现实和虚拟现实等领域。它可以帮助机器人更好地理解周围环境,并根据指令进行导航和操作。在自动驾驶领域,它可以提高车辆对复杂场景的理解能力,从而提高驾驶安全性。在AR/VR领域,它可以增强用户与虚拟环境的交互体验,使其更加自然和直观。
📄 摘要(原文)
With the rising need for spatially grounded tasks such as Vision-Language Navigation/Action, allocentric perception capabilities in Vision-Language Models (VLMs) are receiving growing focus. However, VLMs remain brittle on allocentric spatial queries that require explicit perspective shifts, where the answer depends on reasoning in a target-centric frame rather than the observed camera view. Thus, we introduce Allocentric Perceiver, a training-free strategy that recovers metric 3D states from one or more images with off-the-shelf geometric experts, and then instantiates a query-conditioned allocentric reference frame aligned with the instruction's semantic intent. By deterministically transforming reconstructed geometry into the target frame and prompting the backbone VLM with structured, geometry-grounded representations, Allocentric Perceriver offloads mental rotation from implicit reasoning to explicit computation. We evaluate Allocentric Perciver across multiple backbone families on spatial reasoning benchmarks, observing consistent and substantial gains ($\sim$10%) on allocentric tasks while maintaining strong egocentric performance, and surpassing both spatial-perception-finetuned models and state-of-the-art open-source and proprietary models.